本文主要是介绍在 AWS EKS 中通过对 ClickHouse Pod 进行分箱来节省数百万美元,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文字数:5025;估计阅读时间:13 分钟
作者:Vinay Suryadevara & Jianfei Hu
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

介绍
在 ClickHouse Cloud,我们热爱 Kubernetes,并在 Kubernetes 中运行客户 ClickHouse 的集群(servers和keepers)。我们使用 Elastic Kubernetes Service(EKS)来托管在 AWS 中的 ClickHouse 集群。来自不同 ClickHouse 集群的服务器 pod 可以被调度到同一个 EKS 节点上。我们使用 Kubernetes 命名空间 + Cilium 进行隔离。随着为了支持我们的客户而在新区域中部署 EKS 集群,我们的机群规模正在显著增长,EC2 实例的基础设施成本也在增加。
为了优化成本,我们分析了 EKS 节点利用率。EC2 实例按小时计费,而不是基于使用情况,因此低利用率的节点/机群意味着我们正在损失利润。通过提高利用率和减少所需的 EC2 节点总数来降低成本。请继续阅读本文,了解我们如何改进 pod 分配并节省了数百万美元。
评估 EKS 节点利用率
为了使我们的资源消耗尽可能高效,我们进行了一项测试,以确定我们的 pod 是如何分配的。我们分析了我们的 EKS 集群节点的 CPU/内存利用率。下面的截图来自 eks-node-viewer,这是一个可视化 EKS 资源利用率的工具。

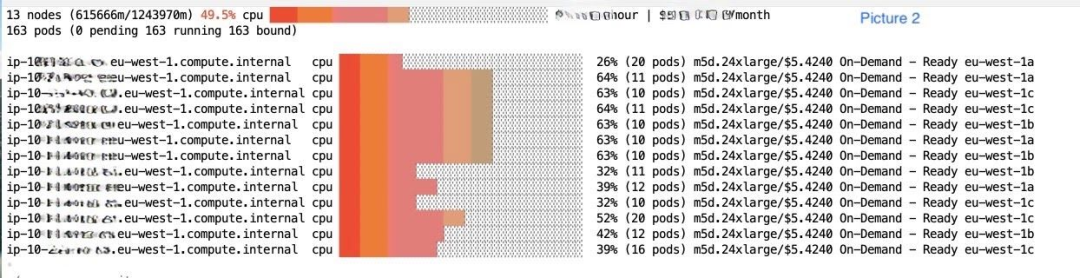
图片 1 显示了我们一个较大的 EKS 集群中的 CPU 利用率百分比。整个集群的 CPU 利用率约为 50%。此外,许多大型和昂贵的节点(如图片 2 所示)未被充分利用。根据我们集群的 eks-node-viewer 结果,我们得出结论,服务器 pod 在节点之间没有被稠密地分配。本应安排在同一节点上的两个 ClickHouse pod 却被安排在不同的节点上,导致我们需要更多的 EC2 节点来承载相同数量的 pod,节点的资源利用率降低,并且机群成本更高。我们集群中的许多节点上的 CPU/内存资源大多处于空闲状态,但我们仍在为这些节点付费。
根本原因分析
经过一些调查,我们确定了低利用率的根本原因。
-
Kubernetes 默认调度器在将待处理的 pod 调度到可用节点上时,使用 LeastAllocated 评分策略对节点进行评分。LeastAllocated 评分策略更喜欢具有更多可用资源的节点,这导致集群节点上的 pod 分布稀疏。
-
这种 LeastAllocated 评分策略使节点规模缩小的可能性非常小。
想象一下,在一个节点上终止了一个旧的 pod。然后调度器将首选该节点来安排新的 pod。因此,节点利用率很难降到集群自动扩展器的阈值以下,以便被回收利用。
与此同时,我们还对新解决方案提出了三个额外的要求和约束:
-
提高我们机群中的资源(CPU/内存)利用率(减少我们的 EC2 占用面积和成本)。
-
不影响客户体验,比如增加 ClickHouse 实例的配置时间。
-
尽量减少对我们客户正在运行的实例的干扰。
考虑到这些因素,我们探讨了几种潜在的解决方案。
调整集群自动扩展器和过度配置(已放弃)
一个显然的方法是调整集群自动扩展器的缩减阈值。但是,这意味着更多的客户 pod 会经常被驱逐,这不符合要求 #3(对客户查询的干扰)。
我们还曾短暂考虑通过调整资源请求和限制来过度配置节点。然而,过度配置资源可能会导致争用。但无论是 CPU 争用(查询被限制)还是内存争用(可能会被 OOM 杀死),都不符合我们客户体验的要求。
主动对 pod 进行分箱(已放弃)
我们还考虑为 ClickHouse pod 添加注释 cluster-autoscaler.kubernetes.io/safe-to-evict。这允许 Kubernetes 集群自动扩展器在节点利用率低于某个阈值时驱逐 pod。但是,pod 驱逐可能会给我们的客户带来干扰。例如,长时间运行的查询将被中断。
我们已经为 ClickHouse 服务器配置了 PodDisruptionBudget,以限制在任何时候 StatefulSet 中的一个 pod 不可用。但根据我们的经验,让集群自动扩展器在随机时间终止一些 pod 对于像 ClickHouse 这样的有状态工作负载来说仍然会产生太多干扰。
因此,我们决定不选择这种方法。
使用 MostAllocated 评分策略对 pod 进行分箱
相反,我们决定将 kube-scheduler(默认的 Kubernetes 调度器)评分策略从 LeastAllocated 更改为 MostAllocated,以更有效地打包我们的集群。这个解决方案为我们的 pod 实现了分箱范式。这有什么帮助?
