本文主要是介绍对张孝祥C语言试题其中一题的探讨 (转载),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当《绝对能够测试你的C语言功力的几个问题》第一次出现在CSDN首页时,我就进入了张老师Blog。客观上说,出的题目比较基础,但每一题都说出一个所以然来,恐怕不是很简单。过了几天就贴出了《语言测试题的讲解分析》,我怀着好奇的心情进去看了看。发现里面赞扬的也有,诋毁的也有。韩愈《师说》里面讲过:闻道有先后,术业有专攻。张老师自然有他的可取之处,也有不知道的知识点。 OK,言归正转,现在开始对试题中的第二题进行探讨。题目如下:
| int x=35; char str[10]; strcpy(str,"www.it315.org"/* 共 13 个字母 */); // 问 : 此时 x 和 strlen(str) 的值分别是多少? |
我们先不去探讨答案是多少,但我觉得这题与编译器有关。张老师的答案也不是没有道理,网友秦始皇的回答也有道理。肯定有人开始怀疑了,你到底在说什么?这也对,那也对,究竟什么是对的。好的,我们现在就开始分析。
一、 栈
在具体讲解之前,我们先来明确栈的几个概念:满栈与空栈,升序栈与降序栈。
满栈是指栈指针指向上次写的最后一个数据单元,而空栈的栈指针指向第一个空闲单元。一个降序栈是在内存中反向增长(就是从应用程序空间结束处开始反向增长),而升序栈在内存中正向增长。
RISC机器使用传统的满降序栈(FD Full Descending)。如果使用符合X86规定的编译器,它通常把你的栈指针设置在应用程序空间的结束处并接着使用一个满降序栈。用来存放一个函数的局部变量、参数、返回地址和其它临时变量的栈区域称为栈帧(stack frame)。(关于这部分的详细信息请参看我另外一篇文章《通过Linux内核源码看函数调用之前世今生》)。如图1所示:
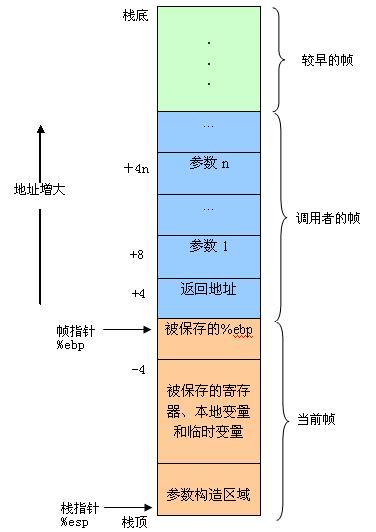
图 1栈帧布局
二、 目标文件格式
各个系统之间,目标文件格式都不相同。第一个从贝尔实验室诞生的UNIX系统使用的是a.out格式。System V Unix的早期版本使用的是COFF(Common Object File Format 一般目标文件格式)。Windows使用的是COFF的一种变种,叫做PE格式(Portable Executable 可移植可执行)。现代Unix――比如Linux,各种BSD ,以及Sun Solaris――使用的是Unix ELF(Executable and Linkable Format,可执行和可链接格式)。尽管以下的讨论集中在ELF上,但不管是哪种格式,基本的概念都是相似的。
如果变量x和str是局部变量,那么肯定是放在栈中。如果他们两者都是全局变量,那么x放在.data段(.data:存放已初始化的全局变量),str放在.bss段(.bss:存放未初始化的全局变量)。
一个典型的ELF可执行目标文件信息布局如图2所示:
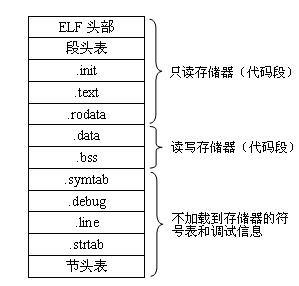
图 2典型的ELF可执行文件格式
每个程序都有一个运行时存储器映像,如图3所示:
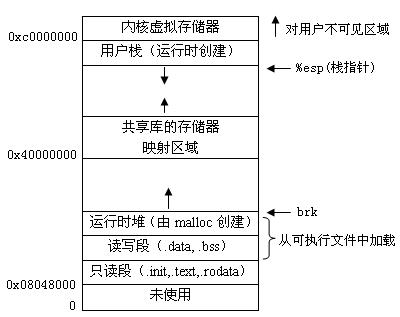
图 3Linux运行时存储器映像
在Linux系统中,代码段总是从地址0x08048000处开始。数据段在接下来的下一个4KB对齐的地址处。运行时堆在接下来的读写段之后的第一个4KB对齐的地址处,并通过malloc库往上增长。开始于0x40000000处的段是为共享库保留的。用户栈总是从地址0xbfffffff处开始,并向下增长的(向低地址方向增长)。从栈的上部开始于地址0xc0000000处的段是为操作系统驻留存储器的部分的代码和数据保留的。通过这里讲解之后,你应该彻底懂得了满降序栈的含义。
三、 寻址与字节顺序
几乎在所有的机器上,多字节对象都以连续的字节序列存放,对象的地址为所使用的字节序列中最小的地址。比如,一个int型的变量x的地址为0x100,也就是说&x=0x100,那么x的四字节将被存储在内存中的0x100,0x101,0x102和0x103。
某些机器选择在存储器中按照从最低有效位字节到最高有效位字节的顺序存储对象,而
另一些机器则按照从最高有效位字节到最低有效位字节的顺序来存储对象。前者我们称为小尾端(little-endian),比如Intel的机器都采用这种规则,后者称为大尾端(big-endian),如IBM,Motorola等机器。
假设x类型为int,地址位于0x100处,有一个16进制的值为0x12345678,分别在大尾端和小尾端的存储方式为:
大尾端:
0x103 0x102 0x101 0x100
| …… | 78 | 56 | 34 | 12 | …… |
小尾端:
0x103 0x102 0x101 0x100
| …… | 12 | 34 | 56 | 78 | …… |
注意,在字0x12345678中,高位字节的16进制为0x12,而低位字节为0x78。不管是在大尾端机器中,还是小尾端机器中,输出的x的值都为0x12345678。
四、 透过汇编代码看变量存储布局
我们从局部变量和全局变量两个方面来,分别在Windows下的VC++6.0和Linux下的GCC来探讨这个题目。
假设程序如下:
| 1 #include <stdio.h> 2 #include <string.h> 3 4 int main() 5 { 6 int x = 35; 7 char str[10]; 8 strcpy(str,"www.it315.org"/*共13个字母*/); 9 printf("%d/n",x); 10 return 0; 11 } |
这段程序在VC++6.0中的反汇编代码如下:
| 1: #include <stdio.h> 2: #include <string.h> 3: 4: int main() 5: { 00401010 push ebp 00401011 mov ebp,esp 00401013 sub esp,50h 00401016 push ebx
00401017 push esi 00401018 push edi 00401019 lea edi,[ebp-50h] 0040101C mov ecx,14h 00401021 mov eax,0CCCCCCCCh 00401026 rep stos dword ptr [edi] 6: int x = 35; 00401028 mov dword ptr [ebp-4],23h /*将35压进栈中*/ (1处) 7: char str[10]; 8: strcpy(str,"www.it315.org"/*共13个字母*/); 0040102F push offset string "www.it315.org" (00420020) 00401034 lea eax,[ebp-10h] (2处) 00401037 push eax 00401038 call strcpy (00401100) 0040103D add esp,8 9: printf("%d/n",x); 00401040 mov ecx,dword ptr [ebp-4] (3处) 00401043 push ecx 00401044 push offset string "%d/n" (0042001c) 00401049 call printf (00401080) 0040104E add esp,8 10: return 0; 00401051 xor eax,eax 11: } |
从以上代码可以发现,在1处,将x的值35压入ebp-4中,在运行2处之前,已经将字符串的值压入栈中了,然后获取str在栈的地址,即ebp-10h,也就是ebp-16,文中红色箭头所指的对方。装载到eax寄存器中,然后也压入栈中。众所周知,在X86平台上,参数的传递是通过栈帧来实现的,此时调用函数strcpy,将字符串的值拷贝到str的地址处。那么此时如何存放字符串?就是问题的关键所在。大家可能都知道已知str字符串的地址,那么要得到它下一个字符串的值,就是*(str+1),那么答案就出来了。在X86平台上,栈是往下增长的,那么越往高处就是高地址,当进行字符串拷贝时,字符串的地址顺着蓝色的线朝上走。因为该字符串长度为13,所以覆盖了x所在的栈中的值,最后一个字符g也就赋给了x,由于在Intel的机器中,采用的是小尾端存储方式,所以值在栈中的布局如图4所示:
| 栈帧布局 高地址
低地址 |
图 4字符串在栈中的布局
当运行到3处时,程序将ebp-4处的值,也就是x的值压入栈中,调用printf,所以打印出来的为103(也就是g的值)。
在Linux环境下,GCC编译器似乎表现的技高一筹,得到的答案是35。下面我们来看反汇编后的代码:
| .file "sttest.c" .section .rodata .align 32 .LC0: .string "www.it315.org" .string "" .LC1: .string "%d/n" .text .globl main .type main, @function main: pushl %ebp movl %esp, %ebp subl $56, %esp andl $-16, %esp movl $0, %eax subl %eax, %esp movl $35, -12(%ebp) /*将35放到栈中,即x处*/ (1处)
movl $.LC0, 4(%esp) leal -40(%ebp), %eax (2处) movl %eax, (%esp) call strcpy movl -12 (%ebp), %eax (3处) movl %eax, 4(%esp) movl $.LC1, (%esp) call printf movl $0, %eax leave ret .size main, .-main .section .note.GNU-stack,"",@progbits .ident "GCC: (GNU) 3.3.5 (Debian 1:3.3.5-13)" |
我们从2处可以发现,str的位置在ebp-40处,取得str在栈中的地址,然后放到堆栈指针处,调用strcpy,此时我们不难发现x的地址和str的地址相差40-12=28,远远大于字符串的长度,所以根本不可能覆盖x的值。如果你将字符串的长度改为29个字符,那么就将会覆盖x的值。
下面,我们来讨论x和str为全局变量的情况,也就是将6,7两行代码提到第3行处。
在第二节中,我们讨论过x放在.data段,str放在.bss段,从图三中可以观察出,读写段(.data,.bss)位于低地址处。对于ELF文件,一般会规定代码段的总长度大小,低地址处是.data段,因为.data是已经固定了的,而.bss段是在运行时才会赋值,所以代码段剩下的空间都是.bss的大小,注意此时.bss段的地址大于.data段的地址,所以为.bss中的变量赋值时,根本不可能覆盖.data段的值。把图2倒过来看,大家就会明白了。所以,如果x和str是全局变量,str的值永远不可能覆盖x的值。
五、 总结
其实每一道题目后面都隐藏着很多知识,我们不能只看表面,大概差不多就行了。只要我们深究下去,可以获得比题目本身更多的知识点。
六、 附录
在Windows中,程序运行时存储器映像的资料比较少,我到目前只在《编程卓越之道:深入理解计算机》一书中提及过。所以凭我的印象画下了该图:

图 5程序在Windows中运行时的存储器映像
这篇关于对张孝祥C语言试题其中一题的探讨 (转载)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




