本文主要是介绍Linux:常用软件、工具和周边知识介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上次也是结束了权限相关的知识:Linux:权限相关知识详解
文章目录
- 1.`yum`-管理软件包的工具
- 1.1基本介绍
- 1.2yum的使用
- 1.3yum的周边生态
- 1.4软件包介绍
- 2.`vim`-多模式的文本编辑器
- 2.1基本介绍
- 2.2基本模式介绍
- 2.2.1命令模式(Normal mode)
- 2.2.2插入模式(Insert mode)
- 2.2.3底行模式(Command mode)
- 2.3 批量注释和批量删前面的空格
- 批量注释
- 批量删前面的空格
- 3.`gcc/g++` –Linux编译器
- 3.1基本介绍
- 3.2编译过程
- 3.2 动静态库
- 1. 静态库(Static Library):
- 2. 动态库(Dynamic Library):
- 4.make/Makefile –Linux项目自动化构建工具
- 扩展
- 原理
1.yum-管理软件包的工具
1.1基本介绍
Yum(Yellowdog Updater Modified):
Yum是Linux系统中用于管理软件包的工具,类似于手机上的应用商店。是基于 RPM(Red Hat Package Manager)的系统,用于管理 RPM 软件包 ,它提供了一种方便的方式来搜索、下载、安装和卸载软件包,使得软件的管理变得简单而高效。
安装软件的方式:
源代码安装:需要手动下载源代码并进行编译安装,比较繁琐,需要处理依赖关系。
RPM包直接安装:可以直接使用RPM包进行安装,但是需要手动处理依赖关系,不够方便。
Yum(或apt-get):Yum是Linux系统预装的一个命令,也可以通过apt-get在Debian系列的系统中使用。它们提供了一个类似应用商店的方式,通过简单的命令即可搜索、下载、安装和卸载软件包,而且会自动处理依赖关系,非常方便。
注意:
-
yum在安装软件时需要从服务器上下载RPM包,并且在同一时刻只能允许一个yum进程进行安装操作。这是因为yum在安装过程中可能会修改系统的配置和文件,如果同时有多个yum进程进行操作,可能会导致不可预测的结果和系统不稳定性。 -
另外,
yum需要通过网络访问软件源来下载安装软件包
+--------------------------+ +----------------------+| | | || 软件包服务器(软件源) | ---------> | 本地系统、云服务器 || | 下载软件包 | |+--------------------------+ +----------------------+
1.2yum的使用
我们删除,下载时是需要有root权限的。
选项:
-y或--assumeyes:在提示时自动回答"yes"。-q或--quiet:安静模式,减少输出信息
