本文主要是介绍etcd campaign,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 引言
本文主要讲解使用etcd进行选举的流程,以及对应的缺陷和使用场景
2. etcd选举流程
流程如以代码所示,流程为:
-
clientv3.New
创建client与etcd server建立连接
-
concurrency.NewSession
创建选举的session,一般会配置session的TTL(内部会创建一个lease并进行保活)
-
concurrency.NewElection
创建选举,并指定prefix key
func NewElection(s *Session, pfx string) *Election {return &Election{session: s, keyPrefix: pfx + "/"} } -
e.Campaign
开始选举,并配置选举key的val,一般配置节点名
代码:
cli, err := clientv3.New(clientv3.Config{Endpoints: []string{"172.20.20.55:2379"},DialTimeout: 5 * time.Second,DialKeepAliveTime: 3 * time.Second,DialKeepAliveTimeout: 3 * time.Second,})if err != nil {log.Fatal(err)}defer cli.Close()for {s, err := concurrency.NewSession(cli, concurrency.WithTTL(2))if err != nil {log.Fatal(err)}defer s.Close()e := concurrency.NewElection(s, "/test/election")log.Println("Start campaign", e.Key())if err := e.Campaign(cli.Ctx(), etcdServerIpAndPort); err != nil {log.Fatal(err)}// TODO: send a message indicating that the current node has become the leaderlog.Println("Campaign success, become leader")// determine whether the campaign session is doneselect {case <-s.Done():log.Println("Campaign session done")}}
2.1. 创建Session流程
concurrency.NewSession里的具体实现,参考以下源码,流程:
-
根据参数使用传入的lease,或根据TTL创建lease
ops := &sessionOptions{ttl: defaultSessionTTL, ctx: client.Ctx()}for _, opt := range opts {opt(ops)}id := ops.leaseIDif id == v3.NoLease {resp, err := client.Grant(ops.ctx, int64(ops.ttl))if err != nil {return nil, err}id = v3.LeaseID(resp.ID)} -
client.KeepAlive
对创建的lease进行保活(lease过期,也意味着session失效)
ctx, cancel := context.WithCancel(ops.ctx)keepAlive, err := client.KeepAlive(ctx, id)if err != nil || keepAlive == nil {cancel()return nil, err}client.KeepAlive会返回一个keepAlive channel,如果保活失败,lease过期,此channel会关闭,从而通知调用方Session已失效(如果当前节点为lease,意味着leader失效),参考代码:
donec := make(chan struct{})s := &Session{client: client, opts: ops, id: id, cancel: cancel, donec: donec}// keep the lease alive until client error or cancelled contextgo func() {defer close(donec)for range keepAlive {// eat messages until keep alive channel closes}}()
