本文主要是介绍模板进阶 | 非类型模板参数 | 类模板的特化 | 模板的分离编译 | 模板的优缺点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

非类型模板参数
我们可以认为非类型模板参数就是一个常量,在我们的类里面我们是不能对它进行改造
为什么会有这样的场景,其次就是C语言那里我们一般使用什么。
场景1
#include<iostream>
using namespace std;#define N 10
template<class T>
class Array
{
public:T& operator()(size_t index){return _arr[index];}const T& operator[](size_t index){return _arr[index];}size_t size(){return _size;}bool empty(){return _size == 0;}private:T _arr[N];size_t _size;};int main()
{Array<int> a;return 0;
}在我们上面这个场景中,我们要开辟这样一个数组,通过宏来控制我们静态数组的大小,这个也是C语言经常使用的场景,但是假如我们需要开辟另一个空间很大的数组,现在面对这种情况有两种方法,一种是改变宏的大小,这样就可以改变了,但是这个方法还是有一定的缺陷,比如我们一个数组的空间需要很大的时候,但是这个时候还有一个数组的空间是很小的时候,那这个时候两边都是需要进行满足的,所以就会在存在有一个数组的空间是会存在浪费的,第二个方法就是我们在写一个模板,需要一个数组就去再写一个模板,ctrl c + ctrl v
就能解决
所以面对上面的问题,我们也是有两种选法,但是都不能从根本上解决问题,所以就有了我们现在C++用到的非类型模板参数可以解决
改变代码
template<class T,size_t N = 10>
class Array
{
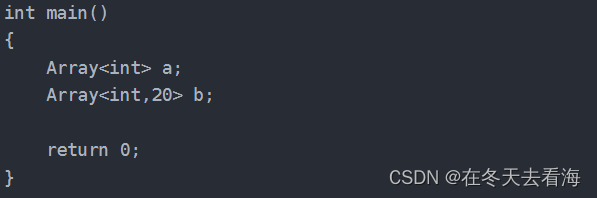
public:T& operator()(size_t index){return _arr[index];}const T& operator[](size_t index){return _arr[index];}size_t size(){return _size;}bool empty(){return _size == 0;}private:T _arr[N];size_t _size;};int main()
{Array<int> a;Array<int,20> b;return 0;
}这样就可以解决我们的问题,这里需要记住的是非类型模板参数其实是个常量,而且必须是整型
总结使用场景
我们需要定义一个静态数组的时候就可以是用的到,我们的库里面其实就是有一个array,但是实际上非类型模板参数其实是苦了我们的编译器,我们的模板这样写之后,编译器就能根据你的需求去进行实例化
--------很像到家思想的 死道友不死贫道
注意: 当前编译器只支持整型,非类型模板也是支持缺省参数(类型也是支持的,比如优先级队列就是这样的)
区别函数传参数和模板传参数
函数传参数
是我们在运行的时候来确定参数的,就比如我们之前写的一些函数,这里用 add函数来说
int Add(int x, int y)
{return x + y;
}比如在这个场景下我们要进行函数传参的时候,如果我们不去调用其实就没有传参数的过程,所以也就是只有在我们调用的时候才是会出现传参数
模板传参数
模板传参数就是在我们实例化的时候会进行,虽然有我们的按需实例化(后面讲),但是模板传参数的时候一定是在我们编译的时候编译器就是得知道的事

array真的很好吗
上面讲的array我们库里面其实是有的,但是array这个东西真的有这么好用吗,其实不是的,我们的vector可以完全替代array,array这个类是有点鸡肋的功能,而且他是静态的数组,在我们进行扩容的时候或者空间满的时候就不能进行调整了,所以array煤油vector好
但是这个发明肯定不是区别于我们的vector,是区别于我们的普通数组,因为它的检查更加严格,在我们的数组的时候对越界的检查其实是抽查,就和酒驾是一样的,而且越界读一般是不能检查出来的,越界写是抽查,但是array这些越界访问的操作都是能检查出来, 这就是array的唯一的优点了。但是还是想吐槽它的优点太有限了,我们vector也能进行检查访问,因为检查其实就是一个断言而已,这样就是一个小小的函数调用而已。
它还有缺陷 : 会导致栈溢出,因为我们栈的空间不是很大,堆的空间才很大。所以我们能用vector绝对不用array
按需实例化
演示按需实例化
template<class T,size_t N = 10>
class Array
{
public:T& operator()(size_t index){return _arr[index];}const T& operator[](size_t index){size(1);//有问题return _arr[index];}size_t size(){return _size;}bool empty(){return _size == 0;}private:T _arr[N];size_t _size;};int Add(int x, int y)
{return x + y;
}
int main()
{Array<int> a;Array<int,20> b;return 0;
}这个地方我注释的地方语法是不是有问题的,但是我们如果编译的时候是没有报错误的。
我们模板在预处理的时候和编译过程中增加了一个环节
根据模板实例化 - > 半成品模板 - > 实例化具体的类或者函数 - > 语法进行编译
所以我们可以猜测一下这里我们应该是 没有进行实例化!!!
