本文主要是介绍微服务之LoadBalancer负载均衡服务调用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概述
1.1什么是负载均衡
LB,既负载均衡(Load Balancer),是高并发、高可用系统必不可少的关键组件,其目标是尽力将网络流量平均分发到多个服务器上,以提高系统整体的响应速度和可用性。
负载均衡的主要作用
- 高并发:负载均衡通过算法调整负载,尽力均匀的分配应用集群中的各结点的工作量。从而提升整个应用集群处理并发的能力(吞吐量)
- 伸缩性:添加或减少服务器数量,然后由负载均衡分发控制。使集群具备伸缩性。
- 高可用:负载均衡器可以监控候选服务器,当服务器不可用时,自动跳转,将请求分发给可用的服务器。使服务集群具有高可用特性。
- 安全防护:负载均衡软件或硬件提供了安全性功能;如防护墙,黑名单、防攻击。
1.2负载均衡的分类
负载均衡已出现很久的技术,并不是什么黑科技,根据不同的维度可以进行不同的分类。
从支持负载均衡的载体来看,可以将负载均衡分为两类:硬件负载均衡、软件负载均衡;
硬件负载均衡
硬件负载均衡:一般是在定制处理器上运行的独立负载均衡服务器,价格昂贵,土豪专属。
硬件负载均衡的主流产品:F5Big-IP,Citrix(思杰)Netscaler
硬件负载均衡优点:
- 功能强大:支持全局负载均衡并提供较全面的、复杂的负载均衡算法。
- 性能强悍:硬件负载均衡由于是在专用处理器上运行,因此吞吐量大,可支持单机百万以上的并发。
- 安全性高:往往具备防火墙,防 DDos 攻击等安全功能。
硬件负载均衡缺点:
- 成本昂贵:购买和维护硬件负载均衡的成本都很高。
- 扩展性差:当访问量突增时,超过限度不能动态扩容。
软件负载均衡
软件负载均衡从软件层面实现负载均衡,一般可以在任何标准物理设备上运行,
软件负载均衡主流产品:Nginx、HAProxy、LVS。
- LVS可以作为四层负载均衡器,其负载均衡的性能优于Nginx。
- HAProxy可以作为HTTP和TCP负载均衡器。
- Nginx、HAProxy可以作为四层或七层负载均衡器。
软件负载均衡优点:
- 成本低廉:只要每个Liunx服务器,然后装上Nginx或其他负载均衡软件即可。
- 灵活:7层和4层负载均衡可以根据业务进行选择,有可以根据业务进行比较方便的扩展,比如:由于业务特殊需要做一些定制化的功能。
- 扩展性好:适应动态变化,可以通过添加软件负载均衡实例,动态扩展到超出初始容量的能力
软件负载均衡缺点:
- 性能一般:比起硬件来说支撑并发数不大。
- 功能没有硬件强大
- 安全性没有硬件负载均衡高
1.3Ribbon(过时,了解即可)
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们很容易使用Ribbon实现自定义的负载均衡算法。
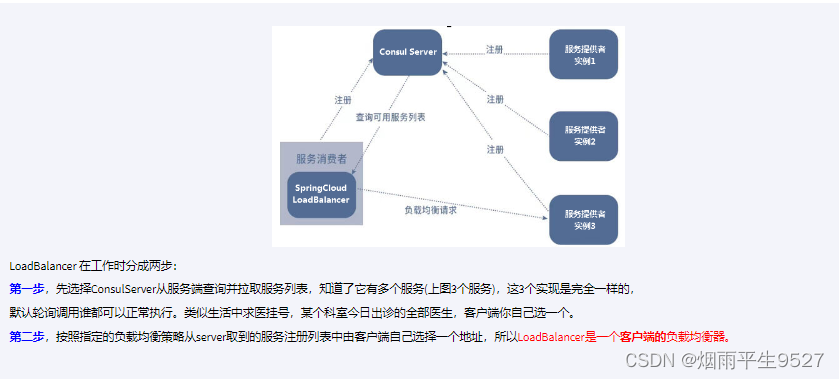
1.4loadbalancer
Spring Cloud LoadBalancer是由SpringCloud官方提供的一个开源的、简单易用的客户端负载均衡器,它包含在SpringCloud-commons中用它来替换了以前的Ribbon组件。相比较于Ribbon,SpringCloud LoadBalancer不仅能够支持RestTemplate,还支持WebClient(WeClient是Spring Web Flux中提供的功能,可以实现响应式异步请求)
官网https://docs.spring.io/spring-cloud-commons/reference/spring-cloud-commons/loadbalancer.html
loadbalancer本地负载均衡客户端 VS Nginx服务端负载均衡区别
Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求,即负载均衡是由服务端实现的。
loadbalancer本地负载均衡,在调用微服务接口时候,会在注册中心上获取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术。
1.5负载均衡算法
负载均衡算法是负载均衡服务核心中的核心。负载均衡产品多种多样,但是各种负载均衡算法原理是共性的。负载均衡算法有很多种,分别适用于不同的应用场景,本文仅介绍最为常见的负载均衡算法的特性及原理:轮询、随机、最小活跃数、源地址哈希、一致性哈希。
轮询(Random)
将请求按顺序轮流地分配到每个节点上,不关心每个节点实际的连接数和当前的系统负载。
优点:简单高效,易于水平扩展,每个节点满足字面意义上的均衡;
缺点:没有考虑机器的性能问题,集群性能瓶颈更多的会受性能差的服务器影响。
随机
将请求随机分配到各个节点。由概率统计理论得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配,也就是轮询的结果。
动态均衡算法
-
最小连接数法
根据每个节点当前的连接情况,动态地选取其中当前积压连接数最少的一个节点处理当前请求,尽可能地提高后端服务的利用效率,将请求合理地分流到每一台服务器。
优点:动态,根据节点状况实时变化;
缺点:提高了复杂度,每次连接断开需要进行计数;
实现:将连接数的倒数当权重值。
-
最快响应速度法
根据请求的响应时间,来动态调整每个节点的权重,将响应速度快的服务节点分配更多的请求,响应速度慢的服务节点分配更少的请求,俗称能者多劳,扶贫救弱。
优点:动态,实时变化,控制的粒度更细,跟灵敏;
缺点:复杂度更高,每次需要计算请求的响应速度;
实现:可以根据响应时间进行打分,计算权重。
-
观察模式法
观察者模式是综合了最小连接数和最快响应度,同时考量这两个指标数,进行一个权重的分配
源地址哈希
根据客户端的IP地址,通过哈希计算得到一个数值,用该数值对服务器节点数进行取模,得到的结果便是要访问节点序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会落到到同一台服务器进行访问。
优点:相同的IP每次落在同一个节点,可以人为干预客户端请求方向;
缺点:如果某个节点出现故障,会导致这个节点上的客户端无法使用,无法保证高可用。当某一用户成为热点用户,那么会有巨大的流量涌向这个节点,导致冷热分布不均衡,无法有效利用起集群的性能。所以当热点事件出现时,一般会将源地址哈希法切换成轮询法。
一致性哈希
主要的特点就是Hash环,我们的请求可以构建成一个Hash环,按照顺时针记录hash和请求。当我们的服务挂了A时,我们只需要将A的请求交给A后面的B处理;当我们需要增加服务器C时,我们只需要在Hash环上划一块范围,然后交给C;这样就可以实现动态的扩容和缩容。一致性哈希用于解决分布式缓存系统中的节点选择和在增删服务器后,节点减少带来的数据缓存的消失与重新分配问题。
二、实战
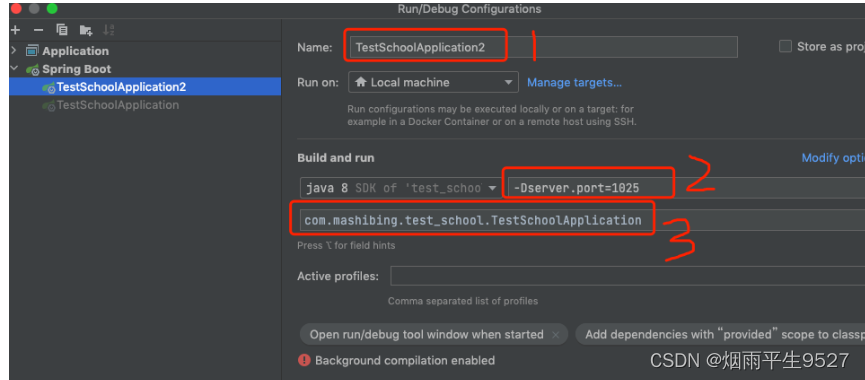
2.1Idea同一套代码,运行多个不同端口的服务
Edit Configurations