以下是使用yum的常用操作(这里只介绍部分了):
-
更新软件包列表:
sudo yum update这将更新可用软件包的列表,以确保您系统上的所有软件包都是最新的。
-
搜索软件包:
yum search package_name使用此命令搜索特定软件包。例如,如果要搜索Apache软件包,可以使用
yum search apache。 -
安装软件包:
sudo yum install package_name使用此命令安装特定的软件包。例如,要安装Apache服务器,可以使用
yum install httpd。 -
更新软件包:
sudo yum update package_name使用此命令更新特定的软件包。例如,要更新Apache服务器,可以使用
yum update httpd。 -
删除软件包:
sudo yum remove package_name使用此命令删除特定的软件包。例如,要删除Apache服务器,可以使用
yum remove httpd。 -
列出已安装的软件包:
yum list installed使用此命令列出所有已安装的软件包。
-
清理缓存:
sudo yum clean all使用此命令清理Yum缓存,以释放磁盘空间。
1.3yum的周边生态
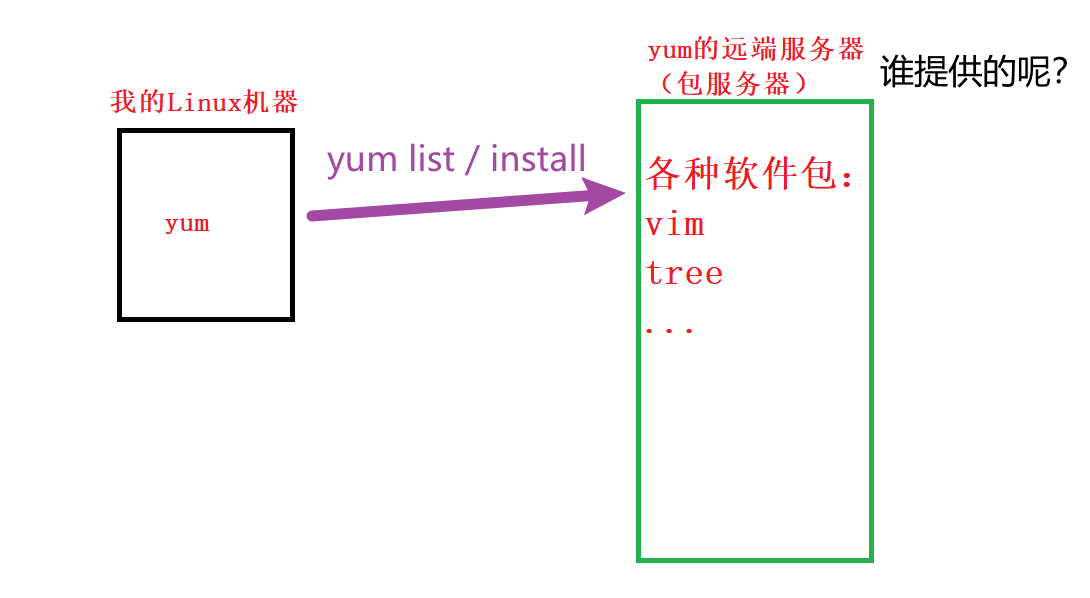
各种各样的软件和包服务器由不同的组织、个人或机构提供。这些服务器可以分为两类:基础软件源和拓展软件源。
- 基础软件源:
- 基础软件源通常由Linux发行版的官方团队或相关组织提供,如Red Hat、CentOS、Debian、Ubuntu等。
- 这些软件源提供了操作系统的核心组件、常用工具和基本服务所需的软件包。
- 它们通常包含了操作系统的核心组件、常用工具和基本服务所需的软件包,以确保系统的稳定性和安全性。
- 拓展软件源:
- 拓展软件源是由第三方组织或社区提供的,如EPEL、RPM Fusion等。
- 这些软件源提供了一些官方软件源中没有的软件包,或者提供了更新版本的软件包,以满足用户更多的需求。
- 它们提供了更多的软件选择和功能扩展,如多媒体编解码器、图形界面工具、开发工具等。
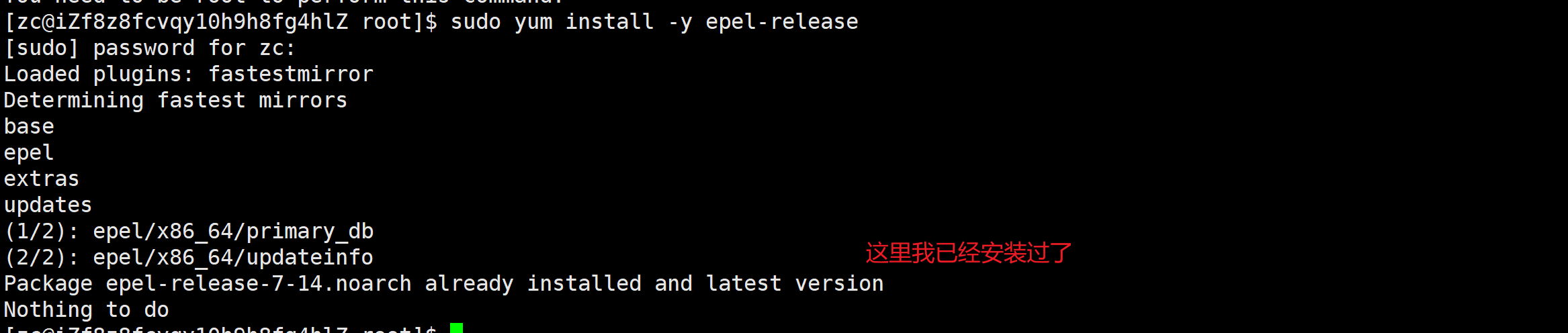
我们可以通过:来安装拓展软件源
yum install -y epel-release
1.4软件包介绍
使用:yum list | grep vim
该命令用于在 yum 软件包列表中查找包含 “vim” 关键字的软件包。这样做可以过滤出与 Vim 相关的软件包信息,使结果更易于阅读和理解。
yum list:列出所有可用的软件包。|:管道符号,将yum list的输出作为grep命令的输入。grep vim:使用 grep 工具搜索包含 “vim” 关键字的行。
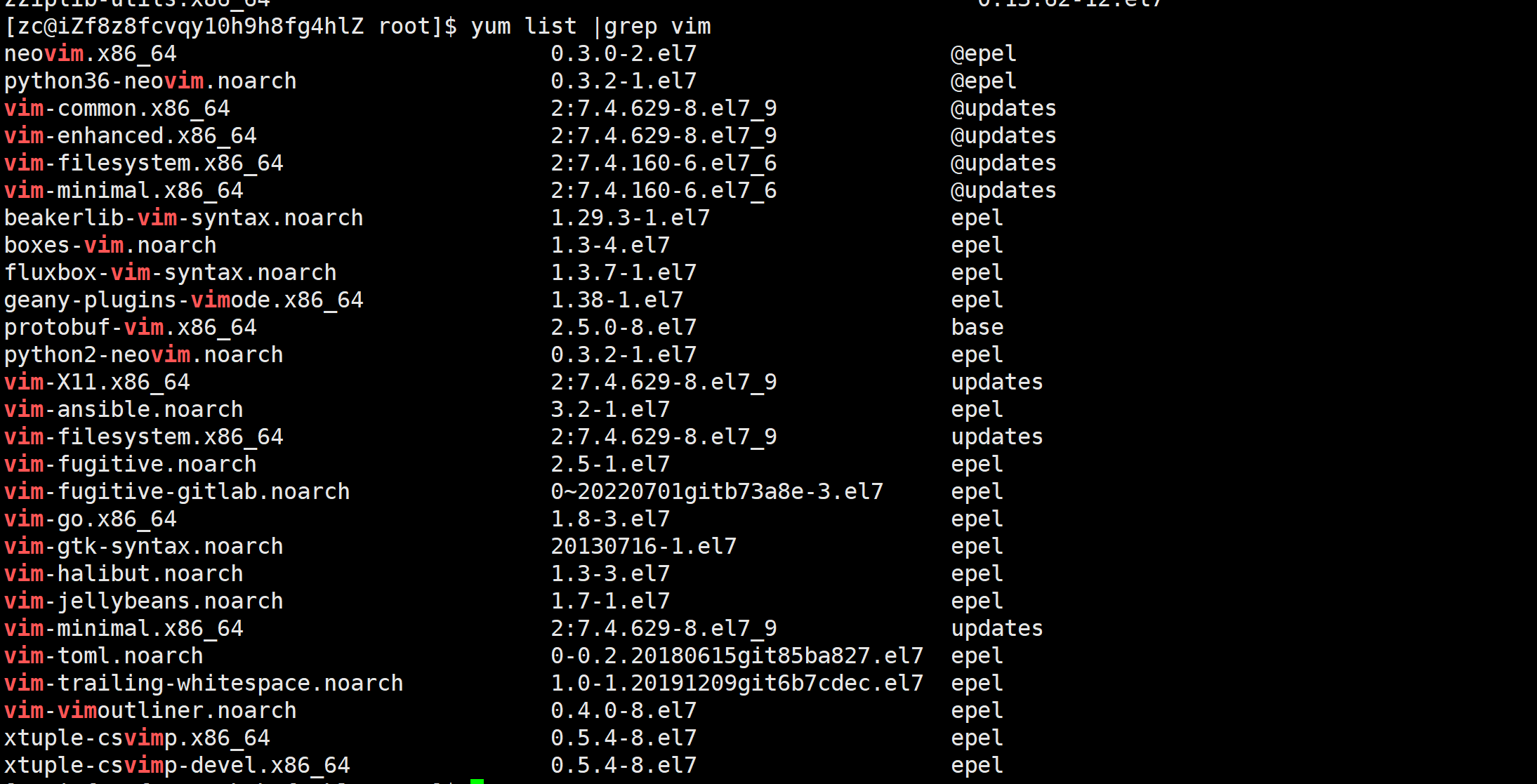
第一列:
软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
x86_64后缀表示64位系统的安装包, “i686” 后缀表示32位系统安装包. 选择包时要和系统匹配第二列:软件包的版本号
第三列:软件包的存储库来源
2.vim-多模式的文本编辑器
2.1基本介绍
vim(Vi IMproved)是一个功能强大的文本编辑器,常用于在终端中编辑文本文件。它是 Unix 系统下的一个经典编辑器,具有丰富的功能和灵活的配置选项
vim 提供了多种编辑模式,包括普通模式、插入模式、命令行模式(进入默认这个)等,让用户可以高效地进行编辑操作
我们使用: vim 文件名 即可直接进入到文件中
- 退出vim及保存文件,在[正常模式]下,按一下「:」冒号键进入「Last line mode」,例如:
-
w (保存当前文件)
-
wq(保存并退出)
2.2基本模式介绍
- 命令模式(Normal mode)
在命令模式下,我们可以控制屏幕光标的移动,字符、字或行的删除,复制粘贴,剪贴等操作。 - 插入模式(Insert mode)
只有在插入模式下才能进行文字输入,该模式是我们使用最频繁的编辑模式。 - 底行模式(Command mode)
在底行模式下,我们可以将文件保存或退出,也可以进行查找字符串等操作。在底行模式下我们还可以直接输入vim help-modes查看当前vim的所有模式
当前处于什么模式,在进入vim后,左下角能看到
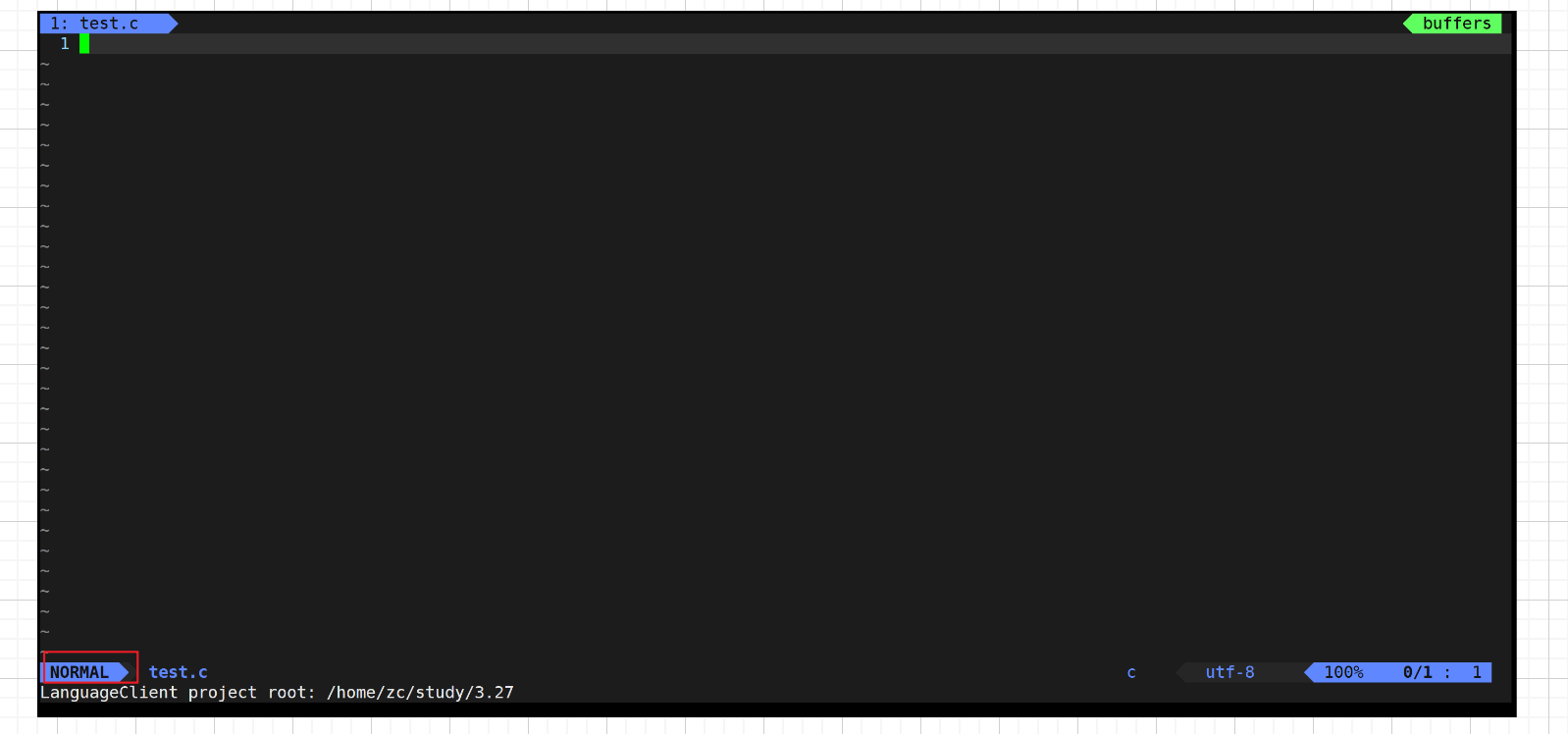
三种模式之间的切换
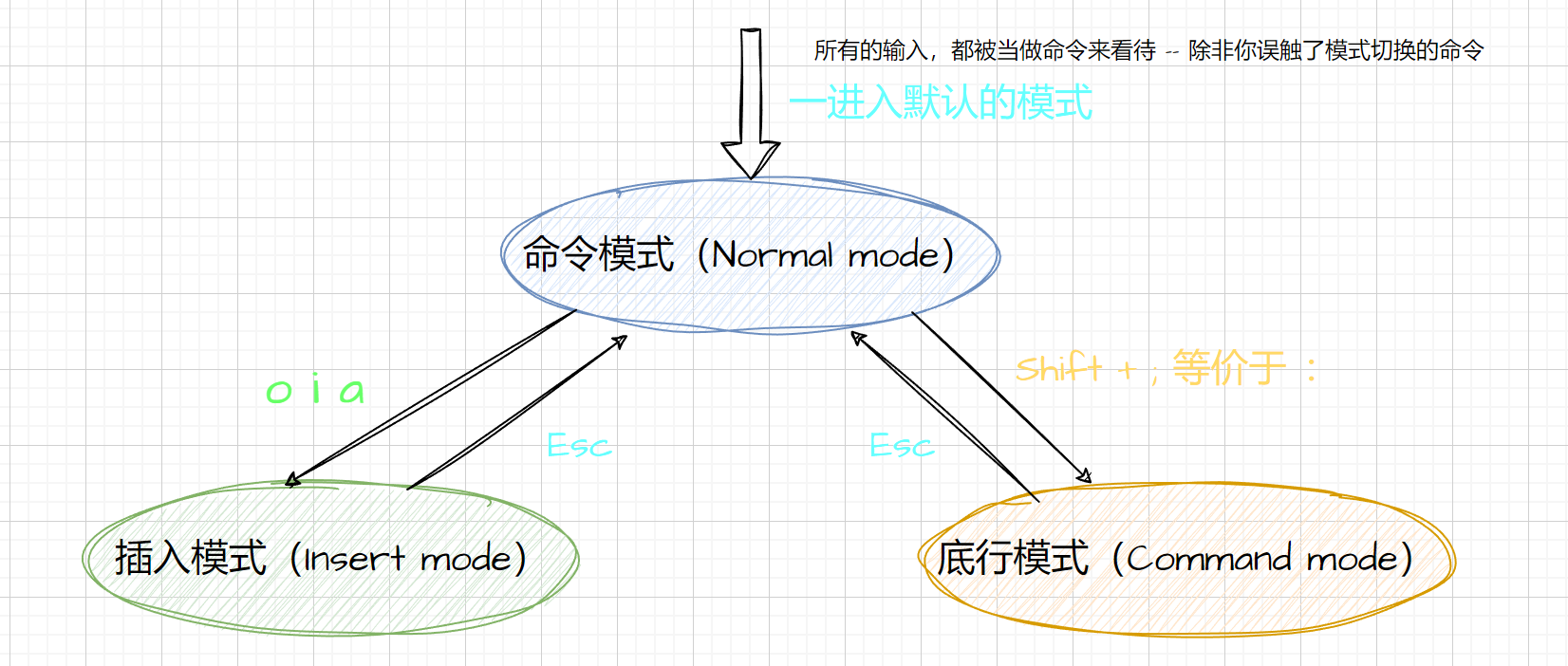
2.2.1命令模式(Normal mode)
在 Vim 中,命令模式(Normal Mode)是默认的模式,在这个模式下你可以执行各种编辑文本的操作。
以下是一些常用的命令模式下的操作:
这些操作都是在 Vim 的命令模式(Normal Mode)下使用的。在命令模式下,你可以通过按下不同的键来执行各种编辑文本的操作。这里详细说明一下你提到的一些常用操作:
-
进入插入模式(Insert Mode):
- 按下
i键进入插入模式,光标将定位到当前位置之前,可以开始插入文字。 - 按下
a键进入插入模式,光标将定位到当前位置之后,可以开始插入文字。 - 按下
o键进入插入模式,在当前行的下方插入一个新的空行,光标将定位到新行的起始位置。
- 按下
-
移动光标:
- 使用
h、j、k、l分别向左、下、上、右移动光标。 - 使用
w和b分别跳到下一个单词的开头和上一个单词的开头。 - 使用
^跳到当前行的第一个非空字符处。 - 使用
$跳到当前行的最后一个字符处。 - 使用
gg跳到文件的开头,G跳到文件的末尾。
- 使用
-
删除文字:
- 使用
x删除光标所在位置的字符,X删除光标前一个字符。 - 使用
dd删除当前行,ndd删除当前行及其后的 n-1 行。
- 使用
-
复制和粘贴:
- 使用
yw复制光标所在位置到单词末尾的内容,yy复制整行。 - 使用
p粘贴已经复制或删除的内容到光标位置后。
- 使用
-
替换:
- 使用
r替换光标所在位置的字符。
- 使用
-
撤销和重做:
- 使用
u撤销上一步操作,Ctrl + r重做上一步操作的撤销。
- 使用
-
更改:
- 使用
cw更改光标所在位置到单词末尾的内容,c#w更改指定数量的单词。
- 使用
-
跳转至指定行:
- 使用
:n跳转至第 n 行,例如:15跳转至第 15 行。
- 使用
2.2.2插入模式(Insert mode)
在 Vim 编辑器中,插入模式(Insert Mode)是用于输入和编辑文本的模式。在插入模式下,你可以直接在文本中插入、编辑和删除字符,就像在普通的文本编辑器中一样。
在插入模式下,你可以自由地编辑文本,直到按下 Esc 键退出插入模式,回到普通模式(Normal Mode)为止。插入模式是 Vim 编辑器中最常用的模式之一,能够有效地提高文本编辑的效率。
2.2.3底行模式(Command mode)
在使用末行模式之前,请确保您已经处于正常模式,按下「ESC」键,然后按下冒号「:」键即可进入末行模式。
- 列出行号
要在文件中的每一行前面显示行号,可以使用以下命令:
:set nu
执行上述命令后,编辑器会在每一行前面显示行号。
- 跳到文件中的某一行
要跳到文件的特定行,可以在冒号后输入行号,然后按回车键。例如,要跳到第 15 行,可以执行以下命令:
:15
执行上述命令后,编辑器会跳到文件的第 15 行。
- 查找字符
Vim 提供了两种查找字符的方式:
- 使用
/进行向后查找。 - 使用
?进行向前查找。
例如,要向后查找某个关键字,可以执行以下命令:
/关键字
执行上述命令后,编辑器会开始向后查找包含指定关键字的文本。
如果要向前查找关键字,可以执行以下命令:
?关键字
执行上述命令后,编辑器会开始向前查找包含指定关键字的文本。
- 保存文件
要保存文件,可以执行以下命令:
:w
执行上述命令后,编辑器会将文件保存到磁盘上,但不会退出编辑器。
- 离开 Vim
要退出 Vim 编辑器,可以执行以下命令:
:q
执行上述命令后,如果文件未做过修改,编辑器会立即退出。如果文件已经做过修改,编辑器会提示保存文件或者放弃修改。
如果要强制退出而不保存修改,可以执行以下命令:
:q!
执行上述命令后,编辑器会立即退出,且不会保存任何修改。
如果想在退出之前保存文件,可以执行以下命令:
:wq
执行上述命令后,编辑器会保存文件并退出。
这些是一些常用的末行命令,可以帮助您更有效地编辑和管理文件。
2.3 批量注释和批量删前面的空格
批量注释
批量注释:
- 按下
Ctrl + v进入可视块模式。- 使用
hjkl键选择要注释的区域,按j键向下移动选择。- 按下
Shift + i进入插入模式,并按下=符号添加注释符号。- 输入注释符号
//(或其他符号),然后按下Esc键退出插入模式。批量去注释:
- 按下
Ctrl + v进入可视块模式。- 使用
hjkl键选择已注释的区域。- 按下
d键删除选择的注释行。- 按下
Esc键退出可视块模式。
批量删前面的空格
- 按下
Ctrl + v进入可视块模式。- 使用
hjkl键选择要注释的区域,按j键向下移动选择。- 按下
d就可删除选中的区域
3.gcc/g++ –Linux编译器
3.1基本介绍
gcc和g++是在Linux系统中常用的编译器,用于编译C和C++程序。
- gcc: GNU Compiler Collection(GNU编译器套件),用于编译C程序。
- g++: GNU C++ Compiler(GNU C++编译器),用于编译C++程序。
这两个编译器提供了丰富的功能和选项,可以将源代码文件编译成可执行文件。编译器可以处理多个源文件,并生成相应的目标文件,最后将目标文件链接在一起生成可执行文件。
这里二者用法几乎一样,我举例子用gcc举例
格式: gcc [选项] 要编译的文件 [选项] [目标文件]
常用的选项:
- -E: 只激活预处理,不生成文件,需要将其重定向到一个输出文件中。
- -S: 将源代码编译成汇编语言文件,但不进行汇编和链接。
- -c: 编译源代码到目标代码,生成目标文件而不进行链接。
- -o: 指定输出文件的名称(重命名生成文件),后面跟着输出文件的路径和名称。
- -static: 采用静态链接,生成的文件使用静态库链接。(自动默认是动态链接)
- -g: 生成调试信息,方便调试器进行调试。
- -shared: 尽量使用动态库,生成文件较小,但需要系统支持动态库。
- -O0, -O1, -O2, -O3: 编译器的优化级别,分别表示没有优化、默认优化级别、优化级别2和优化级别3。
- -w: 不生成任何警告信息
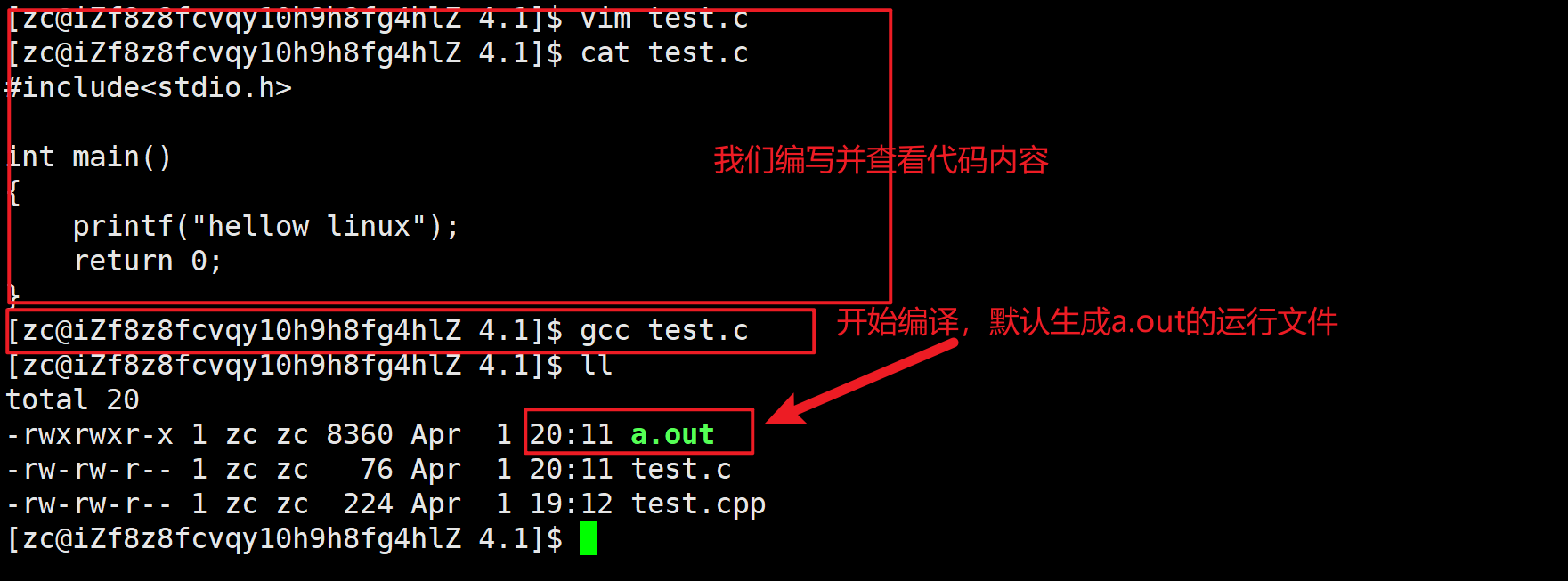
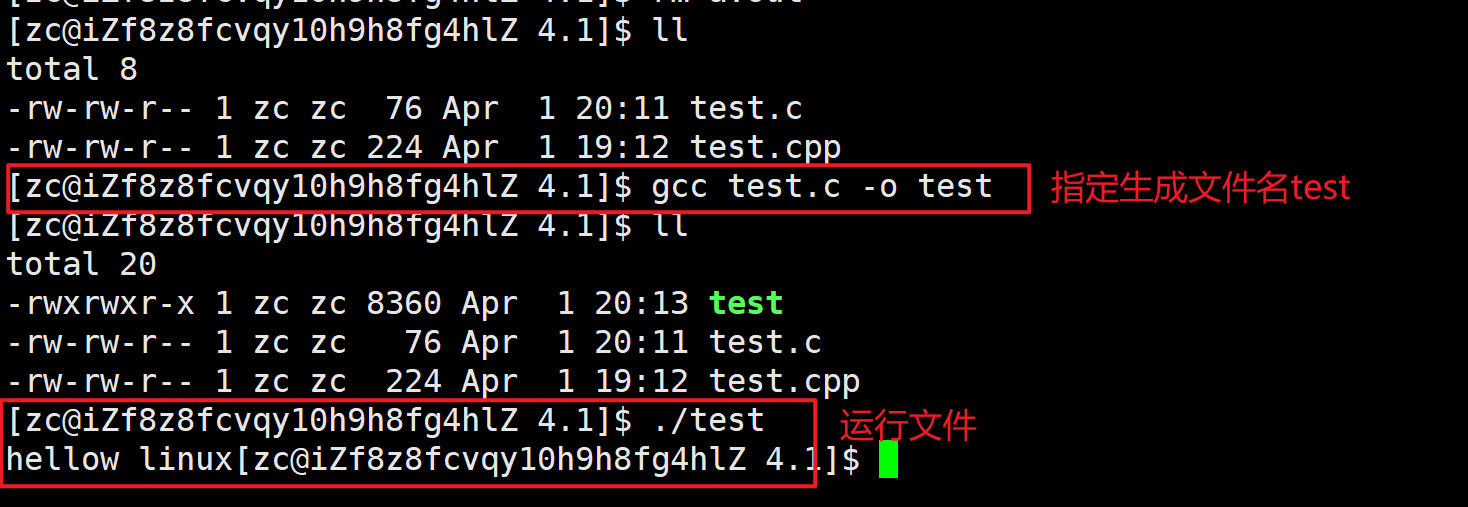
3.2编译过程

编译过程通常包括以下四个阶段:
-
预处理(Preprocessing):
- 在这个阶段,预处理器将源代码中的预处理指令(如宏替换、条件编译等)处理成适合编译器进一步处理的形式。
- 预处理器的工作包括文件包含(
#include)、宏替换(#define)、条件编译(#ifdef、#ifndef等)等。
所谓的头文件展开,本质是在预处理的时候,将头文件内容拷贝至源文件
- 预处理器处理后的文件通常具有更大的体积,并且不包含注释和空行。
gcc –E hello.c –o hello.i选项
-E,该选项的作用是让 gcc 在预处理结束后停止编译过程。选项
-o是指目标文件,.i文件为已经过预处理的C原始程序 -
编译(Compiling):
- 编译器接收预处理阶段生成的文件,并将其翻译成汇编语言(Assembly Language)。
- 编译器的工作包括词法分析、语法分析、语义分析、优化等。