完整代码:
func NewSession(client *v3.Client, opts ...SessionOption) (*Session, error) {ops := &sessionOptions{ttl: defaultSessionTTL, ctx: client.Ctx()}for _, opt := range opts {opt(ops)}id := ops.leaseIDif id == v3.NoLease {resp, err := client.Grant(ops.ctx, int64(ops.ttl))if err != nil {return nil, err}id = v3.LeaseID(resp.ID)}ctx, cancel := context.WithCancel(ops.ctx)keepAlive, err := client.KeepAlive(ctx, id)if err != nil || keepAlive == nil {cancel()return nil, err}donec := make(chan struct{})s := &Session{client: client, opts: ops, id: id, cancel: cancel, donec: donec}// keep the lease alive until client error or cancelled contextgo func() {defer close(donec)for range keepAlive {// eat messages until keep alive channel closes}}()return s, nil
}
2.1.1. 保活流程
client.KeepAlive内部流程:
-
判断id是否在保活的队列中,参考上一部分,创建session是可以传入一个已存在的lease
- 不存在则创建并加入到l.keepAlives保活队列中
- 存在则将当前创建的channel和ctx加入到keepAlive结构体中
ka, ok := l.keepAlives[id]if !ok {// create fresh keep aliveka = &keepAlive{chs: []chan<- *LeaseKeepAliveResponse{ch},ctxs: []context.Context{ctx},deadline: time.Now().Add(l.firstKeepAliveTimeout),nextKeepAlive: time.Now(),donec: make(chan struct{}),}l.keepAlives[id] = ka} else {// add channel and context to existing keep aliveka.ctxs = append(ka.ctxs, ctx)ka.chs = append(ka.chs, ch)}keepAlive结构体参数描述:
-
chs:当前lease关联的ch列表,若保活失败,则都会关闭,以此通知调用KeepAlive处,进行相应的逻辑处理,如需要处理Session失效。
-
ctxs:保存调用KeepAlive时传入的ctx,若ctx失效,意味着调用方不再需要进行lease保活
-
deadline:当前lease的失效时间,默认值为l.firstKeepAliveTimeout,此值默认为client.cfg.DialTimeout+time.Second,初始化代码如下:
func NewLease(c *Client) Lease {return NewLeaseFromLeaseClient(RetryLeaseClient(c), c, c.cfg.DialTimeout+time.Second) }func NewLeaseFromLeaseClient(remote pb.LeaseClient, c *Client, keepAliveTimeout time.Duration) Lease {l := &lessor{donec: make(chan struct{}),keepAlives: make(map[LeaseID]*keepAlive),remote: remote,firstKeepAliveTimeout: keepAliveTimeout,}if l.firstKeepAliveTimeout == time.Second {l.firstKeepAliveTimeout = defaultTTL}if c != nil {l.callOpts = c.callOpts}reqLeaderCtx := WithRequireLeader(context.Background())l.stopCtx, l.stopCancel = context.WithCancel(reqLeaderCtx)return l } -
