本文主要是介绍MySQL同列不同行计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、问题
- 二、导入数据
- 三、利用变量保存前值
- 四、最终解决方案
- 五、小结
一、问题
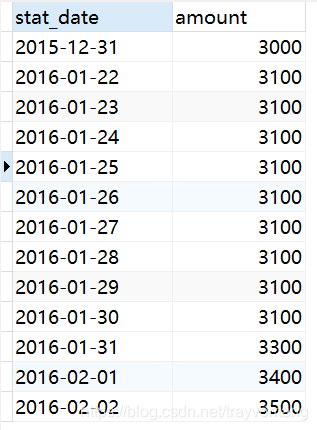
有下面这样的一张表:
| date | amount |
|---|---|
| 2015-12-31 | 3000 |
| 2016-01-22 | 3100 |
| 2016-01-23 | 3100 |
| 2016-01-24 | 3100 |
| 2016-01-25 | 3100 |
| 2016-01-26 | 3100 |
| 2016-01-27 | 3100 |
| 2016-01-28 | 3100 |
| 2016-01-29 | 3100 |
| 2016-01-30 | 3100 |
| 2016-01-31 | 3300 |
| 2016-02-01 | 3400 |
| 2016-02-02 | 3500 |
想要获取像下面这样的结果:
| year | month | diff |
|---|---|---|
| 2016 | 1 | 300 |
| 2016 | 2 | 200 |
写出SQL语句。
从结果可以猜测,就是求每一个月与上一个月的累计值之间差值,其中amount的值是已经是累计值,所以需要再sum计算了。
初一看非常简单,不就是按年和月分组统计吗?
仔细一想其实没有想像中那么容易,最要是要计算行之间的差值,在MySQL中计算列之间的差值非常容易,难点在于要计算行之间的差值,这需要一点小技巧,通过MySQL变量和子查询把列值转换为行值。
注意:对于高并发的业务,我们一般不会把这样的计算放在MySQL中,尽量在应用层处理,或者直接走统计,因为在高并发业务中保护数据库是我们重要的责任。
当然如果仅仅是一些离线的报表或者统计业务当然是没有问题,因为离线报表之类的业务可以用到,所以下面的小技巧还是可以了解一下。
二、导入数据
首先创建表:
CREATE TABLE `stat_year` (`stat_date` date NULL DEFAULT NULL,`amount` int UNSIGNED NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
加载数据,忽略掉第一行表头:
load data local infile 'data.txt' into table amount fields terminated by '\t' ignore 1 lines;
三、利用变量保存前值
我们先来了解一下MySQL在SQL语句中怎样使用变量。
