本文主要是介绍SFusion论文速读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SFusion: Self-attention Based N-to-One Multimodal Fusion Block
摘要
人们用不同的感官感知世界,例如视觉、听觉、嗅觉和触觉。处理和融合来自多种模式的信息使人工智能能够更轻松地理解我们周围的世界。然而,当缺少模态时,可用模态的数量在不同情况下是不同的,这导致了N对1的融合问题。
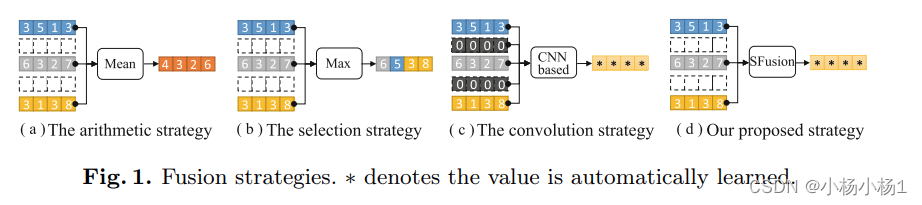
本文提出了一种基于自注意力的融合块,称为SFusion。与预设公式或基于卷积的方法不同,所提出的模块可以自动学习融合可用模态,而无需合成或零填充缺失模态。具体而言,从上游处理模型中提取的特征表示被投影为标记并输入到自注意力模块中以产生潜在的多模态相关性。然后,引入模态注意力机制来构建共享表示,并可应用于下游决策模型。所提出的SFusion可以很容易地集成到现有的多模态分析网络中。
代码地址
方法

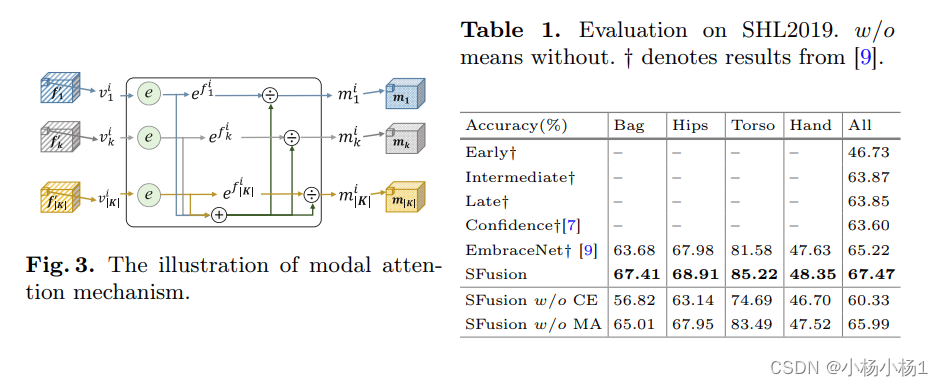
目标是学习一个融合函数 F,它可以将 I 投影到共享特征表示 fs,表示为 F(I) → fs。为了实现这个目标,我们设计了一个N对一的融合块,SFusion。该架构如图2所示,该架构由两个模块组成:相关性提取(CE)模块和模态注意力(MA)模块。
首先是相关性提取模块:
1.将 fk 的 Rf 维数平展为一维
2.然后,我们得到所有标记 z0 ∈ RB×T ×C 的串联,其中 T = R × |K|和|K|表示可用模态的数量
然后是模型的注意力计算:
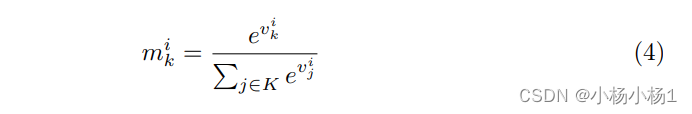
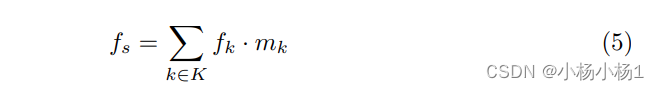
结合图像看这个公式就比较简单了
实验结果
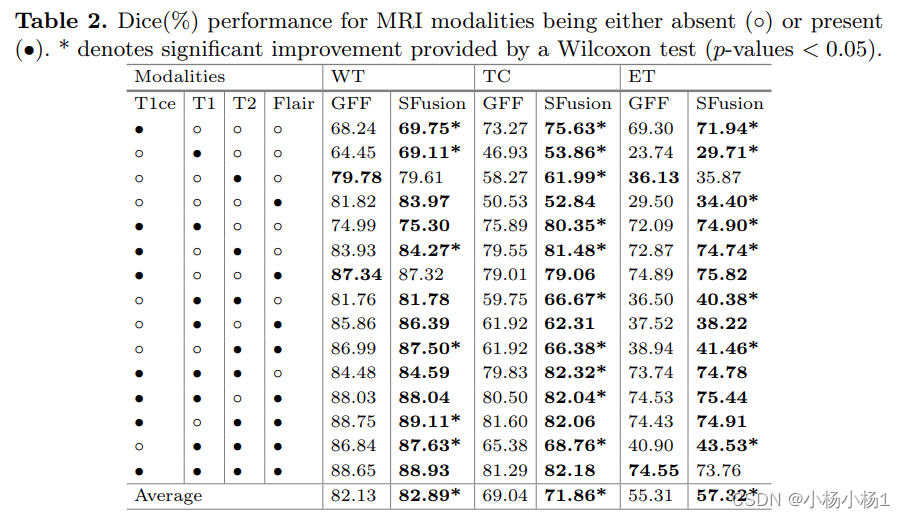
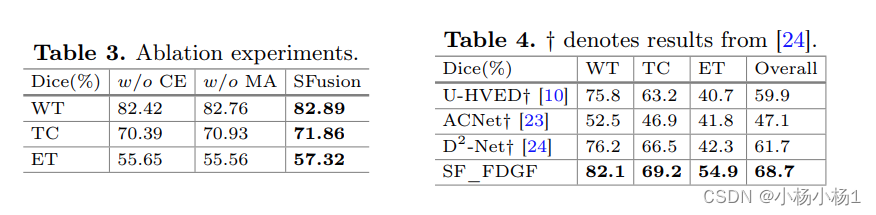
这篇关于SFusion论文速读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