donec:lease失效后,用于通知清理l.keepAlives中对应的数据
-
开启协程清理ctx
仅清理ctx对应keepAlive中的ch和ctx
go l.keepAliveCtxCloser(id, ctx, ka.donec)func (l *lessor) keepAliveCtxCloser(id LeaseID, ctx context.Context, donec <-chan struct{}) {select {case <-donec:returncase <-l.donec:returncase <-ctx.Done():}l.mu.Lock()defer l.mu.Unlock()ka, ok := l.keepAlives[id]if !ok {return}// close channel and remove context if still associated with keep alivefor i, c := range ka.ctxs {if c == ctx {close(ka.chs[i])ka.ctxs = append(ka.ctxs[:i], ka.ctxs[i+1:]...)ka.chs = append(ka.chs[:i], ka.chs[i+1:]...)break}}// remove if no one more listenersif len(ka.chs) == 0 {delete(l.keepAlives, id)} } -
开启协程发送保活信息,以及确认lease是否过期
firstKeepAliveOnce为sync.Once类型,多次调用仅会执行一次
l.firstKeepAliveOnce.Do(func() {go l.recvKeepAliveLoop()go l.deadlineLoop()})-
发送以及接收保活信息
func (l *lessor) recvKeepAliveLoop() (gerr error) {defer func() {l.mu.Lock()close(l.donec)l.loopErr = gerrfor _, ka := range l.keepAlives {ka.close()}l.keepAlives = make(map[LeaseID]*keepAlive)l.mu.Unlock()}()for {stream, err := l.resetRecv()if err != nil {if canceledByCaller(l.stopCtx, err) {return err}} else {for {resp, err := stream.Recv()if err != nil {if canceledByCaller(l.stopCtx, err) {return err}if toErr(l.stopCtx, err) == rpctypes.ErrNoLeader {l.closeRequireLeader()}break}l.recvKeepAlive(resp)}}log.Println("resetRecv")select {case <-time.After(retryConnWait):continuecase <-l.stopCtx.Done():return l.stopCtx.Err()}} }-
发送
resetRecv函数中获取一个grpc的stream,并通过此发送保活信息
// resetRecv opens a new lease stream and starts sending keep alive requests. func (l *lessor) resetRecv() (pb.Lease_LeaseKeepAliveClient, error) {sctx, cancel := context.WithCancel(l.stopCtx)stream, err := l.remote.LeaseKeepAlive(sctx, l.callOpts...)if err != nil {cancel()return nil, err}l.mu.Lock()defer l.mu.Unlock()if l.stream != nil && l.streamCancel != nil {l.streamCancel()}l.streamCancel = cancell.stream = streamgo l.sendKeepAliveLoop(stream)return stream, nil }通过sendKeepAliveLoop函数进行保活信息的发送,关键逻辑:
- 遍历l.keepAlives,通过每个keepAlive结构体中的nextKeepAlive来判断是否要发送保活信息(nextKeepAlive数据参考之前讲的初始化和接收保活回复处)
- 每隔0.5秒运行一次,出现错误时直接退出执行
// sendKeepAliveLoop sends keep alive requests for the lifetime of the given stream. func (l *lessor) sendKeepAliveLoop(stream pb.Lease_LeaseKeepAliveClient) {for {var tosend []LeaseIDnow := time.Now()l.mu.Lock()for id, ka := range l.keepAlives {if ka.nextKeepAlive.Before(now) {tosend = append(tosend, id)}}l.mu.Unlock()for _, id := range tosend {r := &pb.LeaseKeepAliveRequest{ID: int64(id)}if err := stream.Send(r); err != nil {// TODO do something with this error?return}}select {case <-time.After(500 * time.Millisecond):case <-stream.Context().Done():log.Println("stream context done")returncase <-l.donec:returncase <-l.stopCtx.Done():return}} } -
接收信息
接收lease保活信息,并进行处理,主要更新nextKeepAlive(下一次发送时间)和deadline
关键逻辑:
- nextKeepAlive为time.Now().Add((time.Duration(karesp.TTL) * time.Second) / 3.0),其中TTL为NewSession时传入的TTL。
- 如果回复中TTL为0,表明lease过期
处理函数如下:
// recvKeepAlive updates a lease based on its LeaseKeepAliveResponse func (l *lessor) recvKeepAlive(resp *pb.LeaseKeepAliveResponse) {karesp := &LeaseKeepAliveResponse{ResponseHeader: resp.GetHeader(),ID: LeaseID(resp.ID),TTL: resp.TTL,}l.mu.Lock()defer l.mu.Unlock()ka, ok := l.keepAlives[karesp.ID]if !ok {return}if karesp.TTL <= 0 {// lease expired; close all keep alive channelsdelete(l.keepAlives, karesp.ID)ka.close()return}// send update to all channelsnextKeepAlive := time.Now().Add((time.Duration(karesp.TTL) * time.Second) / 3.0)ka.deadline = time.Now().Add(time.Duration(karesp.TTL) * time.Second)for _, ch := range ka.chs {select {case ch <- karesp:default:}// still advance in order to rate-limit keep-alive sendska.nextKeepAlive = nextKeepAlive} }
-
-
判断lease是否过期
主要通过deadline进行判断,是否会实时更新。