SELECTtmp.stat_date,tmp.current_amount,tmp.pre,( tmp.current_amount - tmp.pre ) AS diff
FROM(SELECTstat_date,amount AS current_amount,@pre_amount AS pre,@pre_amount := sp.amount FROMstat_pay sp,( SELECT @pre_amount := 0 ) AS pre_temp ) AS tmp;
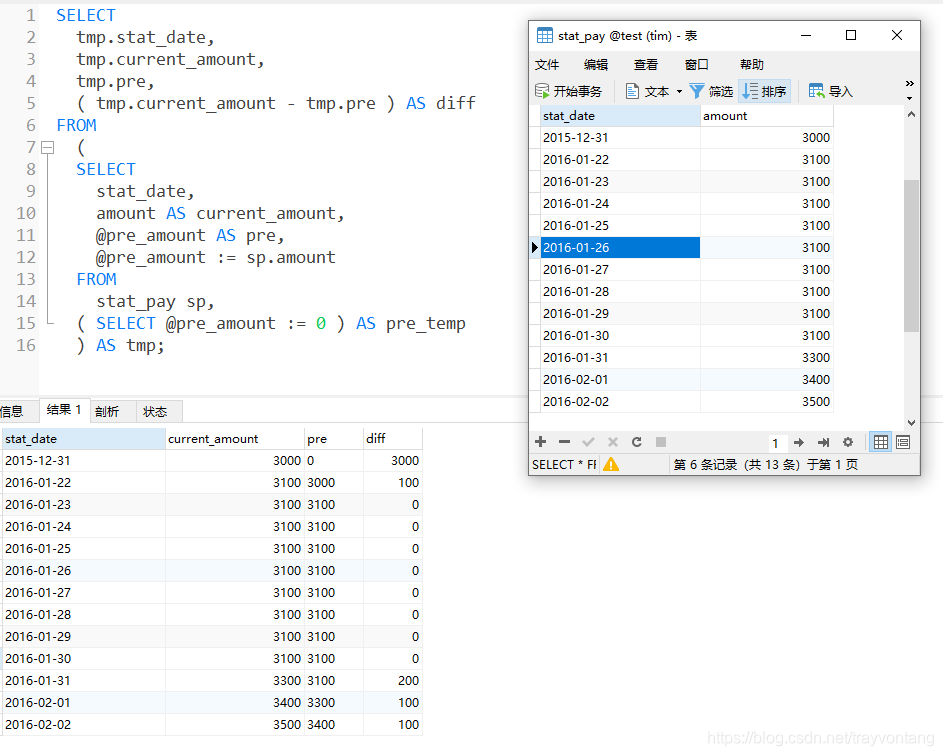
首先,MySQL中用户变量是以@开头,系统变量@@开头,赋值使用的是:=
所以,sql中的
( SELECT @pre_amount := 0 ) AS pre_temp
相当于定义了一个用户变量@pre_amount并且初始化它的值为0。
第一个from语句的子查询部分就相当于没选择一行,先给访问@pre_amount的值做为前值并且给了一个别名pre,然后在将当前行的值赋值给@pre_amount。
现在最外层的查询就容易理解多了,就是查当前行的值,当前行前一行的值,和当前行的值与前行值的差值。
我们来看一下上面的SQL语句的explain结果:
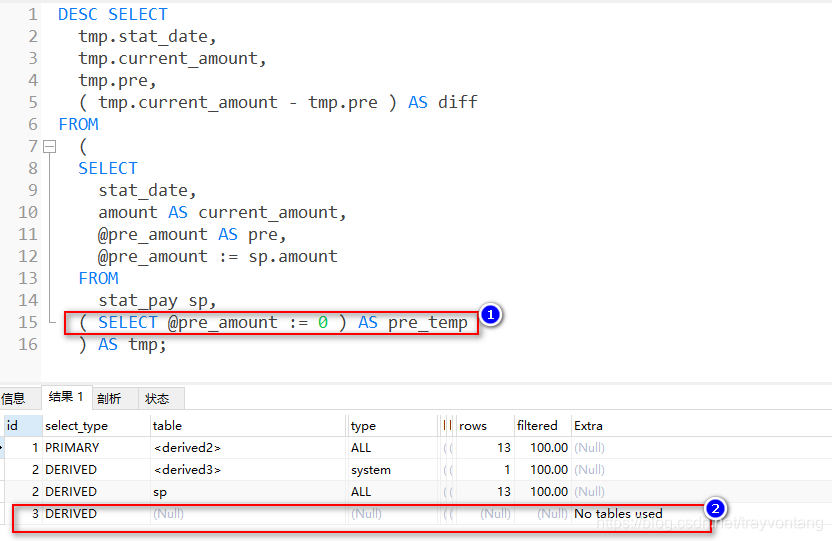
explain的输出说明:
- id是每一个select的标识,id越大优先级越高,越先执行,id相同的从上向下执行
- select_type:PRIMARY表示最后执行的select;DERIVED表示from语句中的子查询
- table表示使用的表,表示使用id为2得到的派生表
现在我们来再来看explain的输出,就清晰多了:
首先找id最大的,id为3的最大,最先执行,我们可以看到select_type是DERIVED,表示它会生成一个派生表,其实就是相当于定义了一个变量@pre_amount放在一张表中,这个表的别名是pre_temp,这个是第2个from语句中的子查询。
id为2的有2个,select_type都是DERIVED,因为这个2个都是第一个from语句中的子查询。
从上往下,我们看到第2行的table是,表示它使用的是id为3的查询生成的派生表,也就是pre_temp这张表。type为system,表示这张表只有1行,从rows也可以看出来。
第3行table是sp表示直接使用了sp这张实际表,sp是stat_pay的别名。
最后id为1的select_type是PRIMARY表示这是最后执行的最外层查询,table是表示使用的表是id为2的查询得到的派生表。
四、最终解决方案
因为要按年、月分组,而我们只有日期,所以我们可以通过substring或者date_format来计算出年和月的值。
