本文主要是介绍Towards Street-Level Client-Independent IP Geolocation(2011年)(第二部分),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

被引次数:306
Wang Y, Burgener D, Flores M, et al. Towards {Street-Level}{Client-Independent}{IP} Geolocation[C]//8th USENIX Symposium on Networked Systems Design and Implementation (NSDI 11). 2011.
接着Towards Street-Level Client-Independent IP Geolocation(2011年)(第一部分))
4 Evaluation
4.1 Datasets
我们使用了三个不同的数据集,PlanetLab地图、residential地图和online maps,我们将在下面解释。与大型online maps数据集相比,PlanetLab和residential数据集中的目标数量相对较少。然而,这两个数据集帮助我们获得关于我们的方法在不同环境下的性能的有价值的见解,因为online maps数据集可以包含这两种类型的目标。
4.1.1 Planetlab dataset
一种常用的评估IP地理定位系统精度的方法是对PlanetLab的节点进行地理定位,例如,[17,24]。由于这些节点的位置是公开已知的(大学必须报告其节点的位置),因此可以直接将我们的系统给出的位置与PlanetLab数据库提供的位置进行比较。我们从PlanetLab中选择88个节点,限制每个位置最多一个节点。其他的(例如,[17])已经在给定的PlanetLab位置上观察到了错误。因此,我们可以手动验证所有节点的位置。
[17] KATZBASSETT, E., JOHN, J. P., KRISHNAMURTHY, A., WETHERALL, D., ANDERSON, T., AND YATIN. Towards ip geolocation using delay and topology measurements. In IMC, ’06.
[24] WONG, B., STOYANOV, I., AND SIRER, E. G. Octant: A comprehensive framework for the geolocalization of internet hosts. In NSDI, ’07.
4.1.2 Residential dataset
由于PlanetLab节点的集合都位于学术网络上,我们也需要在residential网络上验证我们的方法。事实上,许多IP地理定位的主要应用都是针对residential网络上的用户。为了做到这一点,我们创建了一个网站,我们让我们的社交网络广泛分布在美国各地。该网站自动记录用户的IP地址,并允许他们输入他们的邮政地址和访问提供商。特别是,我们为供应商提供了六个选择: AT&T、Comcast、Verizon、其他互联网服务提供商(ISPs)、大学和未知公司。此外,我们明确要求用户,如果他们是通过代理、VPN访问本网站,或者如果他们不确定他们的连接,则不要输入他们的邮政地址。然后,我们通过社交网络将该链接分发给许多人,并获得了231对IP地址和位置对。
接下来,我们删除重复的IPs,即在实验过程中无法访问的“死亡”IPs,这是在收集数据后的一个月。我们还消除了大量访问方式为“大学”或“未知”的IPs,因为我们打算提取住宅IPs,并与第4.2节中的学术IPs进行比较。淘汰后,我们剩下72个IPs。
4.1.3 Online Maps dataset
我们从一个流行的online maps服务中获得了一个大规模的查询跟踪。这个数据集包含了为期三个月的用户对驾驶方向的搜索日志。(我们尊重这家在线地图服务公司的请求,并且不会在这里和论文的其余部分中披露请求和收集的IPs的数量。)每条记录由用户访问IP地址、用户侧的本地访问时间、用户浏览器代理,以及由两对经纬度点表示的驱动序列组成。我们这里的假设是,如果我们观察到一个位置,作为驱动序列中的源或目的地,周期性地与一个IP地址相关联,那么这个IP地址很可能就在那个位置。为了从数据集中提取这种关联,我们采用了一系列严格的启发式方法,如下所示。
我们首先排除与多个浏览器代理相关联的IP地址。这是因为目前尚不清楚这个IP地址是仅由一个具有多个浏览器的用户使用,还是由不同的用户使用。然后,我们选择一个位置在三个月中至少出现四次的IP地址,因为这些具有“稳定”搜索记录的IP地址比只有少量搜索记录的IP地址更有可能提供准确的地理位置信息。我们进一步删除了与至少出现四次的两个或多个位置相关联的IP地址。最后,我们从剩余的数据集中删除所有“死”IPs。
4.1.4 Dataset characteristics
在这里,我们的目标是探索这三个数据集的IP地址所在位置的特征。特别是,人口密度是一个重要的参数,它表明了IP地址所在地区的农村和城市的性质。我们将在下面演示,这个参数会影响我们的方法的性能,因为城市地区通常有大量的基于网络的地标。
图7显示了三个数据集的IP地址所在的邮政编码的人口密度分布。我们通过查询城市数据[1]网站来获得每个邮政编码的人口密度。图7显示,我们的三个数据集分别覆盖了人口密度较小的农村地区和人口密度较大的城市地区。特别是,所有三个数据集都有超过20%的邮政编码信息信息,其人口密度小于1000。图中还显示,PlanetLab的数据集是最“城市”的数据集,而online maps数据集在农村地区存在的时间最长。特别是,online maps数据集中约有18%的IPs居住在人口密度小于100的邮政编码中。
[1] City data. http://www.city-data.com/.