func (l *lessor) deadlineLoop() {for {select {case <-time.After(time.Second):case <-l.donec:return}now := time.Now()l.mu.Lock()for id, ka := range l.keepAlives {if ka.deadline.Before(now) {// waited too long for response; lease may be expiredka.close()delete(l.keepAlives, id)}}l.mu.Unlock()} }
-
KeepAlive完整代码:
func (l *lessor) KeepAlive(ctx context.Context, id LeaseID) (<-chan *LeaseKeepAliveResponse, error) {ch := make(chan *LeaseKeepAliveResponse, LeaseResponseChSize)l.mu.Lock()// ensure that recvKeepAliveLoop is still runningselect {case <-l.donec:err := l.loopErrl.mu.Unlock()close(ch)return ch, ErrKeepAliveHalted{Reason: err}default:}ka, ok := l.keepAlives[id]if !ok {// create fresh keep aliveka = &keepAlive{chs: []chan<- *LeaseKeepAliveResponse{ch},ctxs: []context.Context{ctx},deadline: time.Now().Add(l.firstKeepAliveTimeout),nextKeepAlive: time.Now(),donec: make(chan struct{}),}l.keepAlives[id] = ka} else {// add channel and context to existing keep aliveka.ctxs = append(ka.ctxs, ctx)ka.chs = append(ka.chs, ch)}l.mu.Unlock()go l.keepAliveCtxCloser(id, ctx, ka.donec)l.firstKeepAliveOnce.Do(func() {go l.recvKeepAliveLoop()go l.deadlineLoop()})return ch, nil
}
keepAlive.close()函数:
关闭所有调用KeepAlive函数返回的channel,此处为通知对应的Session
func (ka *keepAlive) close() {close(ka.donec)for _, ch := range ka.chs {close(ch)}
}
2.1.2. 保活流程总结
-
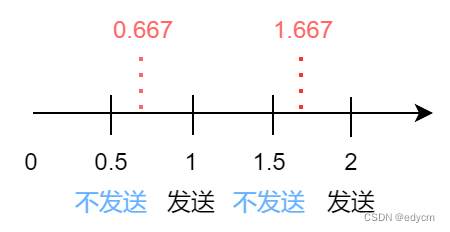
保活消息发送的间隔为创建Session时传入的TTL或者lease的TTL除以3,如TTL为3,则每隔1s发送一次;但是如果TTL为2,并不是每0.667s发送一次,因为执行保活的函数是固定每0.5s执行一次。所以间隔只能是0.5的整数倍,即如果TTL为2,则为1s发送一次保活信息。
-
lease过期也就意味着Session失效
2.2 选举流程
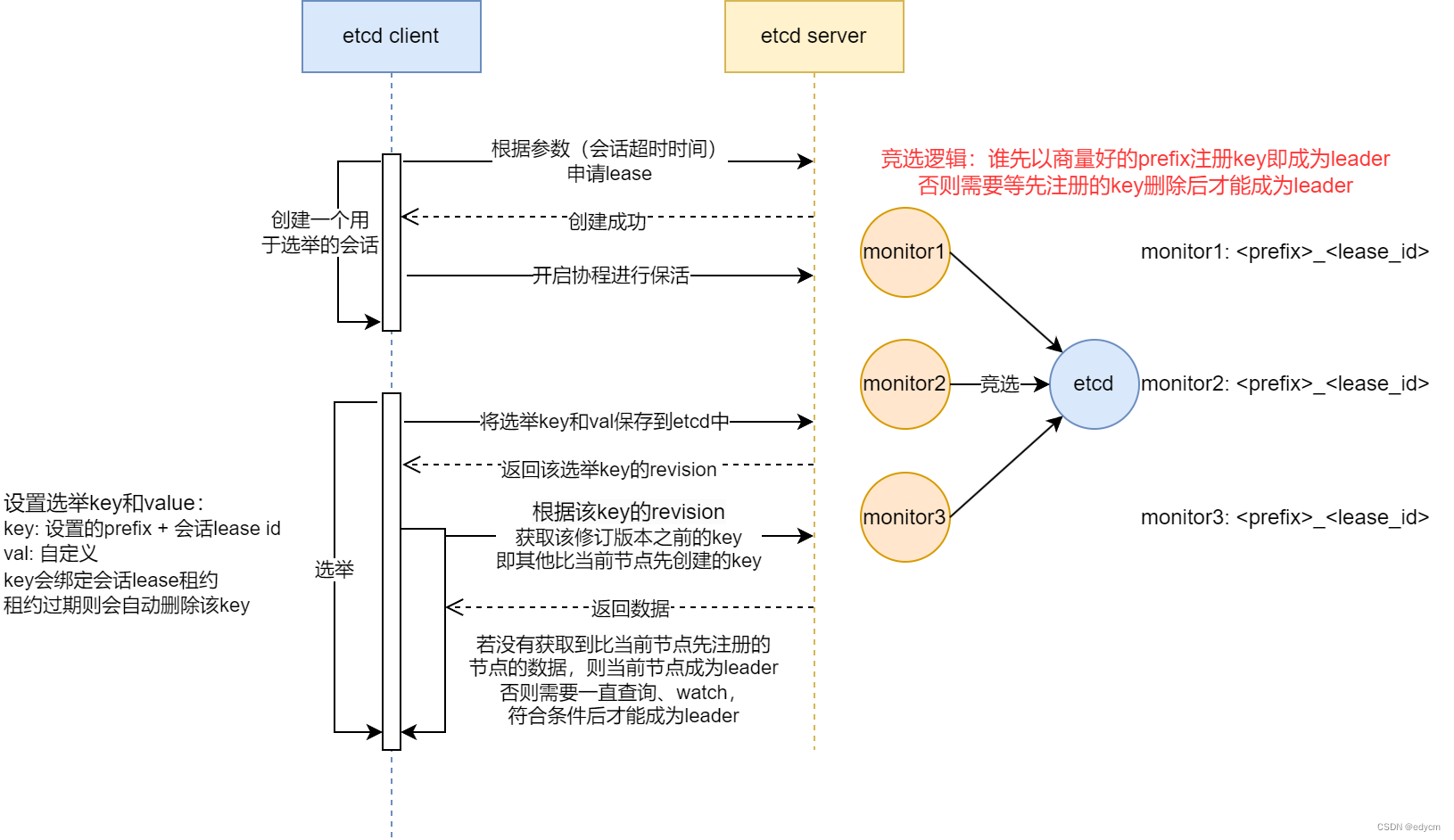
流程:
-
创建一个选举对象
func NewElection(s *Session, pfx string) *Election {return &Election{session: s, keyPrefix: pfx + "/"} } -
进行选举
主要介绍选举的步骤和逻辑:
-
根据keyPrefix(NewElection时传入的)和lease id,组成代表当前节点的key
k := fmt.Sprintf("%s%x", e.keyPrefix, s.Lease()) -
通过事务判断key是否存在
- 存在则获取值
- 如果val与获取值不同,更新val,参考e.Proclaim
- 不存在则插入key和val数据,并绑定对应的Session lease,如果lease过期后,对应的key和val也会被删除
