本文主要是介绍Flink KafkaSink分区配置的不同版本对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flink KafkaSink分区配置的不同版本对比
在不同版本的Flink中,KafkaSink 分区默认配置方式可能会有一些变化。以下是摘自Flink官方文档不同版本的原文:
1. Flink版本:1.12~1.19
Sink 分区 #
配置项 sink.partitioner 指定了从 Flink 分区到 Kafka 分区的映射关系。 默认情况下,Flink 使用 Kafka 默认分区器 来对消息分区。默认分区器对没有消息键的消息使用 粘性分区策略(sticky partition strategy) 进行分区,对含有消息键的消息使用 murmur2 哈希算法计算分区。
为了控制数据行到分区的路由,也可以提供一个自定义的 sink 分区器。‘fixed’ 分区器会将同一个 Flink 分区中的消息写入同一个 Kafka 分区,从而减少网络连接的开销。
2. Flink版本:=1.11
Kafka Producer 分区方案
配置选项sink.partitioner指定了从Flink的分区到Kafka的分区的输出分区。默认情况下,Kafka sink最多写入与其自身并行度相同的分区(每个sink的并行实例将写入到一个分区)。为了将写入分布到更多分区或控制将行路由到分区,可以提供自定义的sink分区器。循环分区器对于避免不平衡的分区很有用。然而,它将导致所有Flink实例和所有Kafka代理之间之间有大量的网络连接。
3. Flink版本:<=1.10
Kafka Producer 分区方案
默认情况下,如果没有为 Flink Kafka Producer 指定自定义分区程序,则 producer 将使用 FlinkFixedPartitioner 为每个 Flink Kafka Producer 并行子任务映射到单个 Kafka 分区(即,接收子任务接收到的所有消息都将位于同一个 Kafka 分区中)。
可以通过扩展 FlinkKafkaPartitioner 类来实现自定义分区程序。所有 Kafka 版本的构造函数都允许在实例化 producer 时提供自定义分区程序。 注意:分区器实现必须是可序列化的,因为它们将在 Flink 节点之间传输。此外,请记住分区器中的任何状态都将在作业失败时丢失,因为分区器不是 producer 的 checkpoint 状态的一部分。
也可以完全避免使用分区器,并简单地让 Kafka 通过其附加 key 写入的消息进行分区(使用提供的序列化 schema 为每条记录确定分区)。 为此,在实例化 producer 时提供 null 自定义分区程序,提供 null 作为自定义分区器是很重要的; 如上所述,如果未指定自定义分区程序,则默认使用 FlinkFixedPartitioner。
总结:根据Flink 官方文档提供的信息,可见Flink不同版本在处理写Kafka分区的默认配置是有区别的:
Flink版本 >=1.12:
- 默认情况下,Flink使用Kafka默认分区器来对消息进行分区。 也就是 kafka 的粘性分区策略
Flink版本 <=1.11:
- 默认情况下,Kafka sink最多写入与其自身并行度相同的分区,默认使用 FlinkFixedPartitioner。
*重点介绍一下粘性分区策略
粘性分区程序通过选取单个分区来发送所有非键化记录,解决了将没有键的记录分散到更小批处理中的问题。一旦该分区的批处理被填充或以其他方式完成,粘性分区程序就会随机选择并“粘附”到一个新分区。这样,在更长的时间段内,记录大约均匀地分布在所有分区之间,同时获得更大批处理大小的额外好处。
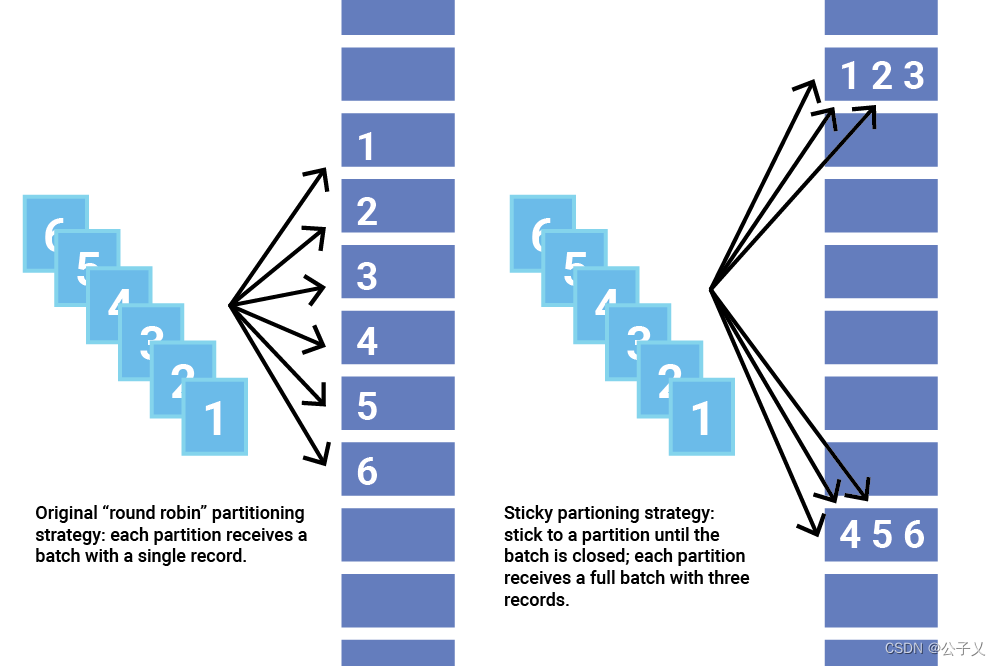
为了更改粘性分区,Apache Kafka 2.4 还在分区器接口中添加了一个名为 onNewBatch 的新方法,以便在创建新批处理之前使用,这是更改粘性分区的最佳时机。DefaultPartitioner 实现此功能。
原文连接地址:Kafka Producer 使用粘性分区策略的改进
这篇关于Flink KafkaSink分区配置的不同版本对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






