本文主要是介绍4.19【编号231】ETLCloud中数据源使用和管理的技巧,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ETL中数据源管理的重要性
在现代企业信息化进程中,数据已成为驱动决策、优化运营、提升竞争力的关键要素。而作为数据处理与分析的重要环节,ETL(Extract, Transform, Load)过程承担着从多种异构数据源中抽取数据,进行必要的转换,并将其加载到目标系统(如数据仓库或数据湖)中的重任。其中,数据源管理在ETL过程中扮演着至关重要的角色,其重要性主要体现在以下几个方面:
1. 数据完整性与一致性
数据源是ETL过程的起点,其管理质量直接影响到后续数据处理的准确性和可靠性。有效管理数据源,确保数据的完整性和一致性,是构建高质量数据资产的基础。这包括对源头数据的定期审计,监控数据更新频率、范围及模式,及时发现并修复数据缺失、错误或不一致的问题,以防止“garbage in, garbage out”现象的发生。此外,通过实施数据版本控制、变更记录等措施,能够追溯数据的历史变化,进一步保障数据的一致性。
2. 数据时效性与可用性
在许多业务场景中,如实时监控、风险预警、市场趋势分析等,数据的时效性至关重要。高效的数据源管理能确保ETL过程能够快速响应数据源的变化,实时或近实时地抽取最新数据,缩短从数据生成到可用的时间差,为决策者提供及时、准确的信息支持。同时,良好的数据源管理还包括对数据源性能的监控与优化,如合理调度数据抽取任务,避免高峰期资源争抢,保证数据的稳定、高效供给。
3. 法规遵从与数据安全
随着全球数据保护法规日益严格,如GDPR、CCPA等,企业必须确保在数据采集、处理、存储、使用等全生命周期中遵守相关法规要求。数据源管理涵盖了对数据来源合法性的验证、敏感数据的识别与脱敏、数据权限的管控等工作,有助于企业在ETL过程中落实数据隐私保护与合规要求,降低法律风险。此外,严密的数据源访问控制机制还能有效防止数据泄露、篡改等安全事件,保障企业核心数据资产的安全。
4. 成本效益与资源优化
