本文主要是介绍真全!GitHub上出现了一个353种语言资源的汇总,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:AI科技评论本文约1200字,建议阅读5分钟随着AI技术的迅猛发展,机器翻译技术的出现让拯救濒危语言成为可能。

据联合国科教文组织统计
世上现存的7000+种语言,超过四百种濒临灭绝
全世界平均每两个星期就有一门语言彻底消失……
于是,有人看不下去了
他们在GitHub上开发了一个项目
专门对353种语言信息做了汇总及科普
并整理了20个可免费下载的平行语料资源库
他们说,要为保护全球濒危语言贡献一份力量
1 为什么要做这个项目?
研究显示,全球有近2500种语言处于濒危状态,在联合国绘制的《全球濒危语言分布图》中,代表着危机的红色标记几乎布满世界各地,濒危语言资源的保护工作迫在眉睫。
如图,排名前三位的国家分别是印度、美国和印度尼西亚,这些国家各有一百多种语言面临消亡的危险。

令人欣喜的是,随着AI技术的迅猛发展,机器翻译技术的出现让拯救濒危语言成为可能。
目前,有很多研究机构和非盈利组织都在做濒危语言的挽救工作,他们通过收集整理和汇总濒危语言的信息,让濒危语言以数字化的形式保存下来。很多机器翻译研究团队也展开了面向低资源语言的机器翻译技术研究,比如,有很多机构通过单语、双语等各种形式的平行数据,构建低资源语言机器翻译引擎,这也是对语言保护的一种特殊方式。
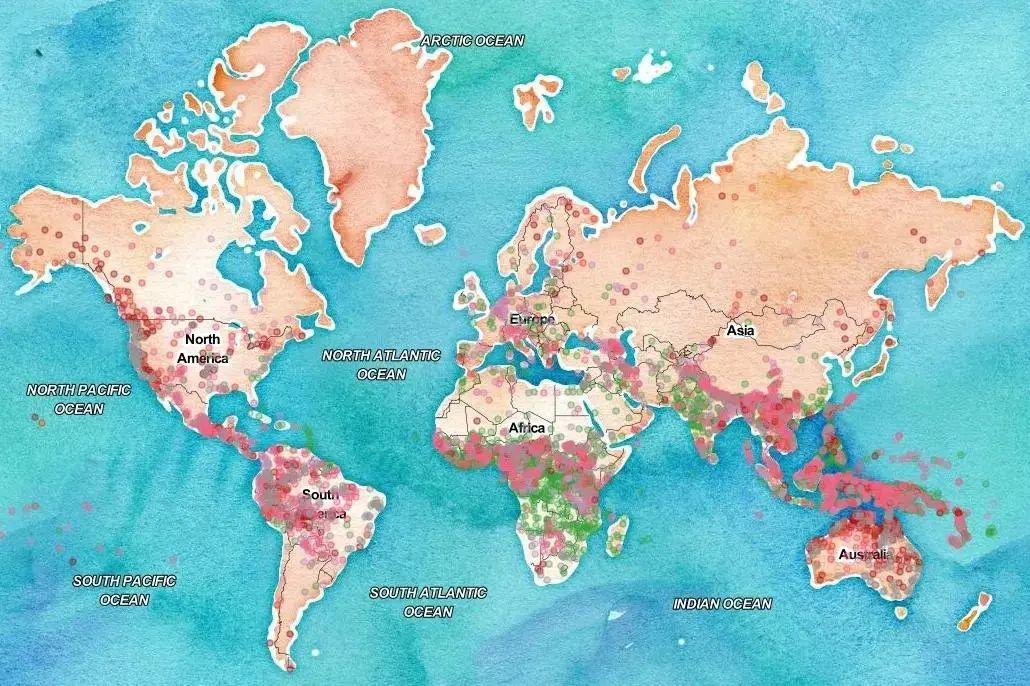
如上图所示,以我国为例,我国的濒危语言众多,但在国家大力保护下,许多仍处于留存状态(绿色部分),但也有大量语言濒临灭绝(红色部分),亟待拯救。
但是,即使是用上AI的力量,也只有200-300种语言能够呈现出来,还有很大一部分语言没有被数字化。因此,对濒危语言的留存与保护,是我们必须理性面对而不可回避的现实问题。
