本文主要是介绍万物皆可计算|下一个风口:近内存计算-1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
传统的冯·诺依曼架构虽然广泛应用于各类计算系统,但其分离的数据存储与处理单元导致了数据传输瓶颈,特别是在处理内存密集型任务时,CPU或GPU需要频繁地从内存中读取数据进行运算,然后再将结果写回内存,这一过程涉及大量的数据传输和较高的延迟,成为制约系统性能提升的关键瓶颈。
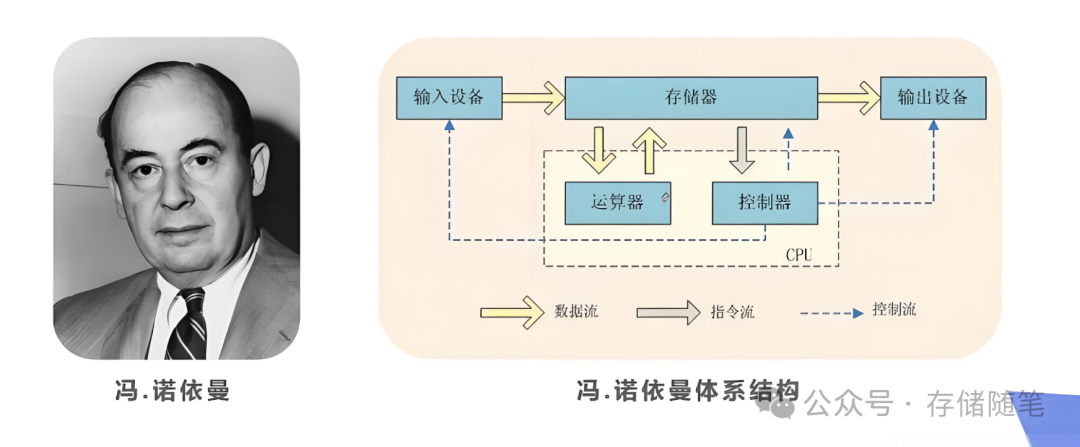
冯·诺依曼架构中目前还有一个很严重的问题叫做内存墙(Memory Wall),处理器速度(尤其是CPU)相对于主内存(如DRAM)访问速度的增长差距所造成的性能瓶颈现象。随着处理器性能不断提升,其处理数据的速度远超主内存的读写速度,导致处理器经常处于等待数据从内存加载到缓存或从缓存写回内存的状态,这种等待时间占用了大量原本可用于计算的时间,限制了整个系统的性能表现。简而言之,内存墙就是指处理器与内存之间的带宽和延迟不匹配导致的性能障碍。
PIM(Processing-in-Memory)内存计算技术则是为解决内存墙问题而提出的一种计算范式。它将计算功能直接集成到内存模块内部或非常靠近内存的位置,使得数据处理能够在数据驻留的地方进行,而非在传统架构中先将数据从内存取出、经过较慢的总线传送到处理器、进行计算后再返回内存。
PIM的核心思想是“数据在哪里,计算就在哪里”。通过在内存芯片内部或紧邻内存的位置添加计算单元,可以大幅度减少甚至消除频繁的数据搬运过程。数据不再需要经过内存控制器、总线和各级缓存,而是直接在内存内部完成计算操作。这样,就消除了因数据传输产生的延迟和带宽压力,显著降低了处理器等待数据的时间。

超大规模人工智能(AI)系统,以ChatGPT等为代表,凭借其仿人问答、对话、甚至创作音乐和编写计算机程序等能力,震撼全球。然而,在这神奇表象的背后,实则需要庞大的内存密集型数据计算支撑。