本文主要是介绍分布式K—V系统之我见,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分布式K—V系统之我见
提及分布式key-value存储系统, Memcached, Voldemort, Cassandra,包括淘宝最近开源,我们一直在使用的Tair系统,相信大家都不会觉得陌生。本文会从Tair入手,介绍分析一下传统分布式键-值存储系统的原理,架构和使用技术。错误之处,还望大家指正。
先看一下Tair的架构:
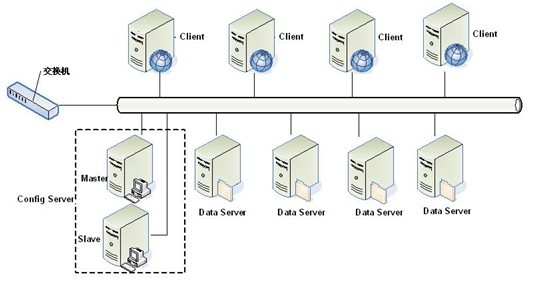
乍一看,会发现Tair的系统架构和TFS一样,都基于了Google的GFS设计,主要包括三部分:

其中ConfigServer主要负责管理维护DataServer以及和Client端的部分通信;
DataServer则是存储对象的地方,数据的增/删/更新都在这里进行;
Client端向服务器请求插入/删除/更新数据;
看完上面的介绍,你可能会有以下几个疑问:
1.configServer的真正工作是什么?
2. DataServer如何存储数据?
3. Client端只需要和dataServer通信吗?
4. 如何实现分布式?
关于上述第四点如何实现分布式键-值存储系统,我们又要从分布式系统CAP要求出发:数据一致性,系统可用性,系统分区宽容度(说白了就是如何解决分布式下Server端机器的增减和容错问题)。这几个问题才是分布式应用中最棘手最重要的问题。
接下来,依据个人的理解,结合Tair相关知识,对上述问题做一下介绍。
首先,tair中的configServer在物理上是以Master-Slaver形式部署,作用大家都很清楚,在Master不可用或者宕机的时候,slaver转为master对外提供服务。那么是不是configServer不能对外部提供就说明所有的客户端都不再可用?答案是否定的,因为configServer在tair中扮演的是一个非常轻量级的角色,如何理解?为解决这个问题,我们需要解决另外一个问题,如何保证来自客户端的数据在tair中均匀的分布,也就是如何对dataServer进行负载均衡,另外,如何保证dataServer的数据不会失效?一个简单的模型就是取模,通过对key的hash值对机器个数取模,将其存储到余数对应的机器上。比如有a,b,c,d四个数据,3台机器,hash取3模后a,c存储到机器1,b存储到机器2,d存储到机器3上。
貌似我们已经解决了问题。经过hash和取模操作后,在大数据量情况下,最后数据在三台机器上的分布肯定是比较均匀的,达到负载均衡的目的了?但是,分布式环境下,当机器量比较多时总是不能避免新机器加入或者某台正在使用的机器不可用了,如果是某台机器不可用,那来自客户端对它的所有请求都会命中失效;这个时候唯一的办法就是将所有的数据重新hash分配,因为取模分母变化了(假设你这个时候对所有数据是有备份的),如果数据量非常大,此项工作也是极其浪费时间的,客户端不可服务时间加长;如果是因为数据量增大,需要新增机器到这个集群中,我们面临的问题一样头疼无助。问题在哪里?因为我们每次取模的单位是机器个数,而机器个数是在不停变化的。所以简单的解决方案就是不要以机器个数取模,取一个恒定不变的值,但是如何应对动态变化的数据?又如何将数据与机器对应起来呢?二次转换是不可避免的了,看来这个解决方案不太可行。
到这里,可能你会问,memcached,cassandra是如何处理这种问题的呢?答案是Consistent Hashing:一致性hash简单的说就是把数据对象和服务器(ip or name)都映射到一个32位的数值空间,即0~232-1,然后将这个范围首尾相连,组成一个圆环。这样,无论是数据还是机器都被映射到如下的圆环上。然后以每个数据为起点,沿顺时针方向找到离其最近的下一个服务器节点,那么这个数据就存储到这台机器上面;一致性,简单理解就是数据和服务器同时hash。如下图所示
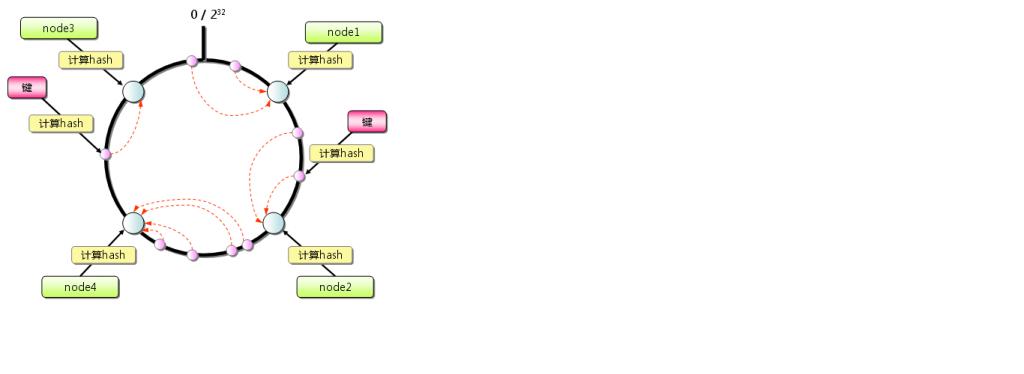
然后,假设node2不可用,按照上述原则,只需要将node1和node2之间的数据迁移到node4上即可;如果在node2和node4之间添加一个节点node5,,只需要将node4和node5之间的数据迁移到node5上,这样,一来保证其他所有结点都是可用的(当然如果要保证当前正在迁移的节点也可用,只需要保证在迁移完成之前数据不删除即可);另外一方面,我们需要迁移的数据量只是其中的一小部分而已,对性能要求不再那么高。然而,当前这个模型还是存在一个问题,如何保证数据在各个节点上分布平衡?一种完善方案是对每个节点设置多个虚拟的结点,以其ip+后缀hash均匀映射到圆环的各处。这样原本可能存储很多数据的节点就有可能被虚拟节点分成,从而达到一定的数据平衡。
Consistent Hash实现其实不复杂,可以参照以下例子:
了解了传统应用的分布式负载均衡算法,但是查看tair源码你会发现它其实没有用到一致性hash算法;它采用了另外一种解决方案。那就是ConfigServer。它通过configServer生成关于各个dataServer的对照表。对照表的数据结构是数据的key和各台dataServer的ip映射表;当然,为了保证容错,每个数据除了在主dataServer上存储数据,还会存储在多个副dataServer上,这样,如果主dataServer失效,那么副dataServer就升级成为主dataServer,主-备之间切换变得很容易,所以在对照表中,还会有多列ip列表对应该数据在副dataServer上的存储节点;此外,一个对照表需要一个版本标识,以便客户端更新;
每次configServer生成一个新的对照表后,会通过心跳方式将新的对照表同步到各台dataServer。而客户端在第一次连接tair时会先去configServer请求,configServer将最新的对照表返回给客户端,客户端将其缓存到本地。当client有数据请求时,只会去本地对照表查找对应的dataServer,然后和定位的dataServer通信,所以之前我们说即便是configServer暂时不可用,client端依旧可用。在这整个过程中,client和server端的通信都是通过基于TCP的Socket进行的,所以只要你的客户端是支持Socket的编程语言,都可以使用tair。当然,在这整一个过程当中,会有一些问题:当dataServer发生变化时,configServer会重新生成新的对照表,如果此时client端请求数据操作,一种情况是原本的dataServer不可用,此时client端会主动去configServer请求新的对照表版本;如果此dataServer依旧可用,但是在处理来自dataServer的response时出校验client端和server端的对照表版本不一致时,client也会主动去configServer请求更新对照表。
然而,即便是这样,我们的tair似乎还是不满足一点:数据在各个节点上平衡。一致性哈希采用的是虚拟结点来改善不平衡数据的问题,而tair和我们知道的Cassandra都是通过分析各个节点的负载情况,从而调整节点的数据平衡问题;
对于ConfigServer和它的作用我们已经说的差不多,接下来看看DataServer:
DataServer其实也是Master_Slaver复制模式。Master除了处理来自客户端的数据操作请求,和configServer通信,听从configServer调遣(比如各个节点间数据迁移以达到尽可能的负载均衡),还要负责将数据更新操作复制到它的slaver上。当然,dataServer需要做到非常重要的一点:高效的读写数据性能。
还是先来看一下tair存储引擎是如何实现的:tair将存储引擎抽象化,也就是说你可以在tair中使用自己实现的存储引擎,或者是换成mysql(当然性能不一定能保证)。目前tair主要有两个存储引擎:基于内存的key-value存储mdb和基于文件的key-value存储fdb。
Mdb实现类似memcached,使用到了slab内存管理技术,每个slab一个内存块,包含了多个chunk,通过slab技术,减少了内存碎片,大大提高了内存使用率。但是mdb优于memcached的优点是它支持shared memory,所以即便是重启服务,数据在共享内存中,也不会使命中率降低很多,而memcached一旦重启,之前所有数据都会miss。
Fdb是一个高效的持久化存储引擎,采用了树型的数据结构存储数据索引。
为了快速访问到文件数据,首先以数据key的哈希值索引数据,同时将索引文件和数据文件隔离开,然后将索引文件放到内存中,减少io操作。这里可以看一下Cassandra数据的本地持久化实现原理:它将客户端提交的数据写到内存中,当内存中数据达到一定量时才会写入到本地文件中,然后有后台合并进程负责对这些文件的合并。在对磁盘数据进行检索时会先去内存中查找,没有才到本地文件中搜索。为了快速查找文件,Cassandra使用了搜索引擎中用到的词典技术,将所有数据的key缓存到内存中,这样可以通过查询词典快速访问到数据在磁盘中的位置。此外,Cassandra还用到了很多非常优秀的开源技术,比如我之前介绍的ZooKeeper,还有用于检测故障的Accrual,非堵塞NIO技术等。由此可见,很多分布式的K-V数据存储系统实现都是非常类似的。
关于tair,有些人说它有点“四不像”,除了我们之前提到的存储引擎,有点像Cabinet的TCMDB和TCHDB,其系统架构又和GFS如此雷同,还有我们下面会提及的一些类似Memcached的其他功能:
支持原子的计数功能,这个在分布式应用中应用十分广泛;
支持数据版本:存储在tair中的每个数据都是带有一个版本号的。正因为如此,它解决了多线程并发的读写难题,版本号的作用有点类似于我们常见的文件锁的功能。
目前对tair和相关k-v存储系统的了解就谈这些,有问题欢迎大家一起交流。
这篇关于分布式K—V系统之我见的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