- 编译器输出的结果是以汇编语言表示的中间代码。
gcc –S hello.i –o hello.s选项
-S进行编译而不进行汇编,生成汇编代码 -
汇编(Assembling):
- 汇编器接收编译阶段生成的汇编代码,并将其翻译成机器可识别的目标文件(二进制文件)。
- 汇编器的工作是将汇编指令翻译成对应的机器指令,并生成与目标硬件架构兼容的目标文件。
gcc –c hello.s –o hello.o选项
-c就可看到汇编代码已转化为.o的二进制目标代码了 -
连接(Linking):
- 连接器接收一个或多个目标文件以及库文件,并将它们组合在一起生成可执行文件或者共享库。
- 连接器的工作包括符号解析、重定位、链接库的加载等。
- 最终生成的可执行文件或共享库包含了所有必要的代码和数据,可以在操作系统上运行。
gcc hello.o –o hello注意这里是
hello.o的二进制代码文件
3.2 动静态库
本质都是文件
1. 静态库(Static Library):
-
定义:静态库是一组已编译的目标文件(通常以
.a为后缀),其中包含了函数和数据,可以被多个程序使用。 -
特点:
- 在编译时将静态库的代码复制到可执行文件中,因此可执行文件会比较大。
- 程序在编译时就会把所需的库函数代码和数据加入到可执行文件中,因此在运行时不需要依赖外部的库文件。
- 每个使用了静态库的程序都会拷贝一份静态库代码,造成了一定的代码冗余。
- 使用静态库编译的程序可以在没有任何其他文件的情况下运行。
-
使用方法:在编译时,通过链接器将静态库与目标文件链接成一个可执行文件。
2. 动态库(Dynamic Library):
-
定义:动态库是一组已编译的目标文件(通常以
.so为后缀),其中包含了函数和数据,可以被多个程序使用。 -
特点:
- 动态库的代码不会被复制到可执行文件中,而是在程序运行时由动态链接器加载到内存中。
- 可执行文件相对较小,因为它只包含了链接到动态库的信息,而不是实际的库代码。
- 多个程序可以共享同一个动态库的实例,节省系统资源。
- 动态库的更新更加灵活,只需要替换动态库文件,不需要重新编译程序。
-
使用方法:在编译时,通过链接器将动态库与目标文件链接成一个可执行文件,并在程序运行时由动态链接器动态加载。
在Linux里,gcc默认是进行动态链接的,使用动态库。想要使用静态链接,可以用:
gcc test.c -static

4.make/Makefile –Linux项目自动化构建工具
make 是一个用于自动化构建项目的工具,通常配合一个名为 Makefile 的文件使用。Makefile 文件包含了一系列规则和命令,描述了项目中各个文件之间的依赖关系以及如何构建和编译项目。
以下是 Makefile 文件的基本结构:
target: dependenciescommand
target是一个需要构建的目标文件名,可以是可执行文件、目标文件或者是伪目标(如clean等)。dependencies是构建target所依赖的文件列表。command是构建target所执行的命令。