txn := client.Txn(ctx).If(v3.Compare(v3.CreateRevision(k), "=", 0))txn = txn.Then(v3.OpPut(k, val, v3.WithLease(s.Lease())))txn = txn.Else(v3.OpGet(k))resp, err := txn.Commit()if err != nil {return err}e.leaderKey, e.leaderRev, e.leaderSession = k, resp.Header.Revision, sif !resp.Succeeded {kv := resp.Responses[0].GetResponseRange().Kvs[0]e.leaderRev = kv.CreateRevisionif string(kv.Value) != val {if err = e.Proclaim(ctx, val); err != nil {e.Resign(ctx)return err}}}e.Proclaim代码:
func (e *Election) Proclaim(ctx context.Context, val string) error {if e.leaderSession == nil {return ErrElectionNotLeader}client := e.session.Client()cmp := v3.Compare(v3.CreateRevision(e.leaderKey), "=", e.leaderRev)txn := client.Txn(ctx).If(cmp)txn = txn.Then(v3.OpPut(e.leaderKey, val, v3.WithLease(e.leaderSession.Lease())))tresp, terr := txn.Commit()if terr != nil {return terr}if !tresp.Succeeded {e.leaderKey = ""return ErrElectionNotLeader}e.hdr = tresp.Headerreturn nil }如果e.Proclaim更新值失败则删除key,然后Campaign返回错误,下次调用Campaign时继续执行
e.Resign功能为删除相应的选举key,代码:
func (e *Election) Resign(ctx context.Context) (err error) {if e.leaderSession == nil {return nil}client := e.session.Client()cmp := v3.Compare(v3.CreateRevision(e.leaderKey), "=", e.leaderRev)resp, err := client.Txn(ctx).If(cmp).Then(v3.OpDelete(e.leaderKey)).Commit()if err == nil {e.hdr = resp.Header}e.leaderKey = ""e.leaderSession = nilreturn err } - 存在则获取值
-
根据e.keyPrefix和e.leaderRev(上一步骤中key存入etcd server时的Revision),等待在此Revision之前创建的,具有相同prefix的key被删除
_, err = waitDeletes(ctx, client, e.keyPrefix, e.leaderRev-1)if err != nil {// clean up in case of context cancelselect {case <-ctx.Done():e.Resign(client.Ctx())default:e.leaderSession = nil}return err}waitDeletes逻辑:
- 通过client.Get()获取指定前缀、指定最大创建Revision的最后一条key。即与当前选举key含有相同的prefix的,上一条数据,也可以理解为获取比当前节点先插入选举key、val的其它节点的key和val
- 获取到数据,表明其它节点先创建了key,需要等待其过期,通过waitDelete watch keyPrefix的每个删除操作;watch到相应的删除事件,则重新调用client.Get(),判断是否需要继续等待
- 没有获取到,表明没有其它节点先创建了key,自身可以成为leader,直接返回
waitDeletes代码:
func waitDeletes(ctx context.Context, client *v3.Client, pfx string, maxCreateRev int64) (*pb.ResponseHeader, error) {getOpts := append(v3.WithLastCreate(), v3.WithMaxCreateRev(maxCreateRev))for {resp, err := client.Get(ctx, pfx, getOpts...)if err != nil {return nil, err}if len(resp.Kvs) == 0 {return resp.Header, nil}lastKey := string(resp.Kvs[0].Key)if err = waitDelete(ctx, client, lastKey, resp.Header.Revision); err != nil {return nil, err}} }waitDelete代码:
func waitDelete(ctx context.Context, client *v3.Client, key string, rev int64) error {cctx, cancel := context.WithCancel(ctx)defer cancel()var wr v3.WatchResponsewch := client.Watch(cctx, key, v3.WithRev(rev))for wr = range wch {for _, ev := range wr.Events {if ev.Type == mvccpb.DELETE {return nil}}}if err := wr.Err(); err != nil {return err}if err := ctx.Err(); err != nil {return err}return fmt.Errorf("lost watcher waiting for delete") } - 通过client.Get()获取指定前缀、指定最大创建Revision的最后一条key。即与当前选举key含有相同的prefix的,上一条数据,也可以理解为获取比当前节点先插入选举key、val的其它节点的key和val
Campaign完整代码:
func (e *Election) Campaign(ctx context.Context, val string) error {s := e.sessionclient := e.session.Client()k := fmt.Sprintf("%s%x", e.keyPrefix, s.Lease())txn := client.Txn(ctx).If(v3.Compare(v3.CreateRevision(k), "=", 0))txn = txn.Then(v3.OpPut(k, val, v3.WithLease(s.Lease())))txn = txn.Else(v3.OpGet(k))resp, err := txn.Commit()if err != nil {return err}e.leaderKey, e.leaderRev, e.leaderSession = k, resp.Header.Revision, sif !resp.Succeeded {kv := resp.Responses[0].GetResponseRange().Kvs[0]e.leaderRev = kv.CreateRevisionif string(kv.Value) != val {if err = e.Proclaim(ctx, val); err != nil {e.Resign(ctx)return err}}}_, err = waitDeletes(ctx, client, e.keyPrefix, e.leaderRev-1)if err != nil {// clean up in case of context cancelselect {case <-ctx.Done():e.Resign(client.Ctx())default:e.leaderSession = nil}return err}e.hdr = resp.Headerreturn nil
}
2.3.1. 选举流程总结
- 选举本质上为先到先得,是一个FIFO的队列,后来的需要等待前边的释放,而前边的释放时间则取决于设置的Session TTL,在lease过期,由etcd server删除对应的key后,下一个才可成为leader
3. 缺陷和使用场景
由上一章节描述的,当前节点要成为leder,需要等etcd server删除比当前节点先写入的其它节点的key和val。
如此意味着如果上一个节点故障后,需要等待上一个节点的Session TTL时间,下一个节点才会变为leader。而在此期间,如果etcd server发生故障,则这个时间还会延长。
