本文主要是介绍关于如何理解Glibc堆管理器(Ⅱ——Free与Bins),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇实为个人笔记,可能存在些许错误;若各位师傅发现哪里存在错误,还望指正。感激不尽。
若有图片及文稿引用,将在本篇结尾处著名来源。
目录
Free与Bins:
SmallBin
LargeBin
UnsortedBin
Fast Bin
TcacheBin
额外说明
Free与Bins:
malloc如果一旦和free混用,情况就变得复杂了。我们可以先思考一下下面的问题:
如果只能malloc的话,那么内存最终必然会被消耗殆尽,因此free函数的存在是必须的。
假设我连续申明了A,B,C,D四个chunk,并且现在释放掉了B
倘若我现在需要申请一块刚好比B大16字节的chunk E,那么B就不能使用了,我们只能从C后面去找
又倘若这种情况非常多,那么就可能会有很多的内存被这样浪费掉了
如果我们现在又释放掉了C,那么E就能够从A和D之间申请了,但操作系统如果没有将B和C进行合并,那么就会以为是两块刚好不足的内存,我们仍然只能从D后面去找地方开辟空间,就会浪费更多的内存。
为了解决包括上述问题在内的诸多浪费问题,free有一套明确的策略(适用于教早的版本,与现代稍有出入,但思路是一致的):
1.如果Size中M位被标记,表明chunk由mmap分配,则直接将其归还给系统
2.否则,如果该chunk的P位未标记,表明上一个chunk处于释放,向上合并成更大的chunk
3.如果chunk的下一个chunk未被使用,则向下合并为更大的chunk
4.如果chunk与Top Chunk相邻,就直接与其合并
5.否则,放入适当的Bins中
现代堆管理器建立了一系列的Bins以储存不久前被释放的chunk,包括:SmallBin,LargeBin,UnsortedBin,FastBin,TcacheBin,前三种是最古老的版本,而后两种则是近代为了进一步优化效率而产生的,现在的管理器使用这五种来处理释放chunk的操作
struct malloc_chunk {INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free).*/INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead.*/struct malloc_chunk* fd; /* double links -- used only if free. */struct malloc_chunk* bk;/* Only used for large blocks: pointer to next larger size. */struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */struct malloc_chunk* bk_nextsize;};
//再次抄写以方便查阅SmallBin:
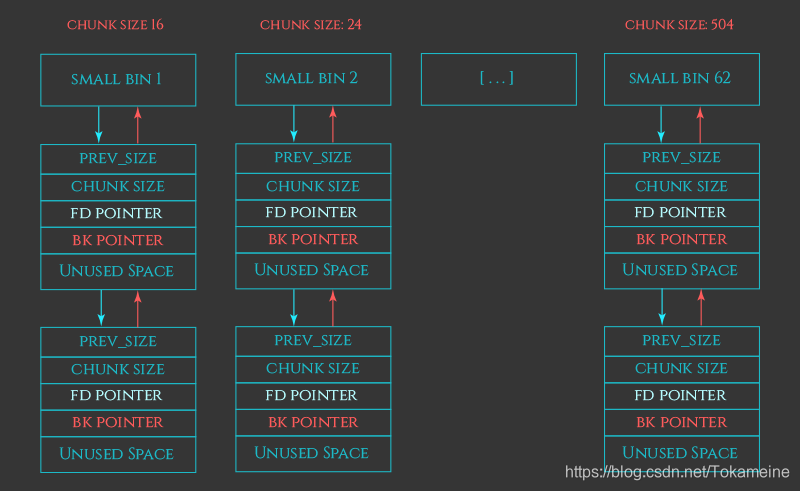
SmallBin共有62个。在 32 位系统上,小于 512 字节(或在 64 位系统上小于 1024 字节)的每个块都有一个相应的小 bin。由于每个小 bin 仅存储一种大小的块,因此它们会自动排序
这些块则通过显示链表相互连接,通过FD POINTER和BK POINTER形成双向链表
struct malloc_chunk* fd; /* double links -- used only if free. */struct malloc_chunk* bk;在上一章中介绍过chunk的结构体,其中非常驻的前两个成员则在chunk被释放后发挥作用
由于我们已经不会再使用这个chunk了,因此操作系统能够直接覆盖掉原本的数据来为该chunk建立两个指针,并将它挂进链表的头部(取出时也从头部取出)
LargeBin:
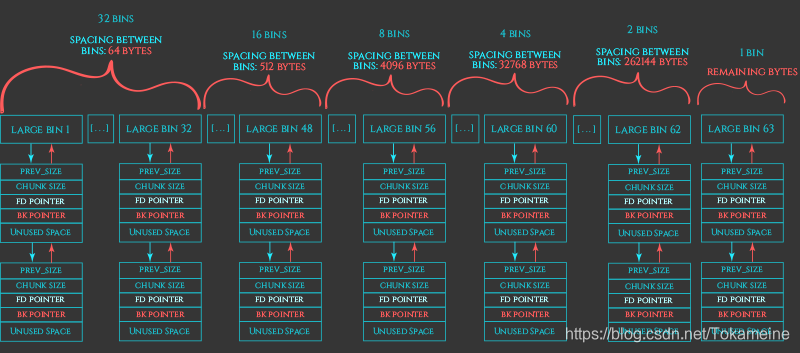
总共63个。其存放的规则如图所示。由于它不像Small Bin那样每个Bin中只有固定大小的chunk,因此在Large Bin中会对chunk进行排序