2 是什么样的资源?
目前,这个项目由小牛翻译团队发起,其中包含353种语言的ISO 639代码、语系、语族、书写字母、中文名称等信息,类似于一部“语言词典”,涵盖了世界上大部分的多数民族语言以及大量的少数民族语言。为方便使用者便捷地找到想要了解的语言信息,项目贴心地列出了语言的中英文名称。
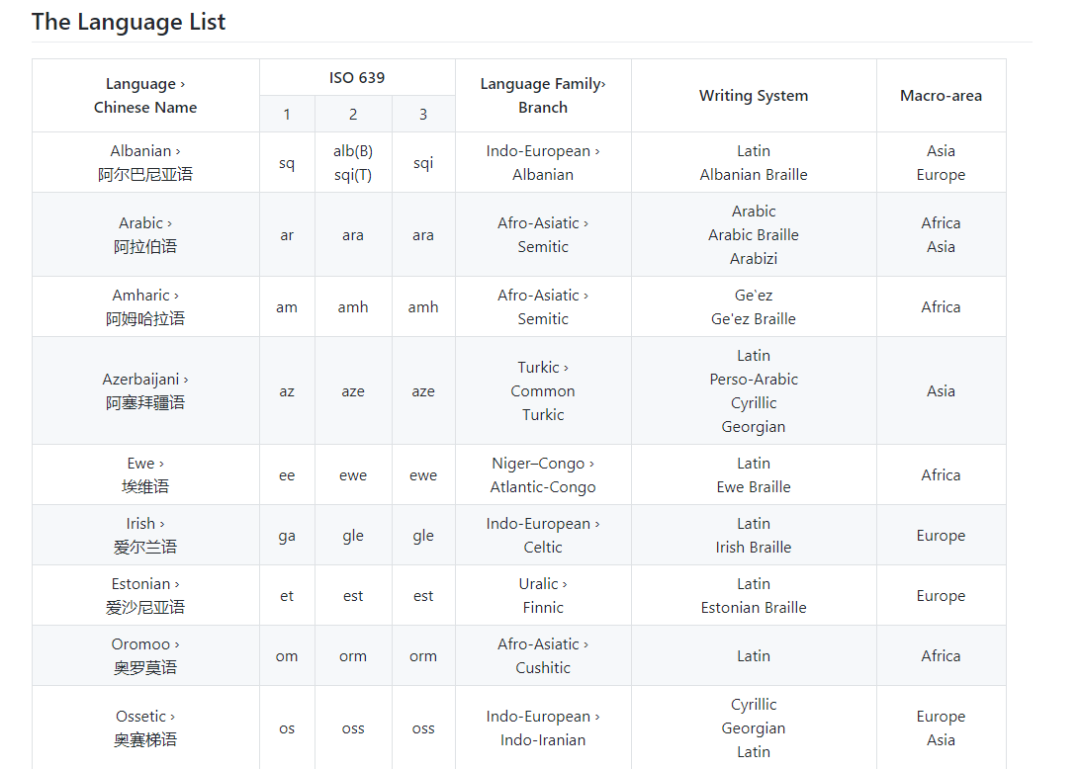
值得一提的是,“语言词典”中包括还斯瓦西里语、乌尔都语等低资源语言,这不仅是对语言的科普,也是对保护濒危语言做出的一份贡献。
3 彩蛋
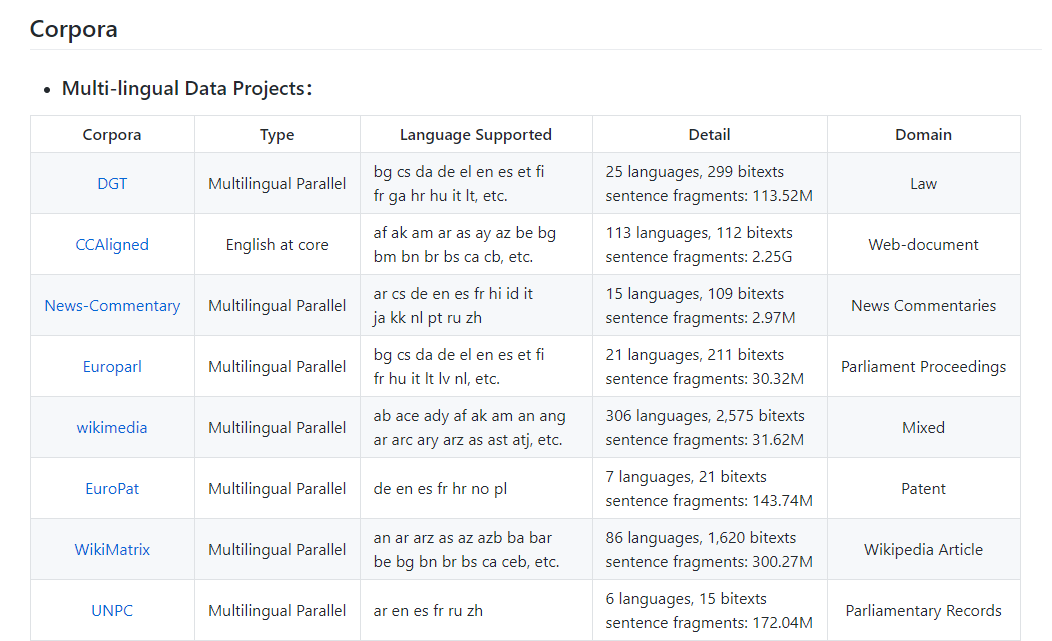
此外,他们还将来自CCMT、 WMT、 NIST、 IWSLT、WAT等机器翻译会议或机构的语言资源以及自行整理的20个多语/双语平行语料库(包括语料库所支持的语言、领域、数据量)的语言资源进行汇总,并从语种、语料库规模以及数据所属领域进行总结,并提供了资源的获取网址,便于研究者获取所需语种数据。
在这些语言中,包括一些尚未充分研究的语言,如达罗毗荼语系(Dravidian languages)泰米尔语(Tamil)(印度南部、斯里兰卡和新加坡语言)、泰卢固语(Telugu)和马拉雅拉姆语(Malayalam)(印度南部语言),以及尼日尔-刚果语系(Niger–Congo languages)斯瓦希里语(Swahili)和约鲁巴语(Yoruba)(非洲语言),可供人们开展语言研究、训练翻译模型、开发多语机器翻译系统之用。
如果你有兴趣,欢迎来访:
https://github.com/NiuTrans/LanguageCodes
编辑:文婧

这篇关于真全!GitHub上出现了一个353种语言资源的汇总的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