例如,下面是一个简单的 Makefile 文件示例:
test_make:test.cgcc -o test_make test.cclean:rm -f test_make
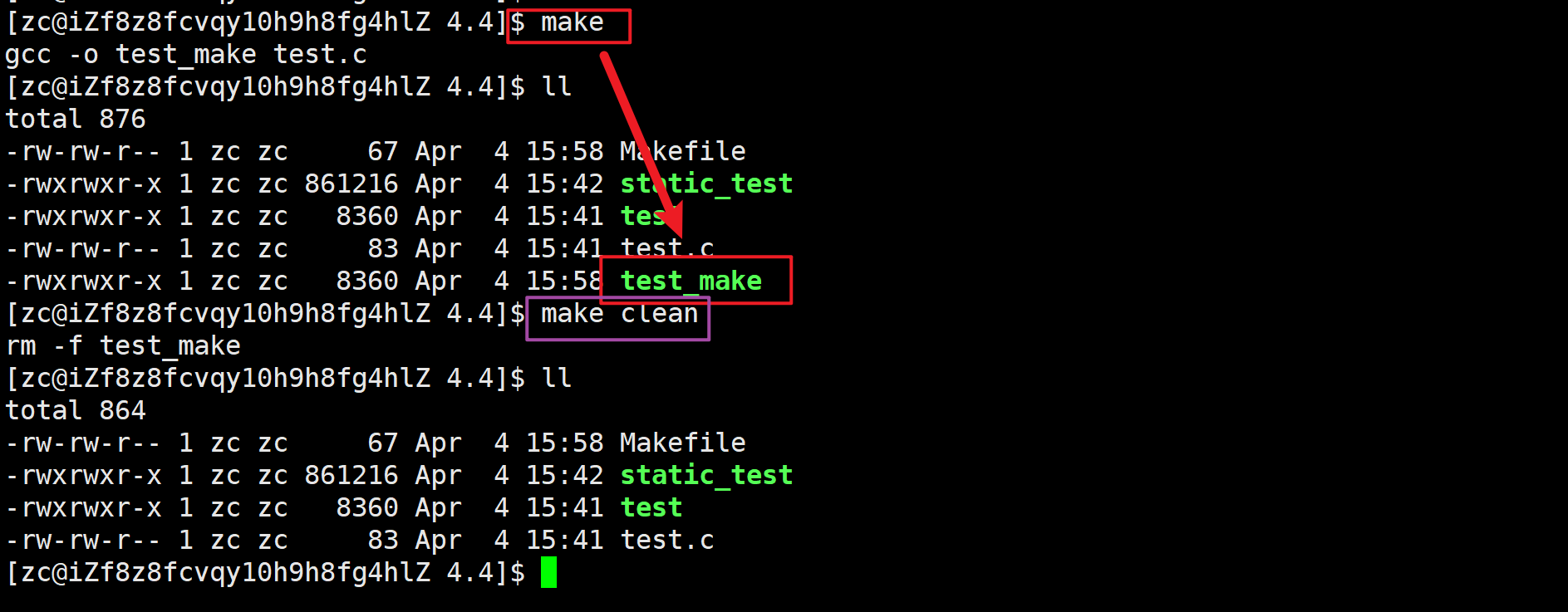
在Makefile中,依赖关系表示目标文件依赖于哪些其他文件,而依赖方法表示如何生成目标文件
-
依赖关系:
- 在Makefile中,每个目标文件都有一组依赖关系,这些依赖关系指示了生成目标文件所需的其他文件或操作。
- 依赖关系是指在构建目标文件之前需要先构建或获取的文件或操作。
- 依赖关系通常是源文件或其他目标文件,它们是构建目标文件的输入或先决条件。
- 如果任何一个依赖关系发生了变化(例如,文件已被修改),则目标文件将被重新生成。
-
依赖方法:
- 依赖方法指定了如何生成目标文件,即构建目标文件所需的命令或操作。
- 依赖方法包含了一系列的命令,这些命令被执行以生成目标文件。
- 常见的依赖方法包括编译源文件、链接目标文件等。
- 依赖方法通常使用命令工具(如编译器、链接器等)来执行所需的操作。
上面的例子里:
在这个简单的Makefile中,存在一个目标文件
test_make和一个伪目标文件clean。下面是它们的依赖关系和依赖方法的解释:
- 依赖关系:
- 目标文件
test_make的依赖关系是源文件test.c。这意味着在生成test_make目标文件之前,必须先生成test.c文件。- 由于
test_make是一个可执行文件,它依赖于test.c文件的存在和正确性。如果test.c发生了变化(例如,被修改或重命名),则需要重新生成test_make。
- 依赖方法:
- 对于目标文件
test_make,依赖方法是通过gcc编译器将test.c源文件编译为可执行文件test_make。
- clean目标:
- 伪目标
clean并没有实际的依赖关系,因此它不会触发任何依赖方法。- 依赖方法
rm -f test_make是用来清理目标文件的命令。当执行make clean命令时,它将删除名为test_make的文件。
- Makefile的扫描:
- Makefile 是用来指导
make工具构建目标文件的文件。当你执行make命令时,make工具会查找当前目录下的名为Makefile或makefile的文件,并按顺序执行其中定义的目标。- 在默认情况下,
make工具会从上到下扫描Makefile文件,并构建第一个目标。这意味着,如果你在Makefile中定义了多个目标,只有第一个目标会被构建。
- 如何确定目标文件是否最新:
- 当你执行
make命令时,make工具会比较每个目标文件和它所依赖的源文件的修改时间。如果源文件的修改时间比目标文件的修改时间更晚,或者目标文件不存在,make工具会执行构建该目标文件的命令。否则,如果目标文件的修改时间比源文件的修改时间更晚,make工具认为该目标文件是最新的,不需要重新构建。- 对于可执行文件来说,