数据源往往种类繁多、分布广泛,包括内部业务系统、外部合作伙伴数据、公开数据源等。科学的数据源管理能够帮助企业合理选择和整合数据源,避免重复采集导致的成本浪费,同时通过标准化接口、数据清洗规则等手段降低数据转换复杂度,提高ETL效率。此外,对于云环境下动态伸缩的数据源,有效的管理策略能够根据业务需求自动调整数据抽取频率和规模,实现成本与性能的最佳平衡。
5. 业务敏捷性与创新支持
在快速变化的商业环境中,企业需要灵活应对市场变化,快速响应业务需求。强大的数据源管理能力使得企业能够便捷地接入新的数据源,快速调整ETL流程,支持业务的迭代创新。例如,当企业引入新的营销渠道、合作方或者开展新业务时,能够迅速将其数据纳入分析体系,加速数据分析成果的应用落地,助力业务发展。
综上所述,数据源管理在ETL过程中发挥着不可或缺的作用,它关乎数据质量、时效性、合规性、成本效益以及业务创新等多个关键维度。只有建立完善的数据源管理体系,才能确保ETL过程的顺畅运行,充分发挥数据的价值,为企业决策、运营优化提供强有力的数据支撑。
ETL所有东西都始于抽取,而数据源的配置就是这一部分的起始站,绝大部分的数据都来源这里,为什么是绝大部分而不是全部后面会讲解。
我们以官方提供的演示环境为例,我们常说的数据源,在数据源管理模块下
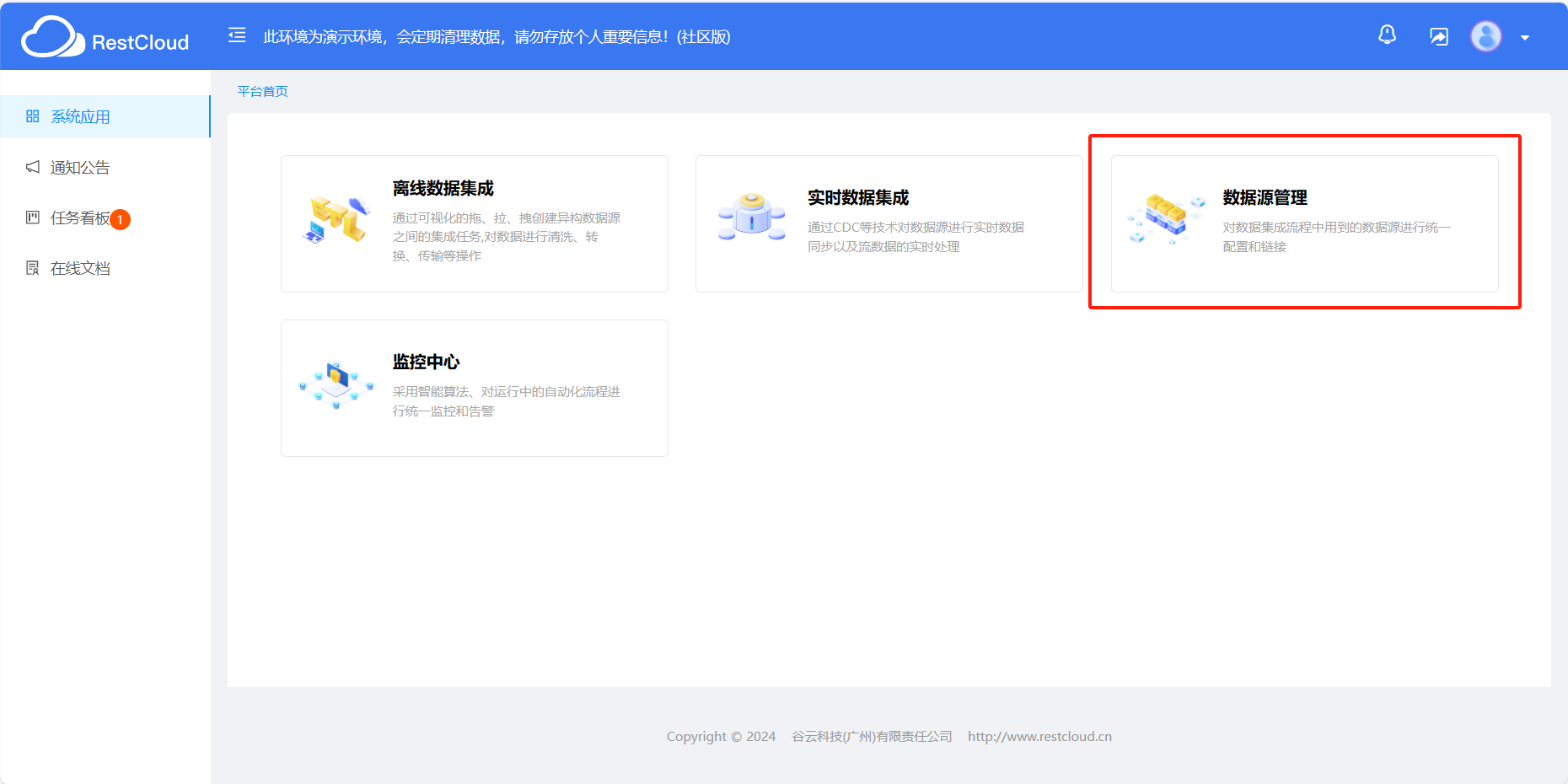
新建数据源步骤
数据源列表
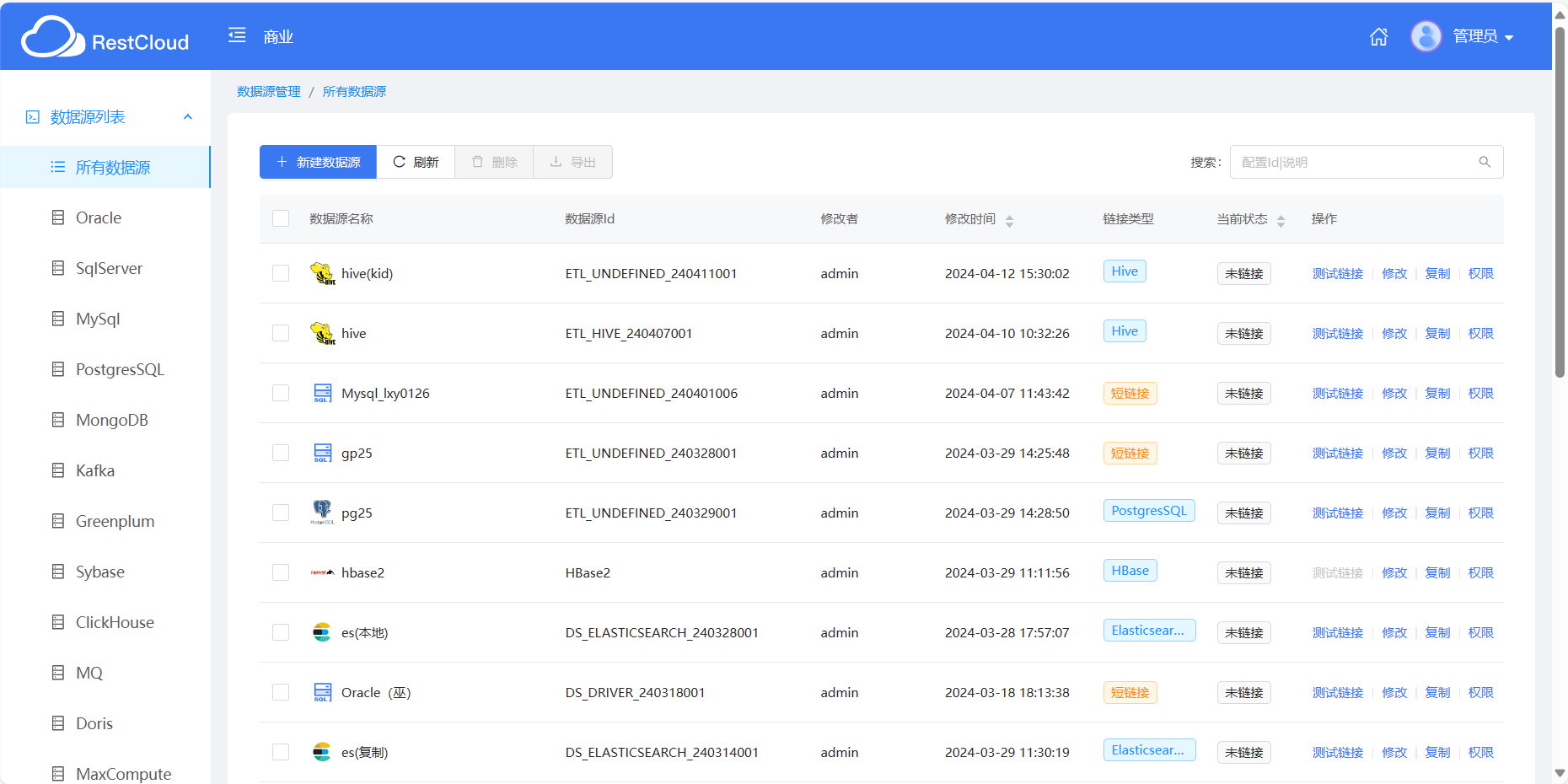
点击新建数据源就可看到所支持的数据源
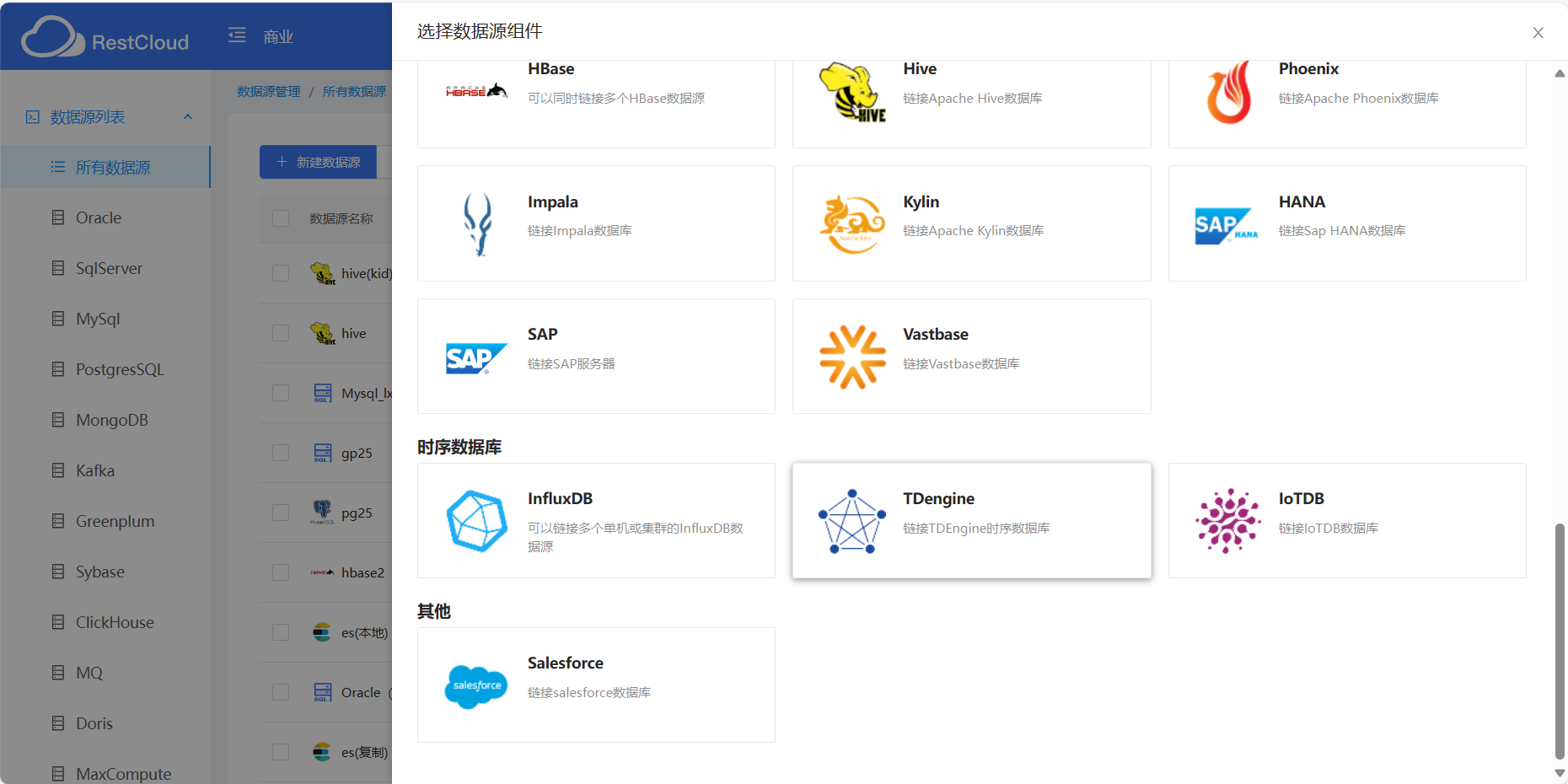
以mysql为例,带有“*”都是必填的,这些都是基本的参数
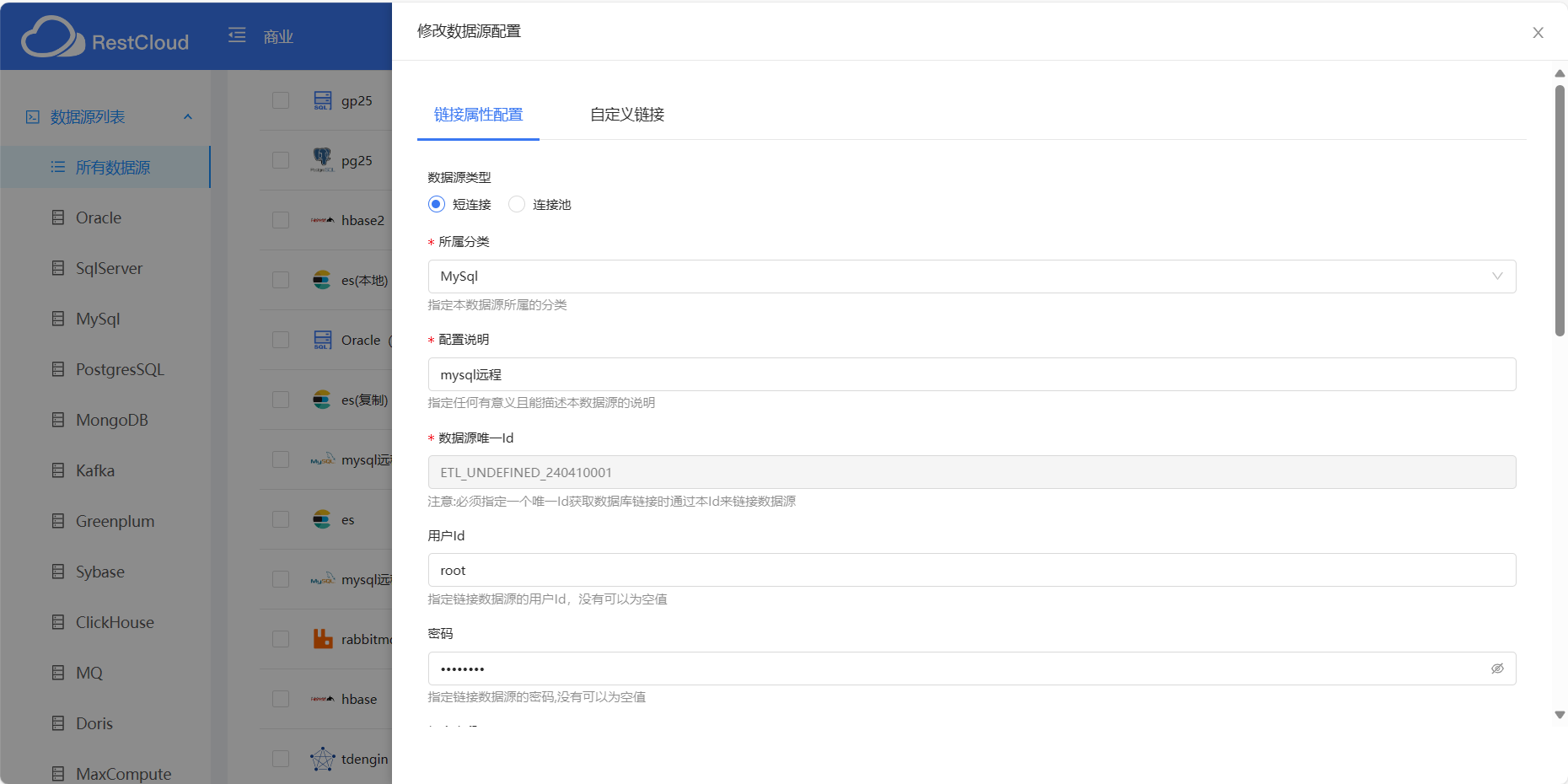
数据库驱动和数据源url
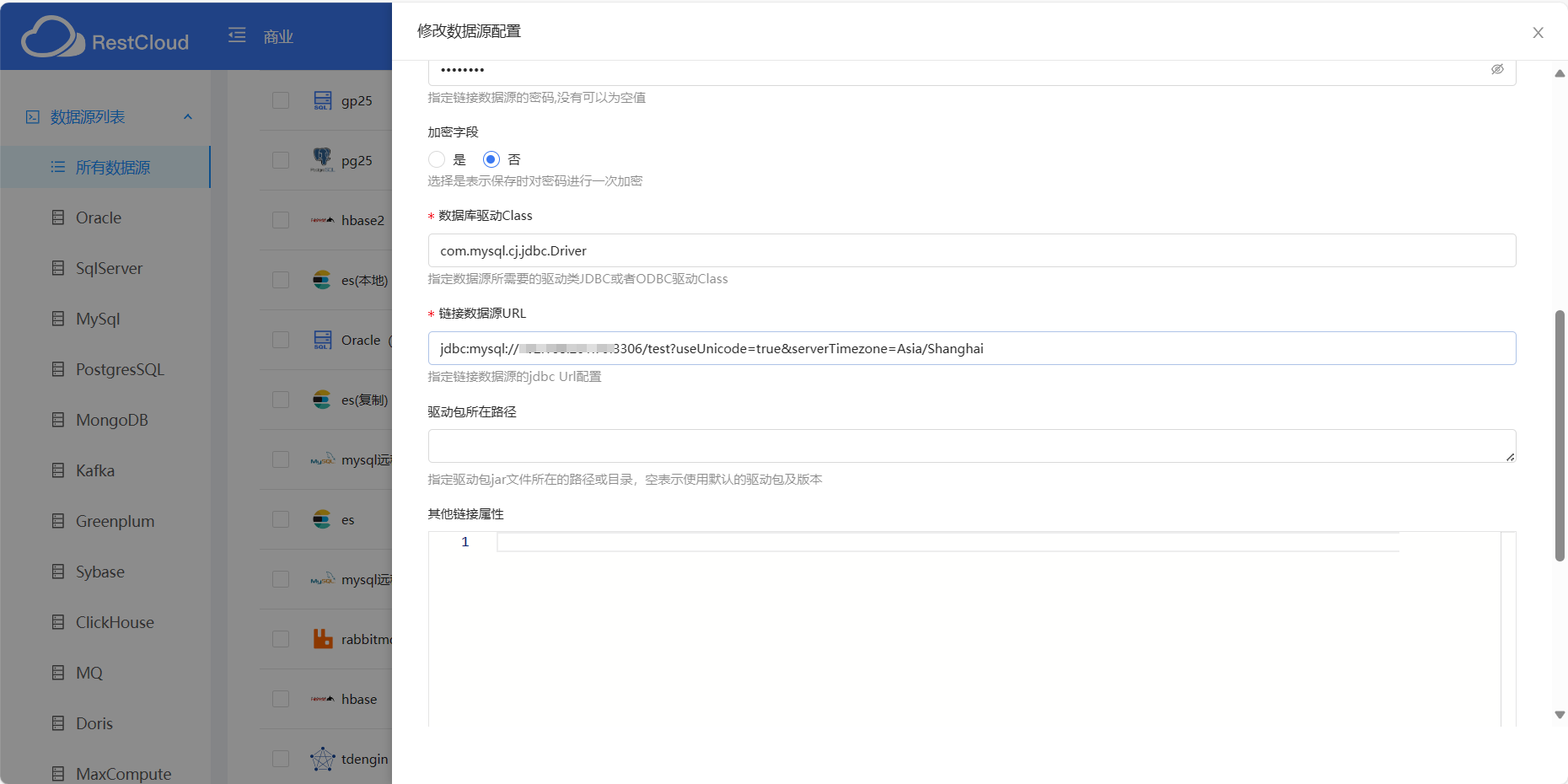
数据库驱动class

所有Rdb关系数据库都是基于jdbc来开发的,如果有些数据库class里没有想要的驱动,去百度一下“xxxx数据库的jdbc驱动class”一般都会出现。