-
当需要创建新的 pod 时,调度器现在更倾向于具有更高利用率比例的节点。这使得集群的整体利用率随着时间的推移而提高。
-
当旧的 pod 在一个节点上终止时,该节点不太可能被考虑,因此更有可能达到低利用率阈值。最终,集群自动扩展器可以将此节点从集群中移除,从而降低总成本。
此策略是 NodeResourcesFit 插件的一部分,默认在 Kubernetes 中启用。一旦启用了此设置,在 pod 调度阶段,Kubernetes 调度器执行以下操作:
-
首先,它识别出集群中具有根据 pod 请求规范指定的资源可用的节点。这是“过滤阶段”。
-
接下来,它将对已过滤的节点按其组合资源利用率(CPU 和内存)进行降序排列。这被称为“评分阶段”。
-
被选择用于 pod 的节点将始终是适合该 pod 并具有最高资源利用率的节点。
有了一个符合我们所有要求的解决方案,我们决定调查如何在 EKS 中指定此调度策略。
EKS 设置支持 kube-scheduler 定制
当我们开始研究如何为 EKS 中的 kube-scheduler 设置此策略时,我们发现 EKS 不支持通过 EKS 设置/配置自定义 kube-scheduler。许多用户已经提出了这个功能请求,但目前从 AWS 方面没有任何迹象表明将来会增加支持。由于我们无法通过 EKS 设置进行此操作,我们选择在我们的 Kubernetes 集群中自己设置一个自定义调度器。
使用 MostAllocated 评分策略的自定义调度器
为了在我们的集群中为 pod 设置一个自定义调度器,我们主要遵循了 Kubernetes 提供的便捷指南。Kubernetes 还允许您创建自己的调度器二进制文件,但在我们的情况下这并不是必要的,因为具有 MostAllocated 评分策略的现有 kube-scheduler 镜像已经满足了我们的要求。为了在我们的集群中创建此调度器,我们采取了以下步骤:
-
构建并将 kube-scheduler 镜像部署到我们的容器注册表中。我们找不到托管此镜像的公共注册表。对于我们来说,维护这个镜像并不理想,但目前没有替代方案。
-
按照指南中提到的方式为调度器创建了一个部署。在 configMap 中,我们提供了评分策略的相关设置 - ‘MostAllocated’,以及在考虑分配时的 CPU/内存权重。configMap 的配置部分如下所示:
profiles:- pluginConfig:- args:apiVersion: kubescheduler.config.k8s.io/v1beta3kind: NodeResourcesFitArgsscoringStrategy:resources:- name: cpuweight: 1- name: memoryweight: 1type: MostAllocatedname: NodeResourcesFitplugins:score:enabled:- name: NodeResourcesFitweight: 1schedulerName: <schedulerName>-
为了确保高可用性,我们选择在自定义调度器部署中定义了三个 pod,并启用了领导选举,以便只有一个 pod 会执行主动调度,另外两个 pod 处于待机状态。
-
我们将这个调度器部署到了我们的集群中,然后通过在 PodSpec 中指定 schedulerName 来更新我们的 pod,以使用这个最优分配的调度器。
通过这种设置,我们可以确保调度的吞吐量与现有的 kube-scheduler 类似,同时在自定义调度器设置中构建了冗余。我们还可以最小化干扰的情况下提高集群资源利用率。
系统实用工作负载
我们的 EKS 集群有一些负责实用工作负载的系统 pod,例如 CoreDNS、ArgoCD、Cilium Cluster Mesh 等。有时,这些 pod 是低利用率节点上唯一剩余的 pod。由于它们使用本地存储,集群自动伸缩器可能无法清理其中一些 pod。这些被占用的节点也无法缩容。