make工具也会比较可执行文件和它所依赖的源文件的修改时间。如果可执行文件的修改时间比源文件的修改时间更晚,或者源文件的修改时间比最新的可执行文件的修改时间更晚,那么make工具会重新构建可执行文件。
扩展
伪目标是 Makefile 中的一种特殊类型的目标,它不表示一个真实的文件,而是表示一个命令序列或操作。使用伪目标可以告诉 make 工具,该目标不对应任何实际文件,因此总是需要执行其后定义的命令。这在执行一些通用操作,比如清理、打包等情况下非常有用。
在 Makefile 中,使用 .PHONY 来声明一个目标为伪目标。这样,当 make 命令执行时,就会忽略目标对应文件的存在与否,直接执行后续定义的命令。
.PHONY: clean
clean:rm -f *.o
clean是一个伪目标,它不代表任何实际文件。无论是否存在名为clean的文件,执行make clean命令时,都会执行rm -f *.o命令来清理所有.o文件。
$@ 和 $^ 是 make 中的自动化变量,用于表示目标和依赖的列表。具体含义如下:
$@表示目标文件的名称。$^表示所有依赖文件的列表。
这些自动化变量通常用于构建命令中,以方便地引用目标和依赖文件。例如:
test: test.cgcc -o $@ $^
$@会被替换为目标文件test,$^会被替换为所有依赖文件列表,即test.c。因此,执行make test命令时,相当于执行gcc -o test test.c,将test.c编译成可执行文件test。
原理
-
当你输入
make命令时,make工具会在当前目录下查找名为Makefile或makefile的文件。 -
如果找到了
Makefile文件,make将会查找文件中的第一个目标(target),并把它作为最终的目标文件。 -
如果该目标文件不存在,或是其依赖的文件比目标文件的修改时间新(包括依赖的文件和目标文件本身),那么
make将会执行后面定义的命令来生成目标文件。 -
如果目标文件的依赖文件也不存在,那么
make将会在当前文件中查找目标文件的依赖性,并根据规则生成缺失的依赖文件。 -
当所有依赖关系都得到满足后,
make会按照依赖关系逐层构建,直到生成最终的目标文件。 -
如果在查找依赖关系的过程中遇到错误,比如某个被依赖的文件找不到,
make会直接退出并报。但对于生成目标文件时出现的错误,或编译不成功的情况,make不会立即退出,而是继续执行后续的规则。 -
make工具只关心文件之间的依赖关系,如果依赖关系满足,就会执行后续的命令来生成目标文件。如果依赖关系不满足,make将不会进行后续操作。
好啦这次就先到这里了,下次会给大家带来进程相关的知识啦!!
这篇关于Linux:常用软件、工具和周边知识介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