SELECT substring(stat_date,1,4) AS stat_year,substring(stat_date,6,2) AS mon FROM stat_pay;
SELECT date_format(stat_date,'%Y') AS stat_year,DATE_FORMAT(stat_date,'%m') AS mon FROM stat_pay;
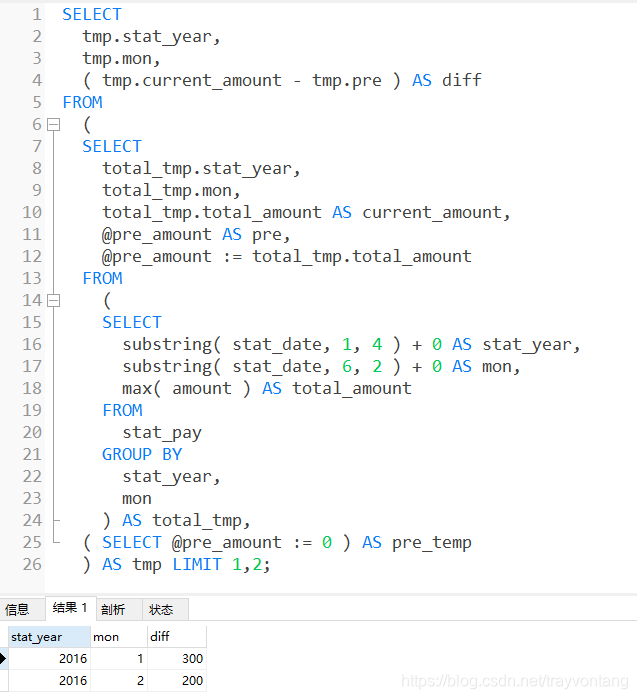
下面我们看一下我们最终的SQL:
SELECTtmp.stat_year,tmp.mon,tmp.current_amount,tmp.pre,( tmp.current_amount - tmp.pre ) AS diff
FROM(SELECTtotal_tmp.stat_year,total_tmp.mon,total_tmp.total_amount AS current_amount,@pre_amount AS pre,@pre_amount := total_tmp.total_amount FROM(SELECTsubstring( stat_date, 1, 4 ) AS stat_year,substring( stat_date, 6, 2 ) AS mon,max( amount ) AS total_amount FROMstat_pay GROUP BYstat_year,mon ) AS total_tmp,( SELECT @pre_amount := 0 ) AS pre_temp ) AS tmp;
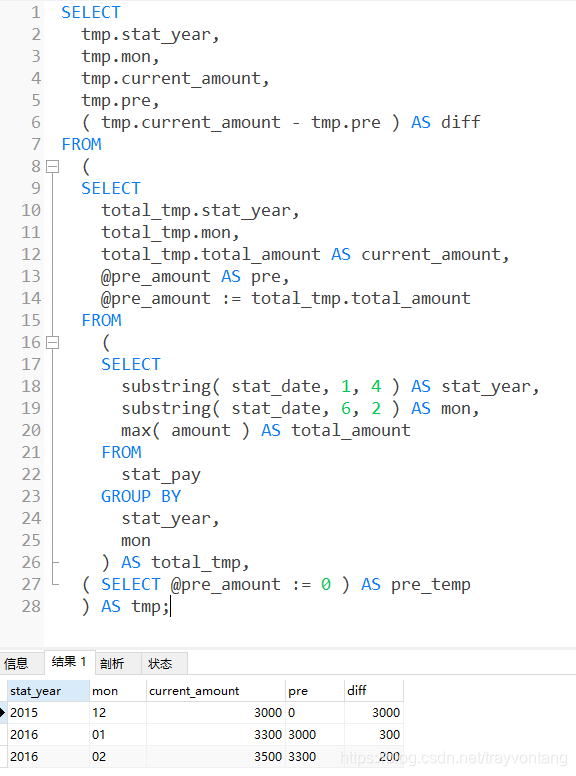
如果你是一个完美主义者,想要结果一模一样,不想年月中有前缀0,可以通过下面的3种方式的任一一种把字符串转换为整型:
substring( stat_date, 1, 4 ) + 0 AS stat_year
convert(substring( stat_date, 6, 2 ),unsigned integer) as stat_year
cast(substring( stat_date, 6, 2 ) as unsigned integer) as stat_year
最后通过limit语句把第一行过滤掉,得到最终结果:
五、小结
我们可以通过在from语句中使用select创建一张派生表来存放一个临时变量,然后在select语句中操作这个变量。
举一反三,我们当然也可以在临时表中存放多个变量,不止是同列之间的计算,完全可以不同列的计算。
这篇关于MySQL同列不同行计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