点击加号,然后点击SpringBoot

勾选设置

设置
Allow multiple instances(允许开启多个实例)
Add VM options (开启虚拟机选项)
-Dserver.port=3399 (设置实例端口)
-Dxxl.job.executor.port=9998(设置xxl-job端口)我这里因为配置了xxl-job所以需要配置,可以不用写
填写下图中的1,2,3,其中2的端口号与原来的不一样即可
2.2Consu数据持久化配置

2.3负载均衡实现
配置
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>原理
@Resourceprivate DiscoveryClient discoveryClient;@GetMapping("/consumer/discovery")@Operation(summary = "查询")public String discovery(){List<String> services = discoveryClient.getServices();for (String element : services) {System.out.println(element);}System.out.println("===================================");List<ServiceInstance> instances = discoveryClient.getInstances("cloud-payment-service");for (ServiceInstance element : instances) {System.out.println(element.getServiceId()+"\t"+element.getHost()+"\t"+element.getPort()+"\t"+element.getUri());}return instances.get(0).getServiceId()+":"+instances.get(0).getPort();}
负载均衡算法:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标 ,每次服务重启动后rest接口计数从1开始
List<ServiceInstance> instances = discoveryClient.getInstances("cloud-payment-service");
如: List [0] instances = 127.0.0.1:8002
List [1] instances = 127.0.0.1:8001
8001+ 8002 组合成为集群,它们共计2台机器,集群总数为2, 按照轮询算法原理:
当总请求数为1时: 1 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001
当总请求数位2时: 2 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002
当总请求数位3时: 3 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001
当总请求数位4时: 4 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002
如此类推......
2.4 负载均衡算法原理

算法切换
@Configuration // 标记为配置类
@LoadBalancerClient(value = "cloud-payment-service", configuration = RestTemplateConfig.class) // 使用负载均衡器客户端注解,指定服务名称和配置类
public class RestTemplateConfig {@Bean // 定义一个Bean@LoadBalanced // 使用@LoadBalanced注解赋予RestTemplate负载均衡的能力public RestTemplate restTemplate() {return new RestTemplate(); // 返回一个新的RestTemplate实例}@Bean // 定义一个BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, // 注入环境变量LoadBalancerClientFactory loadBalancerClientFactory) { // 注入负载均衡器客户端工厂String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME); // 获取负载均衡器的名称// 创建并返回一个随机负载均衡器实例return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);}
}
这篇关于微服务之LoadBalancer负载均衡服务调用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




