本文主要是介绍Linux进程详解二:创建、状态、进程排队,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 进程创建
- 进程状态
- 进程排队
进程创建
pid_t fork(void)- 创建一个子进程
- 成功将子进程的pid返回给父进程,0返回给新创建的子进程

fork之后有两个执行分支(父和子),fork之后代码共享
bash -> 父 -> 子
创建一个进程时,操作系统会先构建pcb内核数据结构,再将代码和数据进行加载。
创建子进程时,我们一般想让父进程与子进程做不同的事情。
通过下面的控制,可以将父进程和子进程执行不同的代码块。
pid_ id = fork();
if(id < 0)
{return 0;
}
else if(id == 0)
{//子进程进入执行
}
else
{//父进程进入执行
}
代码共享
进程 = 内核数据结构 + 可执行程序的代码和数据
每个进程都存在task_struct和其相对应的加载到内存中的代码和数据,当父进程开始运行的时候,父进程存在一个task_struct和代码数据,此时父进程通过fork创建了一个子进程,当子进程创建成功的时候,系统自动为子进程分配了一个task_struct,但是子进程没有其相对应的代码和数据,所以子进程只能使用父进程对应的代码和数据。
子进程pcb中的大部分属性都继承于父进程。
子进程被创建的时候,是以父进程为模板的。
fork返回值
因为父子关系中,父亲只能有一个,而儿子可以有多个,对于儿子来说,他的父亲是唯一存在的,所有用儿子找父亲很明确。但是对于父亲而言,父亲可以存在多个儿子,当父亲去寻找儿子的时候是不明确的,所以当使用fork进行子进程的创建的时候,将新创建的子进程的pid交给父亲,让父亲知道哪个进程是他的儿子,而不需要将父进程的pid交给子进程,因为父进程对子进程是唯一的,所以fork向子进程返回0。
当父进程中过的代码执行到fork的时候,进入fork的内部函数中,fork的内部函数中首先创建一个子进程然后将父进程的部分属性继承到新创建的子进程中,将父进程对应的代码数据与子进程进行共享,此时子进程已经创建完成了,但是fork函数还没有执行完成,fork需要进行return返回,此时父进程和子进程已经同时存在了,所以fork的return被执行了两次,一次在父进程中,一次在子进程中。所以fork函数会返回两次。
任何进程之间都是具有独立性的,互相不会进行影响。
写时拷贝
当父子进程任何一方想要对数据进行修改的时候,操作系统会对需要进行修改的数据,重新进行拷贝一份,父和子各指向一份这个数据,这个过程称为写时拷贝。
据此,在Linux中可以用同一个变量名表示不同的内存空间。
杀掉进程
kill -9 pid
exit(0) 让进程直接结束
进程状态
进程排队
队列
进程 = task_struct + 可执行程序的代码和数据
进程不是一直在运行的,它可能在等待某种软硬件资源,进程即使加载到cpu中,也不是一直会运行的。
时间片
进程排队,一定是进程在等待某种资源。
进程排队,一定是tast_struct在进行排队。
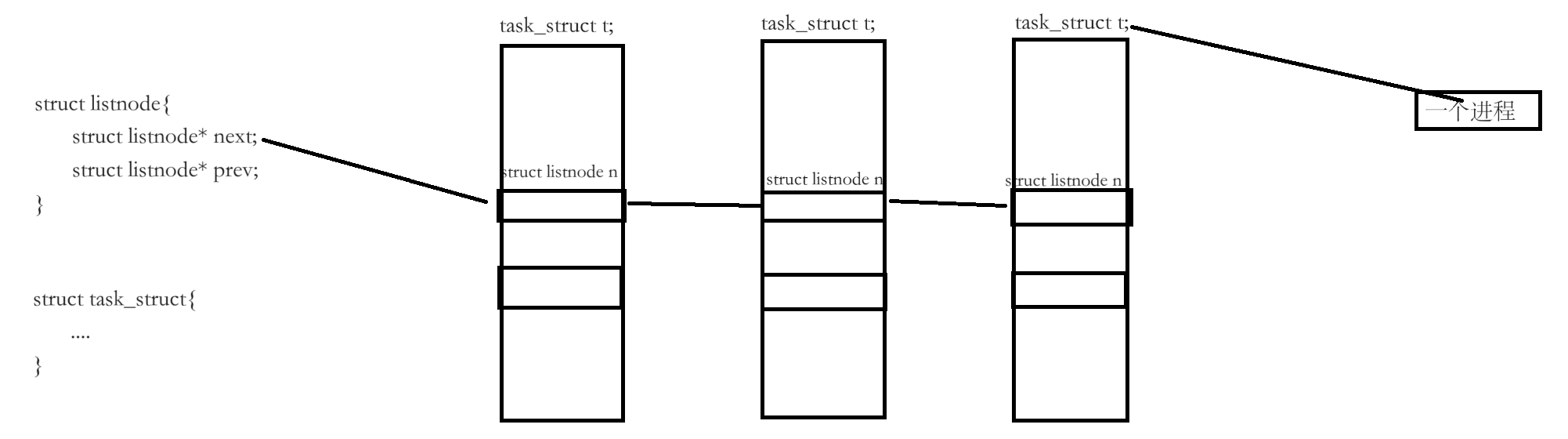
一个task_struct可以被链入多种数据结构中。
一个pcb中可以存在多种数据结构结点,所以一个pcb可以同时在多种数据结构中进行排队。
偏移量:&((task_struct*)0->n)
当前进程pcb的首地址
(task_struct*)(&n - &((task_struct*)0->n)
这篇关于Linux进程详解二:创建、状态、进程排队的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