struct malloc_chunk* fd; /* double links -- used only if free. */struct malloc_chunk* bk;/* Only used for large blocks: pointer to next larger size. */struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */struct malloc_chunk* bk_nextsize;同时,在Large Bin中,最后两个指针也会发挥作用。
它们分别指向:下一个小于该大小的chunk和下一个大于该大小的chunk
且,最大的堆头的bk_nextsize指向最小的堆头;最小的堆头的fd_nextsize指向最大的堆头
例如:Bin 2中的第一个chunk的fd指针一个指向Bin 1中的第一个
(注:这两个指针仅对链表的头结点有意义,其他节点则没有这两个指针)
UnsortedBin:
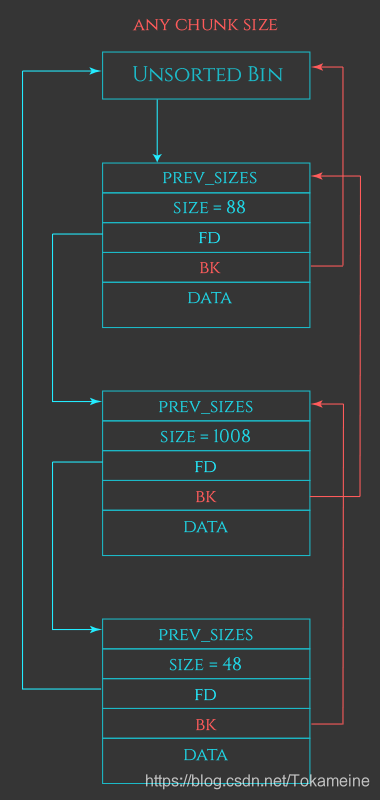
结构如图,只有一个。其由来的解释摘抄自下文:
The heap manager improves this basic algorithm one step further using an optimizing cache layer called the “unsorted bin”. This optimization is based on the observation that often frees are clustered together, and frees are often immediately followed by allocations of similarly sized chunks. For example, a program releasing a tree or a list will often release many allocations for every entry all at once, and a program updating an entry in a list might release the previous entry before allocating space for its replacement.
大致意思就是:用户常常在释放资源后立刻由进行了一系列分配(比方说二叉树之类的,其更新需要释放又申请),如果立刻讲这些chunk放进Small Bin或者Large Bin,那上述情况的开销就会过大,延缓程序运行。因此程序会先从这个Bin中去寻找合适的chunk返回,如果没有合适的,才去其他Bins中寻找,如果还是没找到,那才会采取其他方式
这个链表是不进行排序的。在这个Bin中,堆管理器会立刻合并在物理地址上相邻的chunk。在malloc的时候会优先(如果大小较小,则可能先从Fast Bin开始)遍历这个Bin去找合适的内存地址
需要注意的是,malloc从该Bin中获取chunk的途径是 切割该Bin中已有的chunk,将足够大的空间返回给用户,而剩下的空间仍然保存在该Bin中,直到触发特定条件(当其无法满足malloc的申请,就会将所有内容放入合适的Bins中)
(注:先进先出)
Fast Bin:
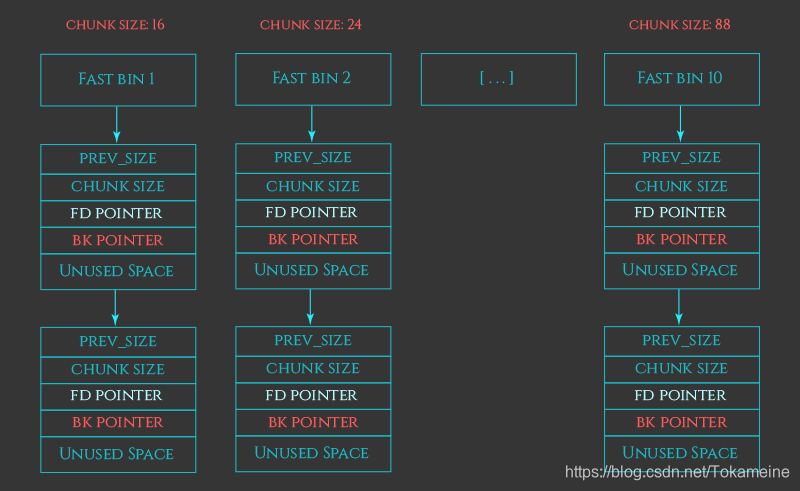
总共10个,均为单向链表,涵盖大小为 16、24、32、40、48、56、64、72、80 和 88 字节的chunk,同样不需要额外的排序操作。
但特殊的是,被放入这里的chunk并不会被标记为“未被利用”,即下一个chunk的P位不会被置零,这种表现像是还未被释放一样。
The downside of fastbins, of course, is that fastbin chunks are not “truly” freed or merged, and this would eventually cause the memory of the process to fragment and balloon over time. To resolve this, heap manager periodically “consolidates” the heap. This “flushes” each entry in the fast bin by “actually freeing” it, i.e., merging it with adjacent free chunks, and placing the resulting free chunks onto the unsorted bin for malloc to later use.