然后是数据源URL:有提示部分数据源的url示例,其中“localhost”和“127.0.0.1”是要换成数据库所在机器的ip,如果是在本地就不需要换。
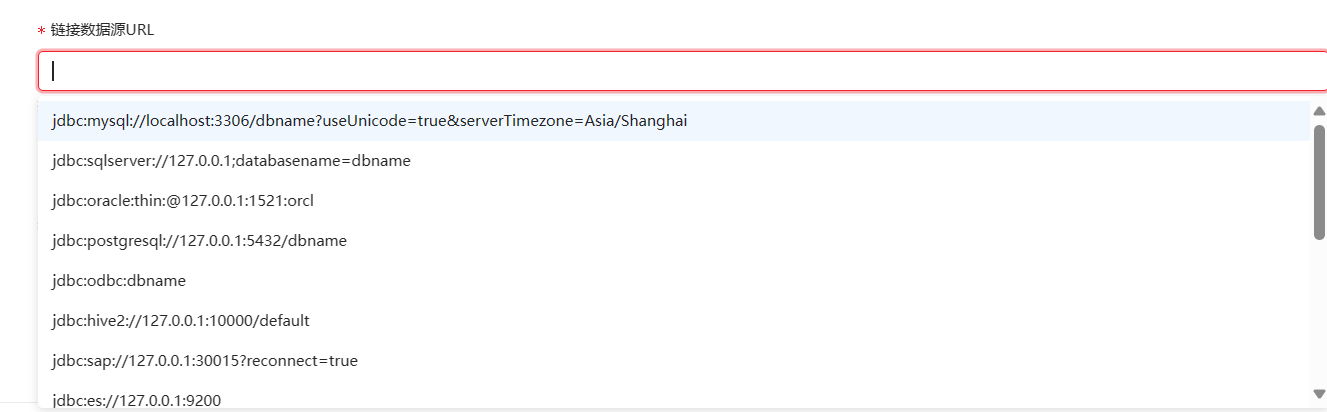
端口后面要改成自己的

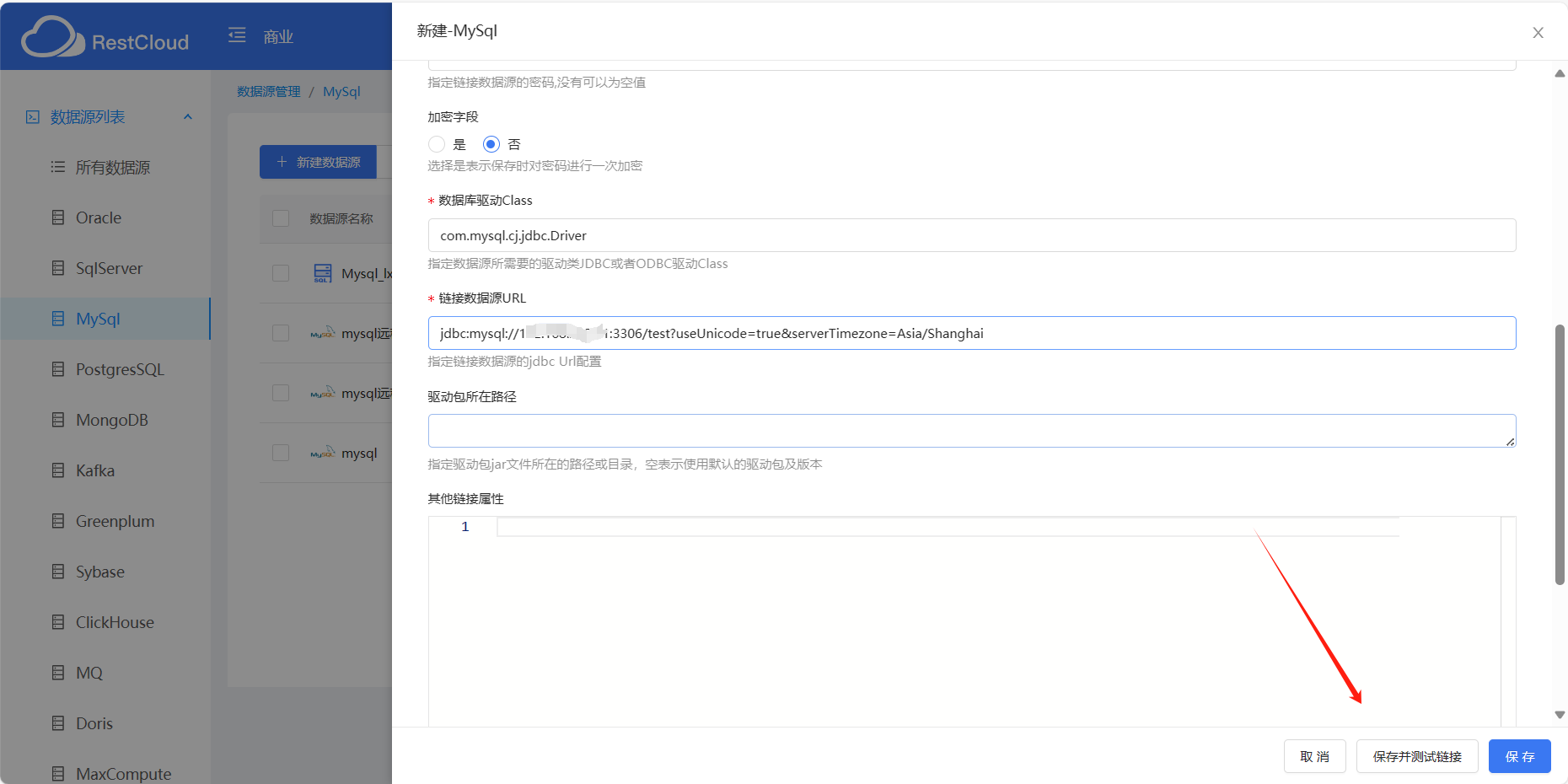
驱动包所在路径和其他连接属性:
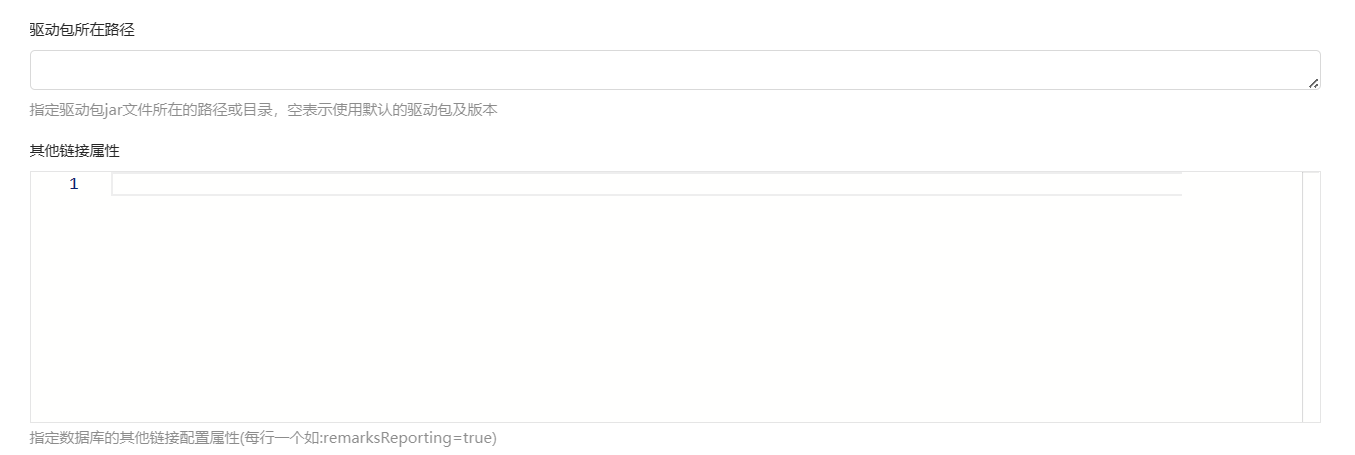
驱动包所在路径:非必填的,之所以设置这个是以防有的用户数据库版本与平台默认的不一样且没办法正常运行,这个时候就要配置驱动包所在路径了。所以是:指定驱动包jar文件所在的路径或目录,空表示使用默认的驱动包及版本。
再就是其他链接属性:
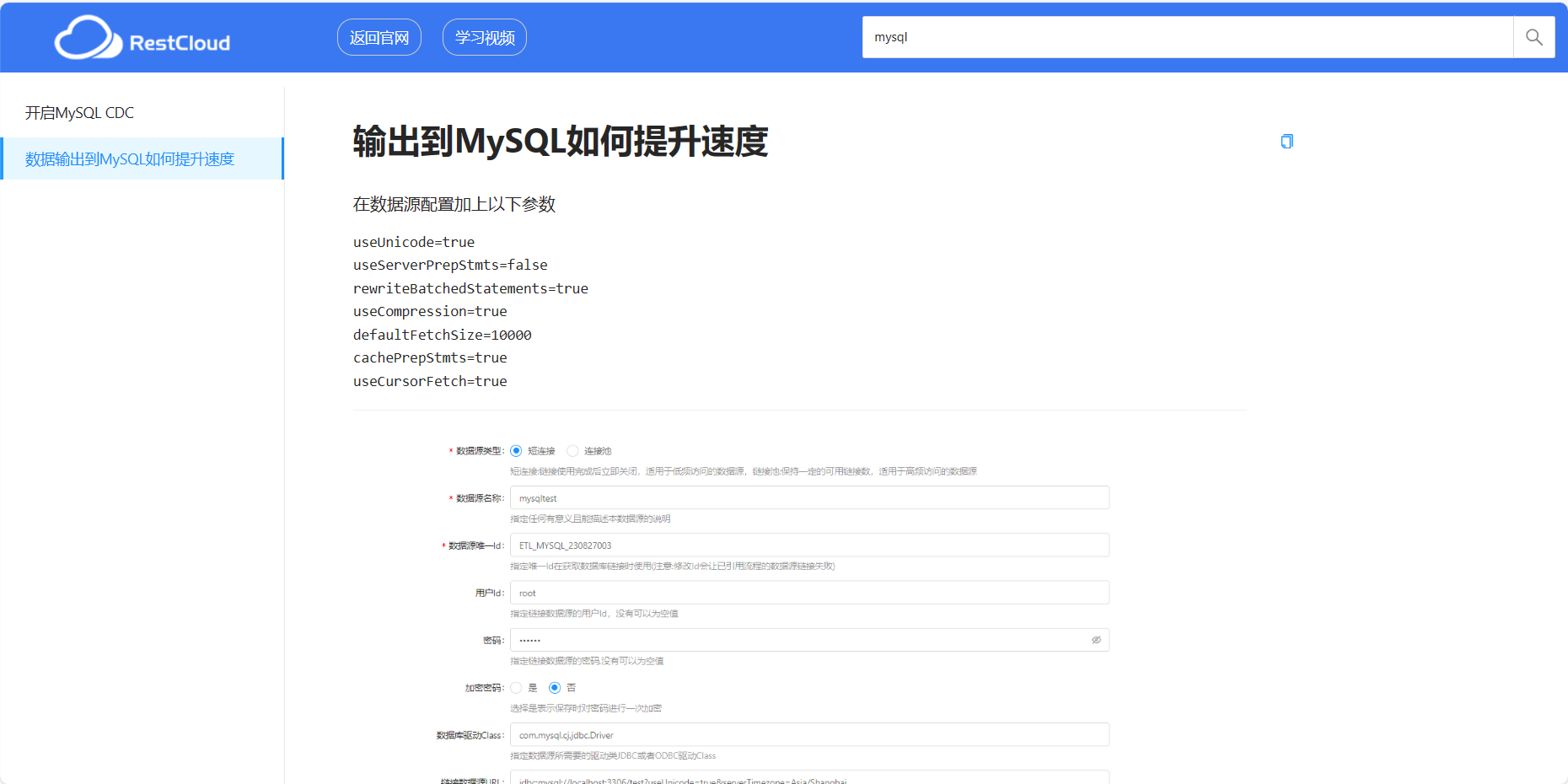
有些数据库支持通过配置参数来优化速度,当觉得数据导入导出慢就可以在这里配置。当然如果自身硬件或者延迟等原因这个是没办法的。
最后保存测试一下