针对AI系统对传统内存解决方案提出的指数级增长需求,三星已在其高带宽内存(HBM)中集成了一款专为AI设计的产品HBM-PIM(High Bandwidth Memory with Processing-in-Memory)。这项PIM(Processing-in-Memory)技术将计算功能直接集成到高带宽内存(HBM)芯片内部,实现了数据处理与存储的深度融合,减少数据迁移,通过将部分数据计算工作从处理器转移到内存本身,从而大幅提升AI加速器系统的能效比。
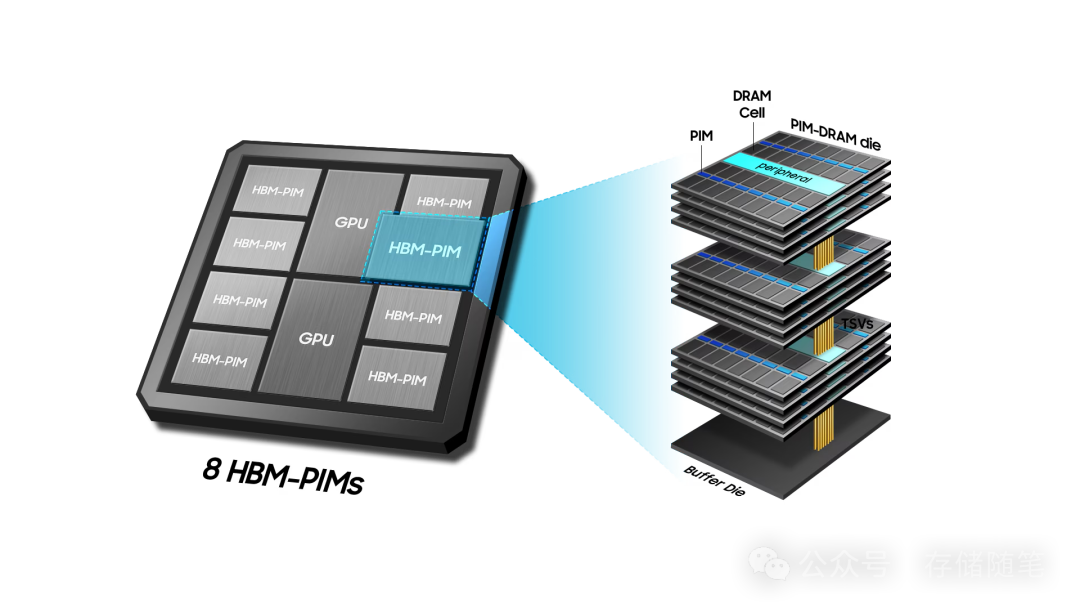
在HBM堆栈的每个内存裸片(die)上集成可编程计算单元(PCU),这些计算单元能够直接在存储数据的位置执行特定类型的计算任务,如矩阵乘法、卷积等,这些都是人工智能和高性能计算中常见的操作。
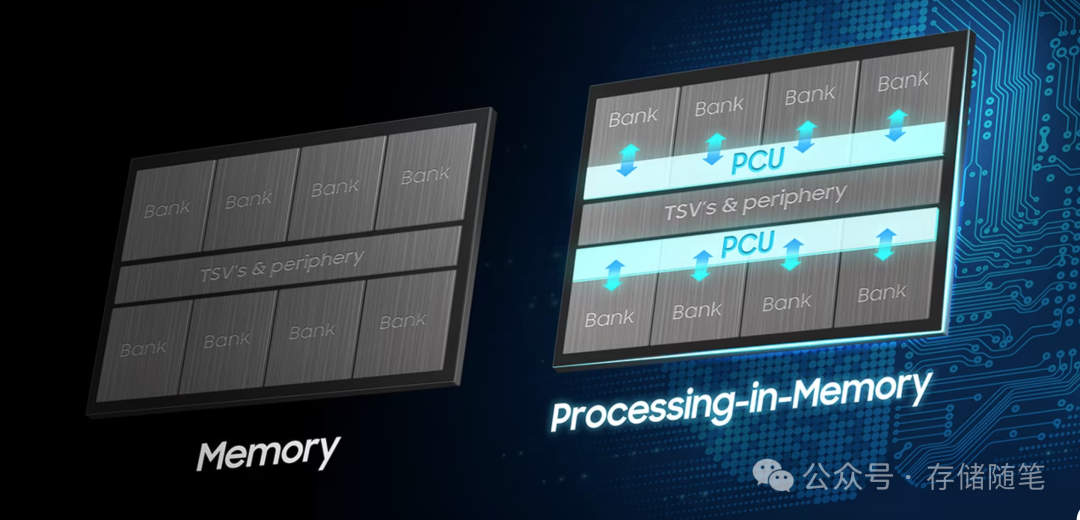
GPU+HBM组合中,计算主要发生在GPU的处理核心(如CUDA核心或Tensor Core),数据需要从HBM内存传输到GPU核心进行运算;而在HBM-PIM架构中,部分计算任务直接在内存芯片内部的PCU上完成,无需大量数据迁移。类似于CPU中的多核架构,PCU支持内存中的并行处理,使得多个计算任务能够在同一时间内在不同的内存位置同时执行,充分利用内存的并行访问能力,显著提升数据处理速度。三星官网有一个比较形象的视频,供大家参考:
💻内存也能计算?三星PIM技术让你惊叹不已!😮
由于计算发生在数据存储的地方,避免了传统架构中数据从内存到处理器之间的大规模数据迁移,减少了I/O带宽消耗和延迟。这种数据本地化(Data Locality)策略极大地提高了能效比,降低了整体系统的功耗。
HBM-PIM并非完全替代传统的CPU或GPU,而是与之协同工作。CPU/GPU负责发送指令和控制流,而大部分数据密集型计算任务由内存内的PCU处理。完成后,结果数据可以直接在内存内部进行整合或返回给主处理器进行进一步处理。
这篇关于万物皆可计算|下一个风口:近内存计算-1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