大致意思为:堆管理器会定期整理这个Bin,将其合并后投放到合适的Bin中
This “consolidation” stage occurs whenever a malloc request is made that is larger than a fastbin can service (i.e., for chunks over 512 bytes or 1024 bytes on 64-bit), when freeing any chunk over 64KB (where 64KB is a heuristically chosen value), or when malloc_trim or mallopt are called by the program.
当释放超过64 KB 的任何块时
每当发出大于fastbin可以服务的malloc请求时
程序调用malloc_trim或mallopt时
满足上述三种情况中任意一种,都会触发合并操作
TcacheBin:
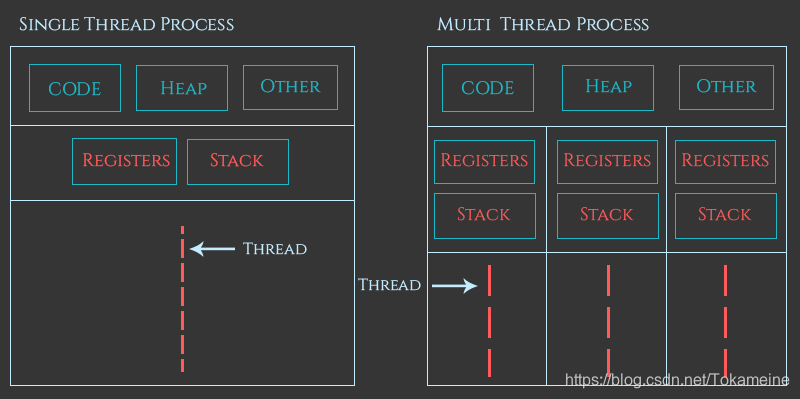
在libc-2.23版本中还未创建这个结构,其主要目的是解决一个进程下多个线程对堆进行的异步操作问题而设计,由于这已经超出了本章内容,因此在这里不做特别说明,具体内容将放在第七章介绍
额外说明:
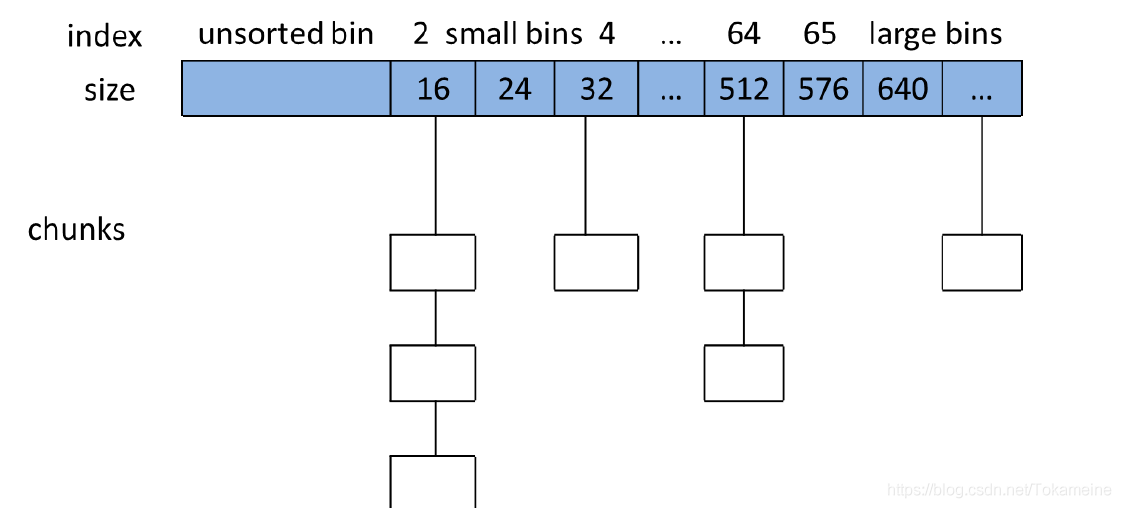
Bins这一系列结构在底层的实现表现为一整个数组
数组的第一个元素指向Unsorted Bin
第二个到第六十三个则为Small Bin,以此类推,大致如下图:
在gdb调试中可以通过bins查看到当前的Bins结构
db-peda$ bins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
unsortedbin
all: 0x0
smallbins
empty
largebins
empty
参考文章:
https://nightrainy.github.io/2019/05/06/glic%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/#bins
https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/
这篇关于关于如何理解Glibc堆管理器(Ⅱ——Free与Bins)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