为了解决这个问题,我们对所有这些系统实用工作负载进行了标注,设置 safe-to-evict: true。
过度预留以实现更平滑的扩容
EKS 集群自动伸缩器本身的 pod 也可能阻止节点被回收。对于自动伸缩器,我们选择让其运行在一个较小的节点上,而不是配置 safe-to-evict: true。这样做可以提供更好的稳定性。
在 ClickHouse Cloud 中,我们使用了 EKS 集群自动伸缩器推荐的过度预留工作负载。我们创建了具有类似资源需求但较低优先级类别的工作负载。这种较低的优先级允许对过度预留的 pod 进行逐出,以便 ClickHouse pod 运行。
我们注意到,当过度预留的 pod 使用默认调度器时,而 ClickHouse pod 使用自定义调度器时,抢占功能不起作用。因为每个调度器只会抢占由自己调度的 pod。在这种情况下,集群自动伸缩器也错误地认为不需要扩容。为了解决这个问题并使事情更加一致,我们还让过度预留的 pod 也使用自定义调度器。
测试和部署
为了确保自定义调度器不会导致性能下降,我们还进行了一些 pod 调度压力测试。我们创建了一个作业,连续创建 pod 以供自定义调度器调度。然后,我们杀死了持有租约锁的自定义调度器 pod。我们观察到其他调度器待机 pod 很快接管了任务。pod 调度几乎没有受到影响,并且根据我们的测试结果,调度吞吐量也不成问题。
另一个潜在的风险是增加 pod 冷启动时间。现在集群更加紧凑,理论上,新实例的创建更有可能触发节点组的扩容,以安排待定的 pod。为了观察这一点,我们测量了 P90 和 P99 的冷启动时间以检查影响。我们验证了这种影响可以忽略不计。这可能是因为为容纳 ClickHouse 服务而进行的节点预配不够频繁,无法产生较大的影响。
在最终部署时,我们仍然谨慎行事:
-
我们按区域逐步推出了调度器更改,并从几个小区域开始。
-
在单个区域内,我们首先只更新了较小的 ClickHouse 实例,然后逐渐将此调度器应用于集群中的所有实例。
-
一旦 pod 规范中的 'schedulerName' 字段更新为此自定义调度器,正在运行的 Clickhouse pod 将使用新调度器进行重新调度。由于我们已经配置了具有 pod 中断预算的有状态集以及优雅的关闭(以避免中断正在运行的查询),当调度器更改时,我们的客户实例没有遇到任何中断。经过一次重新调度后,正在运行的 pod 将不会再受到调度器更改的影响,这在某种程度上满足了先前解决方案所不具备的第三个要求。
部署后的集群利用率
由于这些变化的直接结果,集群利用率提高到了 70%。

我们注意到节点数量减少了约 10%,最大的节省来自清理了几个大型的 24xl 节点。与大型节点减少一起,我们在 EC2 成本方面实现了超过 20% 的降低。
最后,我们还与 AWS 成本和使用报告进行了交叉参考,确认了类似金额的节省。
结论
总而言之,通过将 Kubernetes 调度器评分策略更改为 MostAllocated,我们显著降低了 EKS 基础设施成本。我们通过在 EKS 集群中设置自定义调度器(带有 MostAllocated 评分策略的 kube-scheduler 镜像)来实现这一点。这种方法很好地平衡了成本的降低和维护我们客户工作负载的稳定性。我们还彻底对一些可抢占的系统工作负载进行了标注,以确保节点可以及时回收。
对我们来说,该项目的成功是通过降低成本并且不影响客户的可靠性或性能来衡量的。
通过上述变更,我们能够将 EKS 集群的资源利用率提高 20% 到 30%,并且在我们的 EKS 集群中也实现了相应的 EC2 实例成本节省。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求
这篇关于在 AWS EKS 中通过对 ClickHouse Pod 进行分箱来节省数百万美元的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