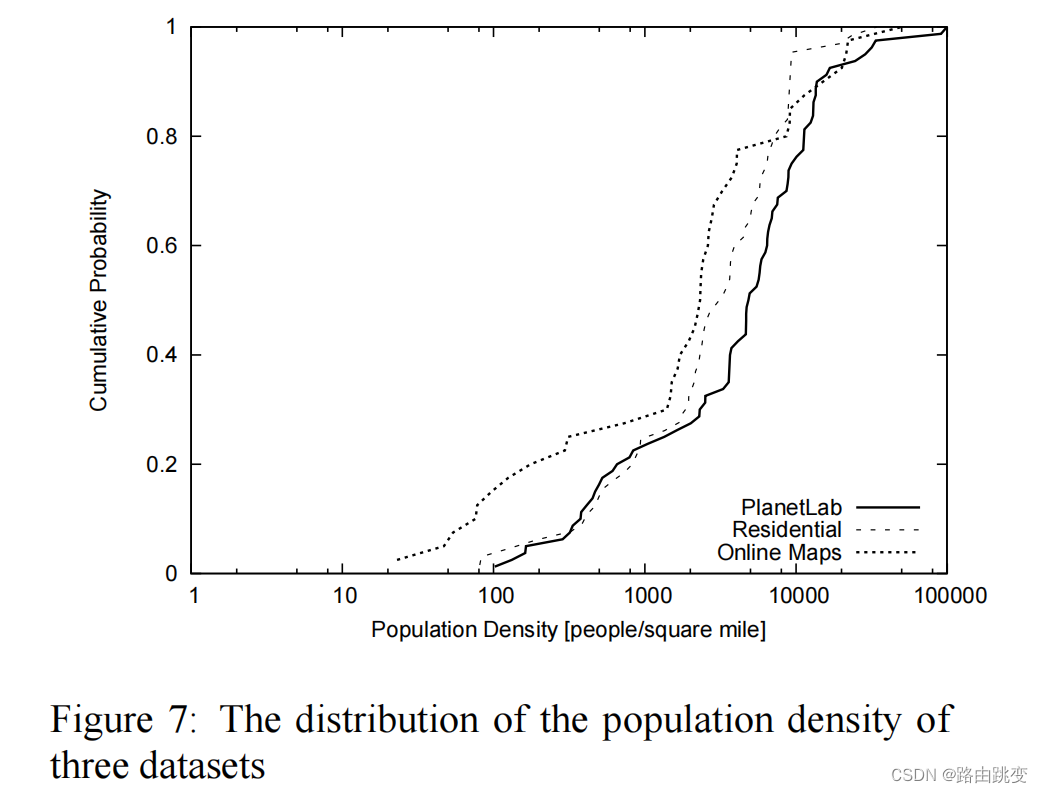
图7:三个数据集的人口密度分布
4.2 Experimental results
4.2.1 Baseline results
图8显示了这三个数据集的结果。特别地,它描述了误差距离的累积概率(CDF),即目标的真实位置和我们的系统所定位的地理位置之间的距离。
这篇关于Towards Street-Level Client-Independent IP Geolocation(2011年)(第二部分)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






