本文主要是介绍线程池 ThreadPoolExecutor 配置参数详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《开发语言-Java》

线程池 ThreadPoolExecutor 参数详解
- 一、引言
- 二、主要内容
- 2.1 核心构造函数
- 2.2 核心线程数
- 2.3 最大线程数
- 2.4 空闲线程存活时间
- 2.5 keepAliveTime 的时间单位
- 2.6 核心线程在空闲时的回收策略
- 2.7 工作队列
- 2.8 线程工厂
- 2.9 拒绝策略
- 三、总结
一、引言
提到 Java 线程池,就不得不说 ThreadPoolExecutor,它是 Java 并发包 java.util.concurrent 中的一个类,提供一个高效、稳定、灵活的线程池实现,用于实现多线程并发执行任务,提高应用程序的执行效率。
在《任务执行与Executor框架》中,Huazie 介绍了通过 java.util.concurrent.Executors 中的静态工厂方法来创建线程池,而这个线程池实现就是 ThreadPoolExecutor 。
ThreadPoolExecutor 提供了一系列参数和配置选项,开发人员可以根据应用的需求来定制线程池的行为。
本篇就将详细介绍线程池 ThreadPoolExecutor 中的各种配置参数。
二、主要内容
注意: 以下涉及代码,均来自 JDK 1.8,其他版本如有出入,请自行查看
2.1 核心构造函数
话不多说,先来查看 ThreadPoolExecutor 的核心构造函数:
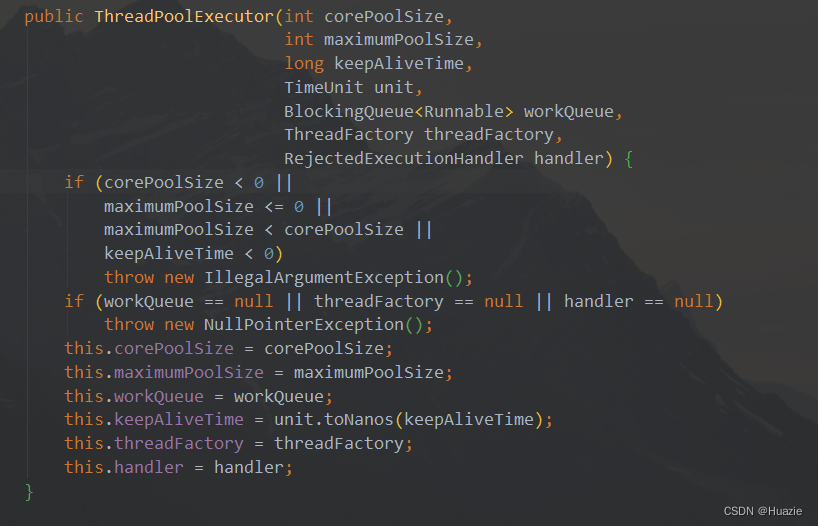
上述构造函数中的 7 个参数就是下面将要重点介绍的线程池 ThreadPoolExecutor 的核心配置参数了。
2.2 核心线程数
private volatile int corePoolSize;
corePoolSize 变量就是 核心线程数,即在没有设置allowCoreThreadTimeOut 为 true 的情况下,需要保持存活的最小工作线程数量。
翻看 ThreadPoolExecutor 的 execute(Runnable command) 方法的源码,如下:
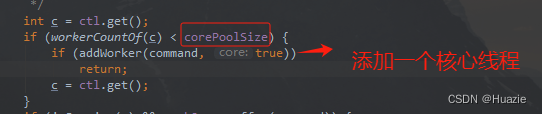
上述截图代码可以看出: 如果运行的线程数少于核心线程数,则为当前任务启动一个新的核心线程。
调用 addWorker 方法会原子性地检查 runState 和 workerCount,从而防止在不应该添加线程时发出错误警报【这时 addWorker 方法会返回 false】。
可以通过 setCorePoolSize(int corePoolSize) 方法来重新设置核心线程数,如下图所示:
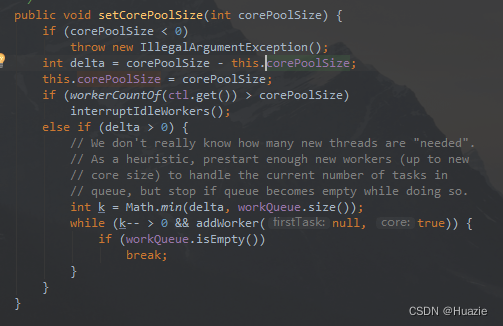
setCorePoolSize 方法将覆盖构造函数中设置的核心线程数。如果新值小于当前值,多余的现有线程将在它们下次变为空闲时被终止。如果新值更大,将根据需要启动新线程来执行任何排队的任务。
2.3 最大线程数
private volatile int maximumPoolSize;
maximumPoolSize 变量就是线程池允许的最大线程数。
可以通过 setMaximumPoolSize(int maximumPoolSize) 方法来重新设置线程池允许的最大线程数,如下图所示:

setMaximumPoolSize 方法将覆盖构造函数中设置的最大线程数。如果新值小于当前值,多余的现有线程将在它们下次变为空闲时被终止。
2.4 空闲线程存活时间
private volatile long keepAliveTime;
keepAliveTime 变量就是空闲线程存活时间【即空闲线程等待工作的超时时间(以纳秒为单位)】。当线程池中的线程数量超过 核心线程数 或者 允许核心线程超时 时,线程将使用此超时时间。否则,它们将无限期地等待新工作。
可以通过 setKeepAliveTime(long time, TimeUnit unit) 方法来重新设置空闲线程存活时间,如下图所示:
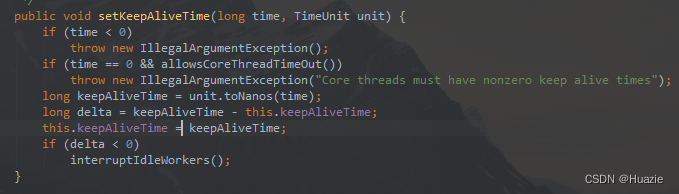
setKeepAliveTime 方法会覆盖在构造函数中设置的空闲线程存活时间。如果当前池中有多于核心数量的线程,在等待这段时间而没有处理任务之后,多余的线程将会被终止。