数据源分类
数据源分类是个比较常问的问题,平台默认设置了数据源分类,也可以新建数据源
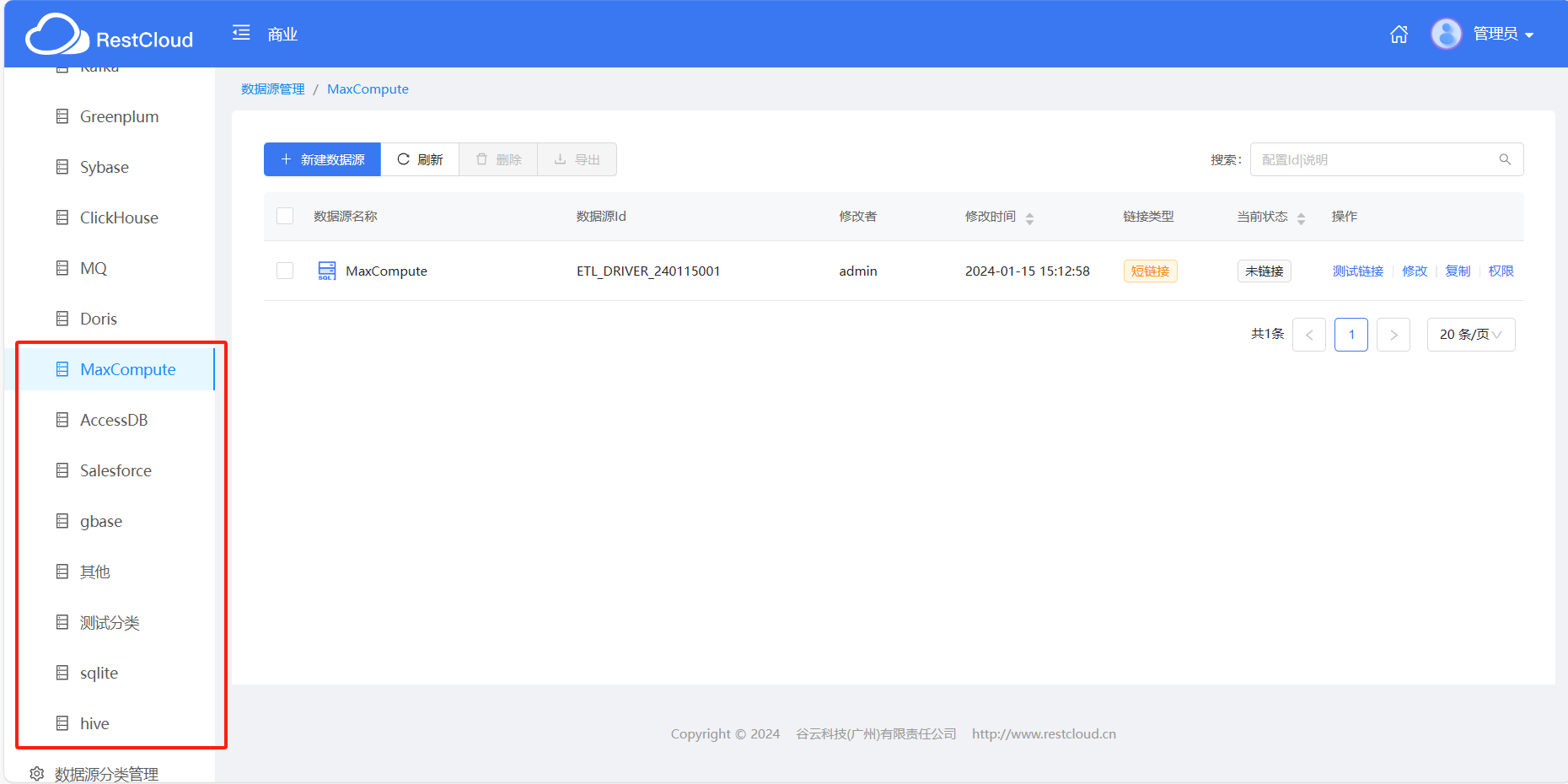
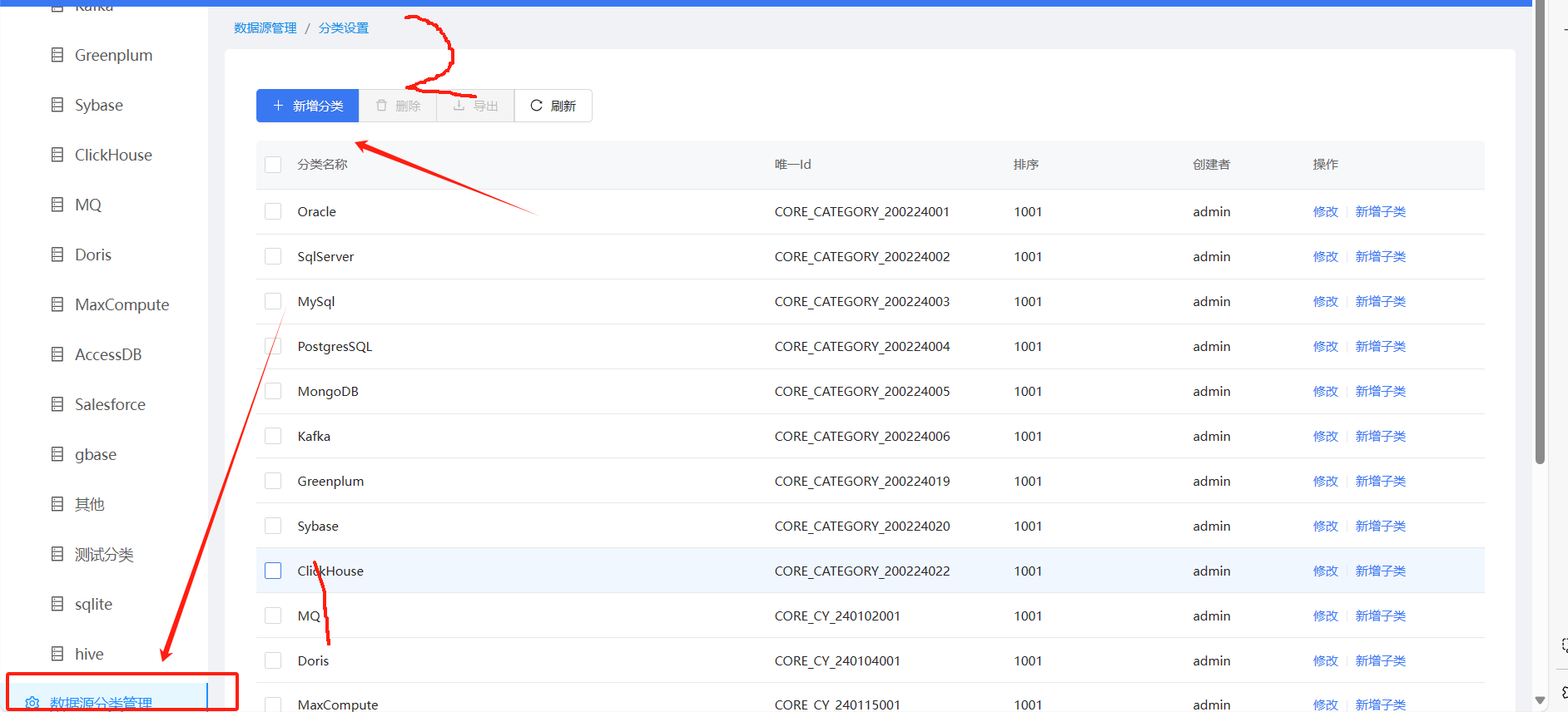
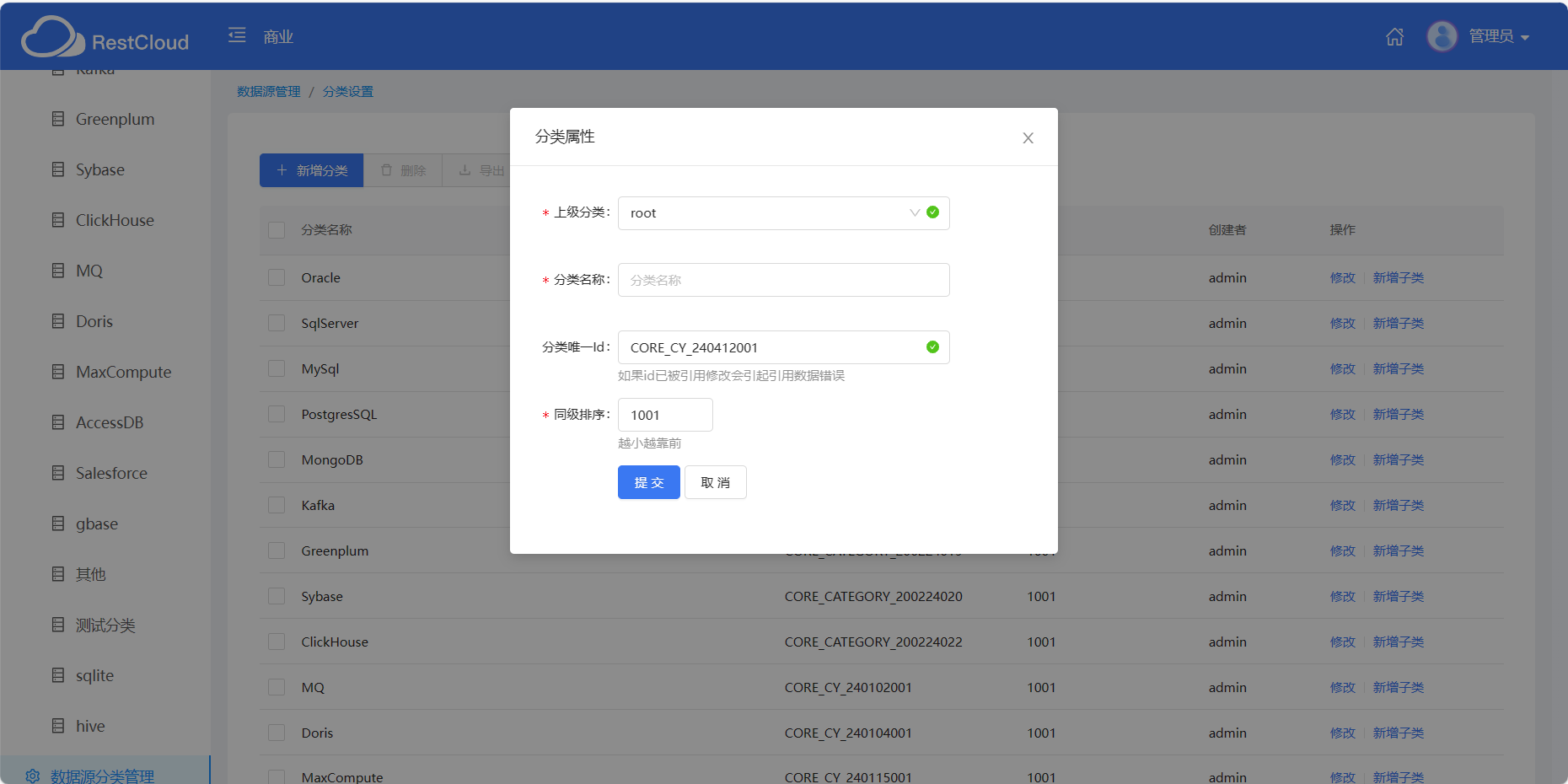
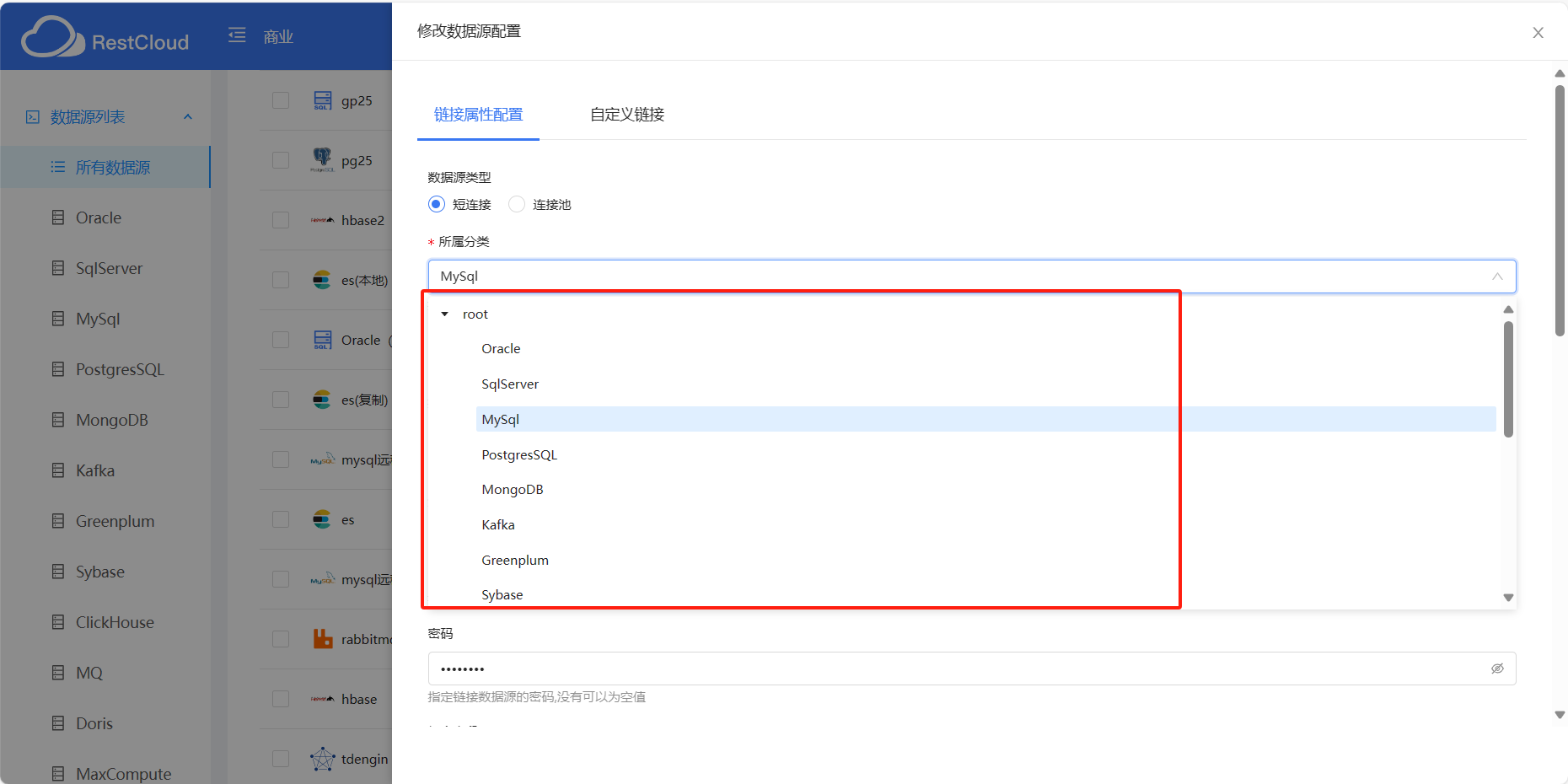
除了mysql之外还有一些其他数据库用户在配置的时候也经常出错
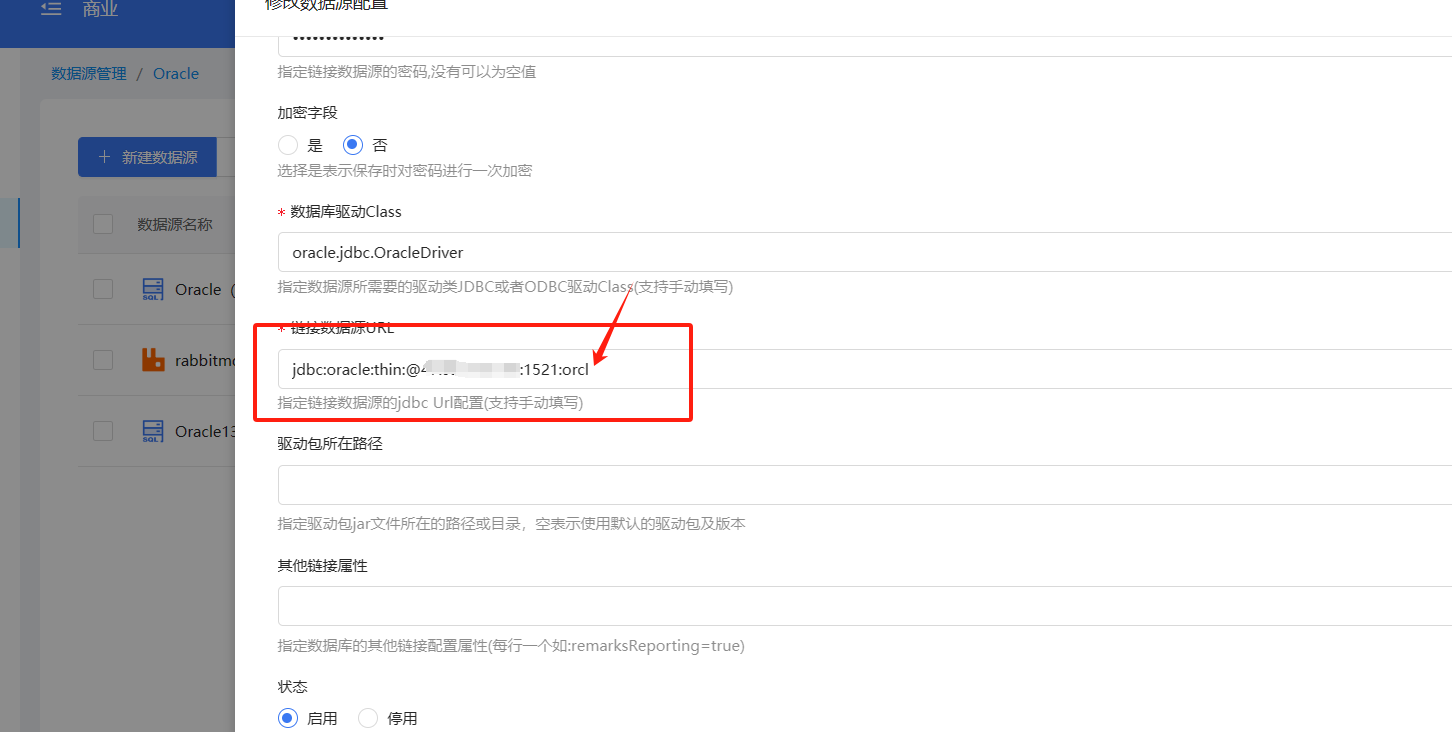
Oracle数据源注意后面的填写
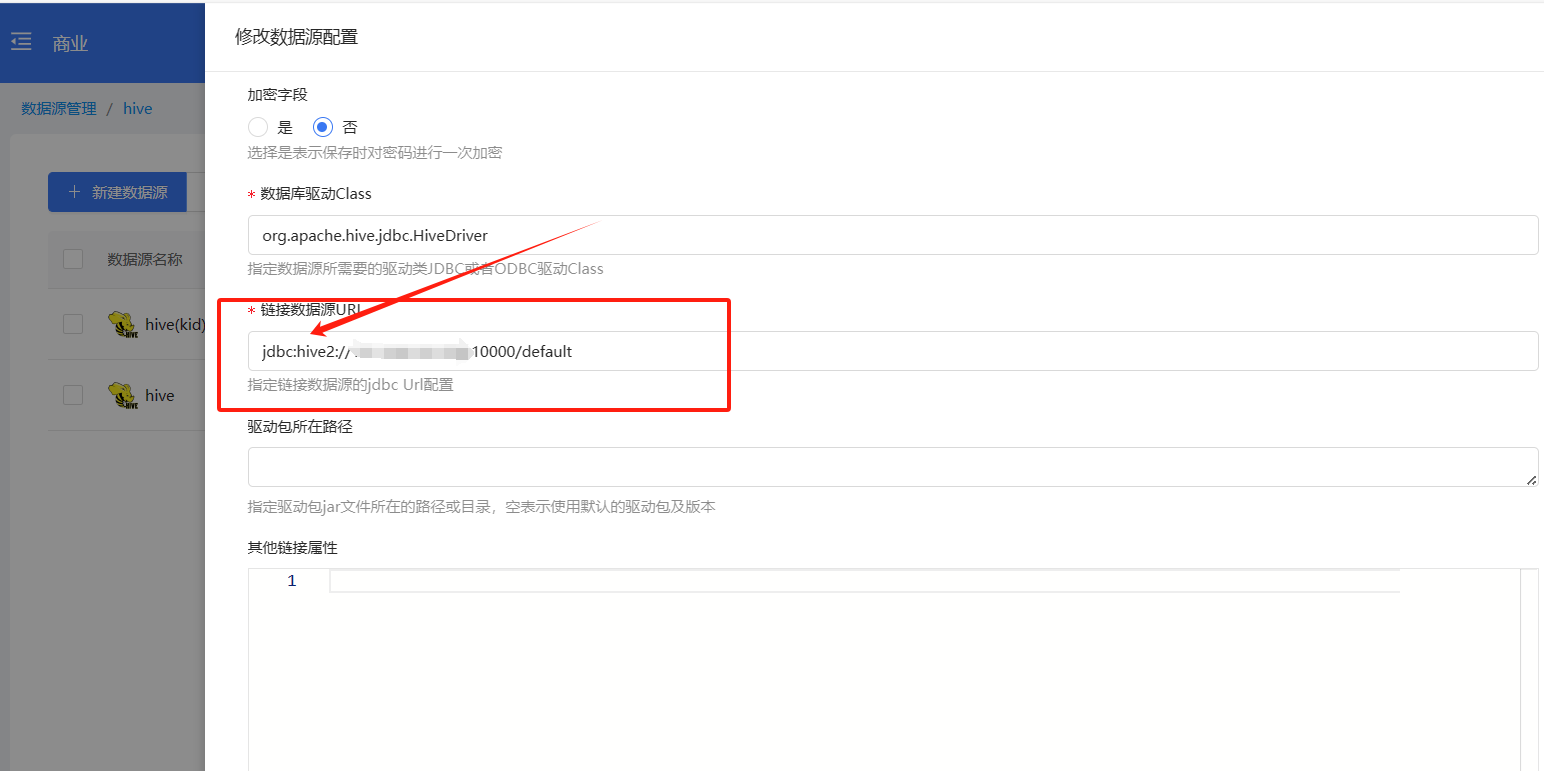
hive注意 jdbc后面是hive2
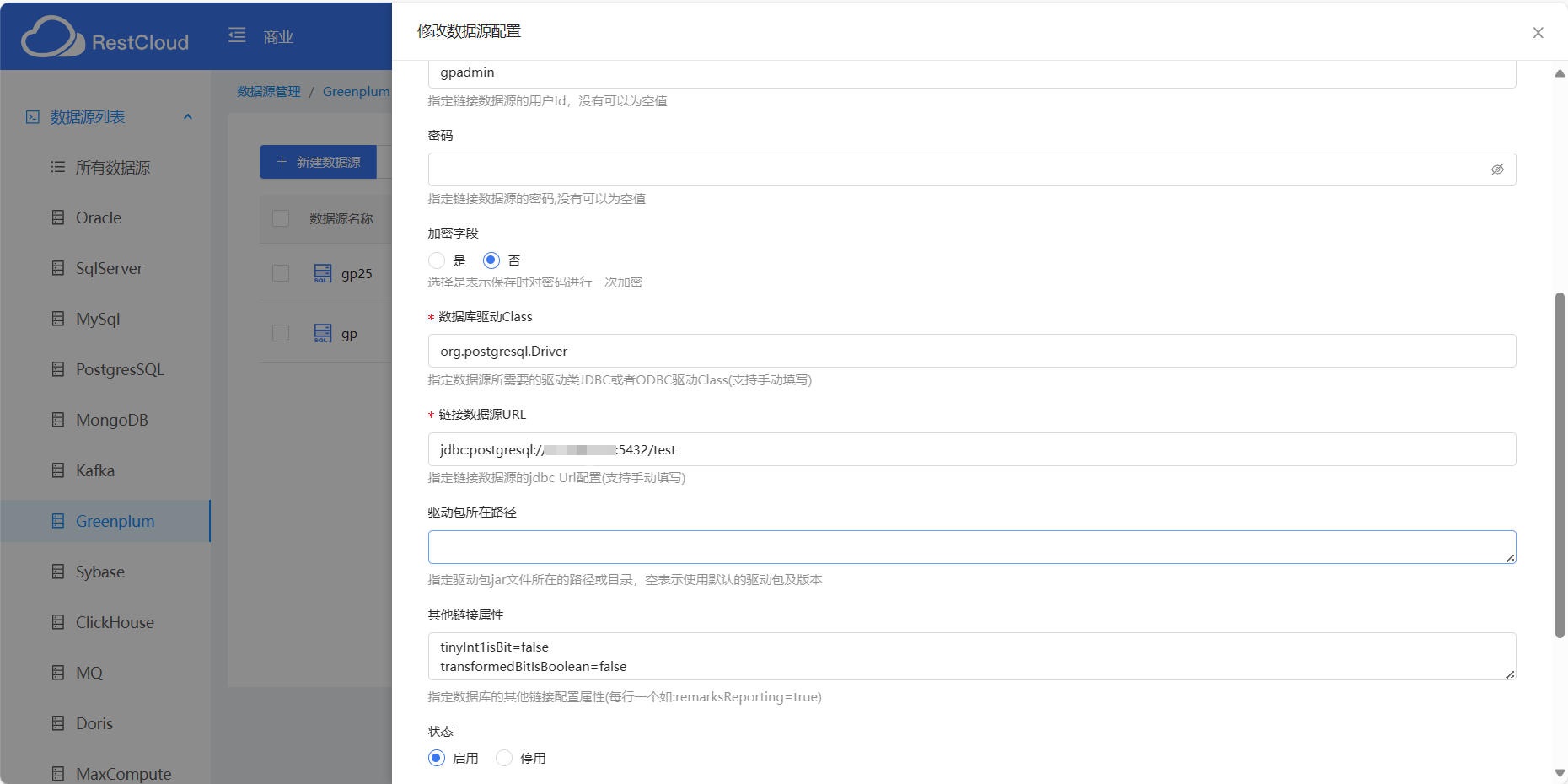
Greenplum和PostgresSql 驱动类和url开头都是一样的
常见问题