3.1. etcd lease TTL测试
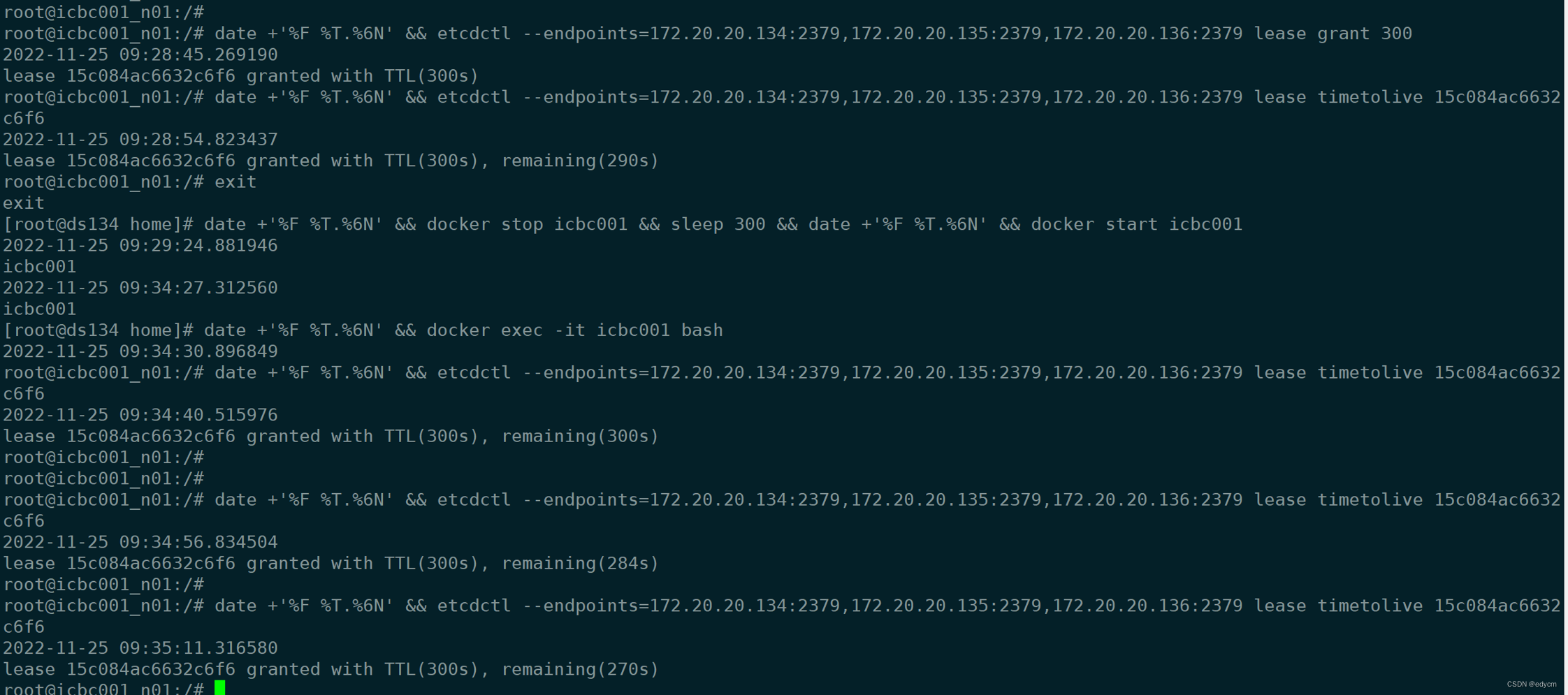
测试1:
测试流程:设置一个300s后超时的lease,关闭节点(etcd停止运行,etcd为单节点),300s后重启,发现该lease没有过期
结论:etcd停止服务后,lease的TTL会重置,且lease不会过期
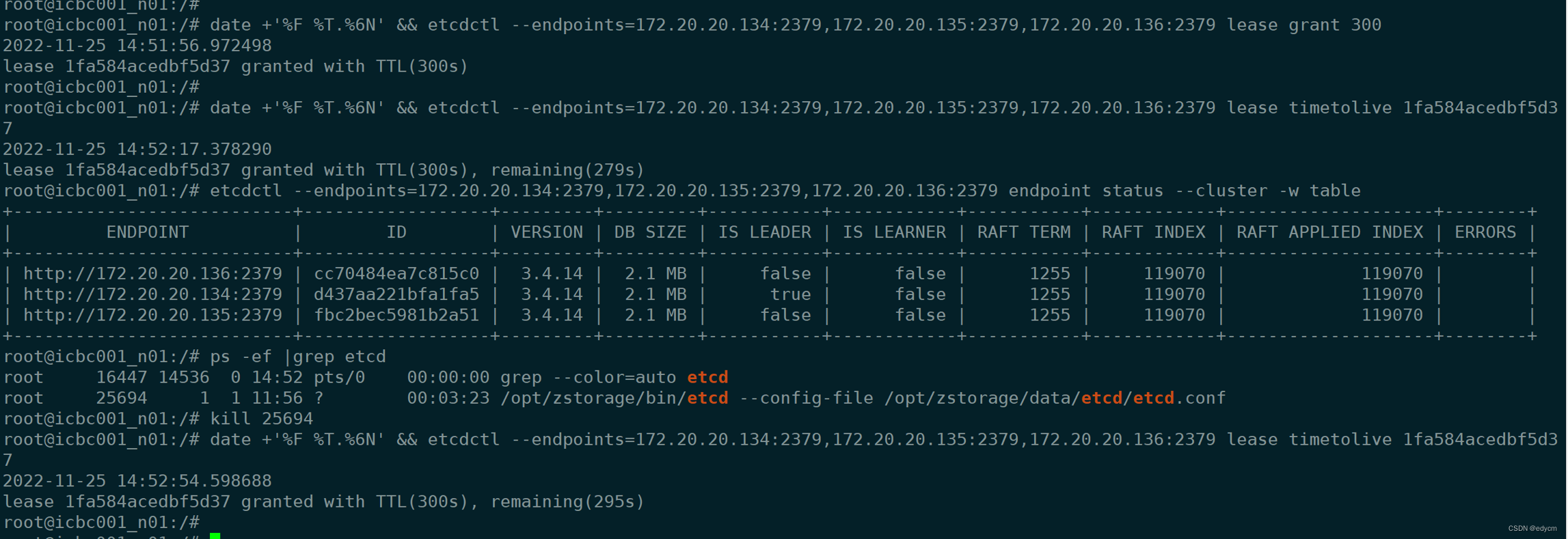
测试2:
测试步骤:生成一个300s的lease,20s之后,kill掉etcd的leader,使etcd切主,然后查询该lease的剩余时间,结果为295s
结论:etcd切主后会重置lease的TTL
3.2 缺陷总结
通过上一部分中的测试,可以发现当etcd发生切主或重启(单节点)后,TTL会重置,也就是说当使用etcd进行选举的客户端发生故障后,在切主的过程中,etcd server也发生故障,则此时间会延长,因为故障节点的lease TTL被重置了,需要重新计算过期时间,这会导致切主时间延长。
使用场景:对切主的时间没有严苛的要求
3.3 使用的注意事项
根据前边的内容介绍,在选举的过程中,如果Session lease超时,Campaign处是感觉不到的,所以当Campaign返回后,需要额外判断Session是否Done了:
for {s, err := concurrency.NewSession(cli, concurrency.WithTTL(2))if err != nil {log.Fatal(err)}defer s.Close()e := concurrency.NewElection(s, "/test/election")log.Println("Start campaign", e.Key())if err := e.Campaign(cli.Ctx(), etcdServerIpAndPort); err != nil {log.Fatal(err)}select {case <-s.Done():log.Println("Campaign session done")continue}// TODO: send a message indicating that the current node has become the leaderlog.Println("Campaign success, become leader")// determine whether the campaign session is doneselect {case <-s.Done():log.Println("Campaign session done")}}
中,如果Session lease超时,Campaign处是感觉不到的,所以当Campaign返回后,需要额外判断Session是否Done了:
for {s, err := concurrency.NewSession(cli, concurrency.WithTTL(2))if err != nil {log.Fatal(err)}defer s.Close()e := concurrency.NewElection(s, "/test/election")log.Println("Start campaign", e.Key())if err := e.Campaign(cli.Ctx(), etcdServerIpAndPort); err != nil {log.Fatal(err)}select {case <-s.Done():log.Println("Campaign session done")continue}// TODO: send a message indicating that the current node has become the leaderlog.Println("Campaign success, become leader")// determine whether the campaign session is doneselect {case <-s.Done():log.Println("Campaign session done")}}
这篇关于etcd campaign的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[etcd]raft总结/选举/数据同步,协议缺陷与解决/Multi Raft](https://i-blog.csdnimg.cn/blog_migrate/d647e80325d7ae7cffcb4081a74b6e75.jpeg)