2.5 keepAliveTime 的时间单位
long keepAliveTime;
TimeUnit unit;
// 空闲线程等待工作的超时时间
this.keepAliveTime = unit.toNanos(keepAliveTime);
TimeUnit 是 java.util.concurrent 包中的枚举类,用于表示给定粒度单位时间持续时间的类,并提供了一些实用方法来进行单位之间的转换,以及在这些单位中执行定时和延迟操作。TimeUnit 并不维护时间信息,而是帮助组织和使用可能在各种上下文中分别维护的时间表示。纳秒被定义为微秒的千分之一,微秒是毫秒的千分之一,毫秒是秒的千分之一,分钟是六十秒,小时是六十分钟,天是二十四小时。
unit.toNanos 用于将 keepAliveTime 的参数值转换为纳秒值。
另外,在源码注释中有如下一段话:
there is no guarantee that a particular timeout implementation
will be able to notice the passage of time
at the same granularity as the given TimeUnit.
翻译中文,大概意思就是:
特定的超时实现可能无法保证能够以与给定TimeUnit相同的粒度来感知时间的流逝。
这怎么来理解呢?
这句话是说,尽管 TimeUnit 允许你以不同的时间单位(如纳秒、微秒、毫秒等)指定超时时间,但实际的超时检测机制可能无法精确地按照这些单位来检测时间的流逝。操作系统和硬件通常有 最小时间片 的概念,即它们能够识别的时间单位的最小粒度。例如,某些系统可能只能精确到毫秒级别,而无法精确到更小的微秒或纳秒级别。这意味着即使请求一个非常短的超时(比如几纳秒),实际的等待时间可能会更长,因为系统无法检测到这么短的时间间隔。此外,线程调度和其他系统级别的延迟也可能影响超时的实际精度。即使指定的超时单位很小,其他因素(如线程切换、系统负载等)也可能导致实际的等待时间超过预期。
2.6 核心线程在空闲时的回收策略
private volatile boolean allowCoreThreadTimeOut;
如果为 false(默认值),即使核心线程处于空闲状态,它们也会保持活动状态。
如果为 true,核心线程会使用 keepAliveTime 来设置等待工作的超时时间。
可以通过 ThreadPoolExecutor 的 allowCoreThreadTimeOut(boolean value) 方法进行设置。
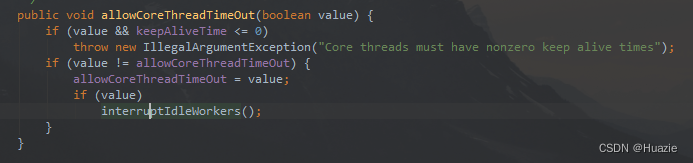
2.7 工作队列
private final BlockingQueue<Runnable> workQueue;
workQueue 变量就是工作队列,它是一个阻塞队列,用于保存等待执行的任务并将其交给工作线程处理。
阅读相关源码注释中,可以看到如下一段话:
We do not require that workQueue.poll() returning null necessarily means that workQueue.isEmpty(),
so rely solely on isEmpty to see if the queue is empty (which we must do for example when deciding
whether to transition from SHUTDOWN to TIDYING). This accommodates special-purpose queues such as
DelayQueues for which poll() is allowed to return null even if it may later return non-null when delays expire.
中文翻译,大概意思如下:
我们并不要求 workQueue.poll() 返回 null 必然意味着 workQueue.isEmpty(),因此仅依赖 isEmpty 来判断队列是否为空(例如,在决定是否从 SHUTDOWN 状态过渡到 TIDYING 状态时必须这样做)。这样可以适应特殊用途的队列,如 DelayQueue,即使它稍后可能会在延迟过期后返回非空值,但 poll() 也允许返回 null。
那这段注释,又该如何理解呢?