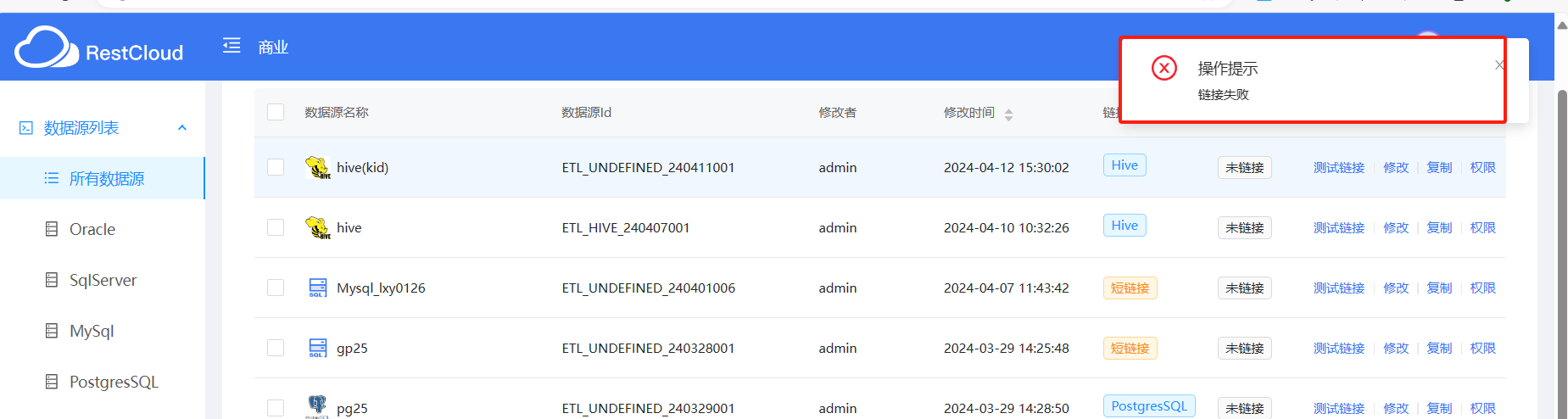
链接失败:一般是数据源没有配置好,检查一下自己的用户、密码什么的。或者用其他数据库连接工具测试一下看看能不能连上数据库,端口原因也要注意一下
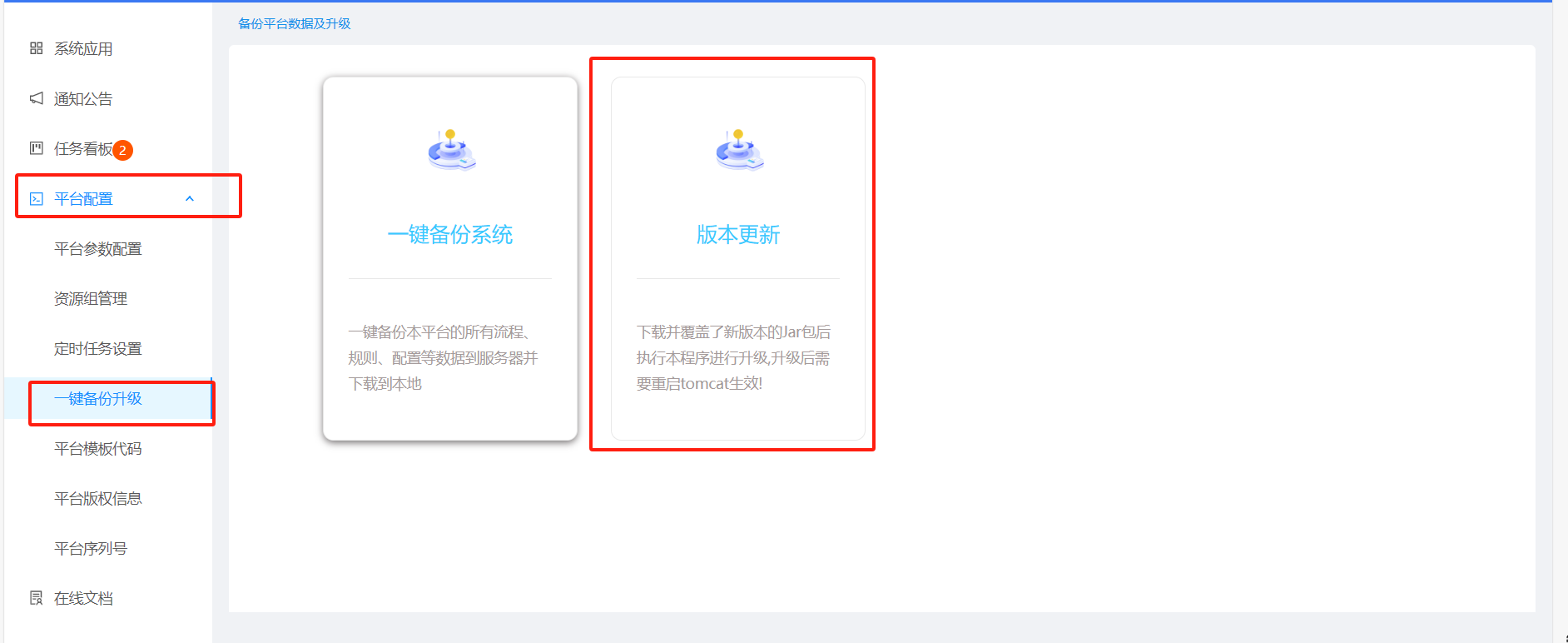
端口加载失败:一般发生在3.0版本,执行更新、清理浏览器缓存、然后重新启动即可
为什么不是全部数据都来自数据源,因为平台还支持API输入输出,此外平台的流程也可以发布为API,可以从API接口拿数据和返回数据。
总结
-
数据源概念与位置:数据源作为ETL流程的起点,为数据抽取提供源头,大部分数据由此获取。在系统中,数据源位于“数据源管理”模块内。
-
新建数据源步骤:点击“新建数据源”,展示多种类型的数据源供选择,如MySQL、Oracle等。以MySQL为例,配置过程包括:
-
填写基本参数:标记“\*”的字段为必填项,如数据库名称、用户名、密码等。
-
数据库驱动与URL
数据库驱动class:若列表中无所需驱动,可通过搜索“xxxx数据库的jdbc驱动class”获取。所有关系型数据库基于JDBC开发,确保正确填写。
数据源URL:参考示例进行填写,替换“localhost”或“127.0.0.1”为实际数据库服务器IP地址,尤其注意端口后的部分要对应个人数据库信息。
- 驱动包路径与连接属性:
驱动包所在路径:非必填项,用于在默认驱动包无法满足需求时,指定自定义驱动包的路径。
其他连接属性:可选填,用于配置特定参数以优化数据库连接性能。
数据源分类:平台预设了数据源分类,用户可根据需求创建新的分类,以便于管理和区分不同数据源。
- 注意事项:
Oracle数据源:注意URL末尾的特定格式。
Hive数据源:URL中“jdbc”后需添加“hive2”。
Greenplum和PostgreSQL:两者驱动类和URL开头相同,需正确填写。
这篇关于4.19【编号231】ETLCloud中数据源使用和管理的技巧的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