我们知道,当使用队列(如 workQueue)来管理待处理的任务时,通常会有一个或多个工作线程不断地从队列中检索任务来进行处理。poll() 方法通常用于从队列中检索下一个可用的元素,但它的行为可能会根据队列的类型而有所不同:
- 在某些队列(如普通的
LinkedBlockingQueue或ArrayBlockingQueue)中,poll()方法在队列为空时返回null,表示没有更多的元素可供处理。在这种情况下,如果poll()返回null,那么可以确定队列是空的,因为poll()的行为与isEmpty()方法的返回值一致。 DelayQueue是一个特殊用途的队列,它允许延迟元素的可用性。在DelayQueue中,即使队列中可能还有未到期的元素(即元素还没有准备好被处理),poll()方法也可能会返回null。这也就说明poll()返回null并不一定意味着队列也是空的,因为可能还有未到期的元素在队列中。
2.8 线程工厂
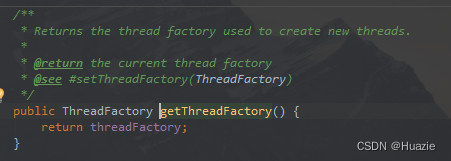
private volatile ThreadFactory threadFactory;
threadFactory 变量就是线程工厂,所有线程都是使用这个工厂创建的(通过 addWorker 方法),默认使用 Executors.defaultThreadFactory() 来创建线程。
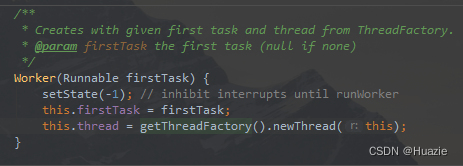
2.9 拒绝策略
private volatile RejectedExecutionHandler handler;
handler 变量就是 拒绝策略,即当执行过程中饱和或关闭时调用的处理程序。
当阻塞队列已满且无法创建新的线程时,线程池会调用拒绝策略来处理新提交的任务。
Java 线程池提供了几种不同的拒绝策略实现,如
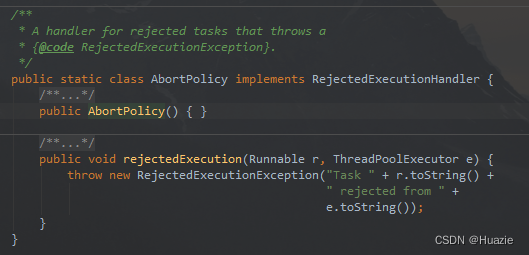
AbortPolicy:默认策略,直接抛出RejectedExecutionException异常,阻止系统正常运行。

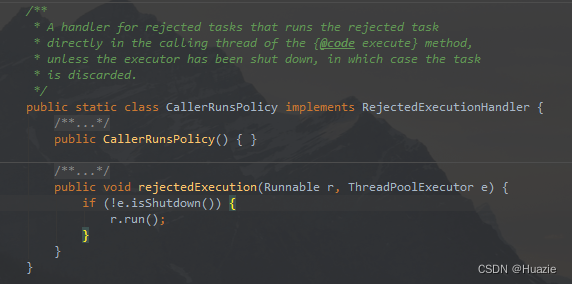
CallerRunsPolicy:只用调用者运行一些任务,如果线程池已满,则将任务回退到调用者执行。
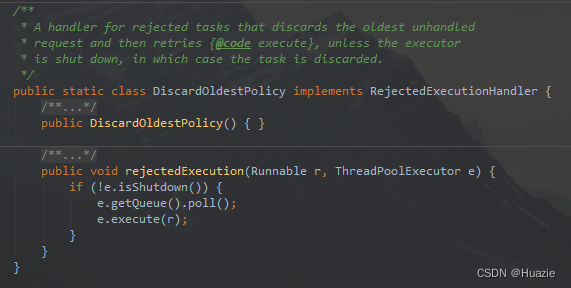
DiscardOldestPolicy:抛弃最老的任务请求,也就是即将被执行的任务。
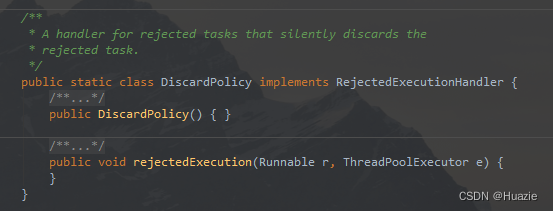
DiscardPolicy:直接丢弃任务,不给予任何处理,也不抛出异常。
三、总结
本文 Huazie 基于线程池 ThreadPoolExecutor 的核心构造函数,详细介绍了它的一些关键配置参数。通过本文的介绍,相信大家能够对线程池 ThreadPoolExecutor 的配置参数有了更加清晰的理解,这有助于后续更深入地掌握线程池的运作原理。
这篇关于线程池 ThreadPoolExecutor 配置参数详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