哪怕我们这里写了实例化,也是没有检查出这个语法,所以结论就是我们的编译器是按需实例化的
也就是我们的成员函数调用哪个就进行哪个的实例化,我们这里没有调用这个operator[]函数,所以就不会进行报错,因为我们的编译就没有对他进行调用,那只有我们去调用的时候就会去实例化,这样就能检查出来这个问题了。
模板的特化
函数模板的特化
场景1: 如果我们要对我们的日期进行比较大小 所以需要先有一个日期类的实现的代码
class Date
{
public:friend ostream& operator<<(ostream& _cout, const Date& d);Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}
private:int _year;int _month;int _day;
};ostream& operator<<(ostream& _cout, const Date& d)
{_cout << d._year << "-" << d._month << "-" << d._day;return _cout;
}如果正常比较日期的话我们的代码是没有问题的,比如比较两个日期的大侠
class Date
{
public:friend ostream& operator<<(ostream& _cout, const Date& d);Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}
private:int _year;int _month;int _day;
};ostream& operator<<(ostream& _cout, const Date& d)
{_cout << d._year << "-" << d._month << "-" << d._day;return _cout;
}// 函数模板
template<class T>
bool Less(T left, T right)
{cout << "bool Less(T left, T right)" << endl;return left < right;
}
int main()
{Date d1(2024, 1, 1);Date d2(2023, 2, 2);cout << Less(d1, d2) << endl;return 0;
}这样我们就是可以正常的进行比较的,但是现在我们给出场景2,如果遇到的是Date* 的指针呢,我们这个时候就是需要模板的特化
场景2 ------ 引出特化
我们现在要进行比较的是我们的Date* 指针的大小,我们可以写一个这样的模板解决。
class Date
{
public:friend ostream& operator<<(ostream& _cout, const Date& d);Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}
private:int _year;int _month;int _day;
};ostream& operator<<(ostream& _cout, const Date& d)
{_cout << d._year << "-" << d._month << "-" << d._day;return _cout;
}// 函数模板
template<class T>
bool Less(T left, T right)
{cout << "bool Less(T left, T right)" << endl;return left < right;
}
template<>
bool Less<Date*>(Date* left, Date* right)
{return *left < *right;
}
int main()
{Date d1(2024, 1, 1);Date d2(2023, 2, 2);cout << Less(d1, d2) << endl;Date* pd1 = new Date(2023, 12, 1);Date* pd2 = new Date(2023, 12, 3);cout << Less(pd1, pd2) << endl;return 0;
}这样就对我们的Date* 进行比较了。
但是这个只是特化的最基础的使用。这是对于某种特殊类型的特殊处理
场景3
我们上面只是解决了我们Date* 的比较,如果我们还是需要对我们所有的指针进行比较的时候,我们的代码需要怎么写呢????
template<class T>
bool Less(T* left, T* right)
{return *left < *right;
}只需要这样写就能解决,这样可以测试不同的指针了。
注意 : 上面写的都是全特化 ,建议 : 函数模板不建议使用特化,使用重载能解决大部分的问题。
类模板的特化
全特化
template<class T1, class T2>
class Date
{public:Date(){cout << "Date<T1,T2>" << endl;}
private:T1 _d1;T2 _d2;
};//全透化template<>
class Date<int, char>
{
public:Date(){cout << "Date<int,char>" << endl;}
};
int main()
{Date<int, char> d1;Date<int, int> d2;return 0;
}其实看代码就是能看出来,我们给出了他们的具体类型,这个就是全透化。
半特化/偏特化
template<class T1>
class Date<T1, char>
{
public:Date(){cout << "Date<T1,char>" << endl;}
};上面的这个就是我们的特化的全部语法,但是要知道半特化不一定是特化部分的参数,只是对一些参数的限制,我们这里也能使用指针和引用(list的迭代和反向迭代器就是这样的)。就不演示了
template<class T>
class Date<T*,T*>
{
public:bool operator()(T* x, T* y){return *x < *y;}
};总结 : 想针对某种类型进行特殊处理的时候就可以考虑使用特化。
模板的分离编译
模板是不支持声明和定义分离进行编译的,因为我们的编译器是不知道我们需要实例化成什么类,这里不支持分离编译是指在两个不同的文件下,而不是在同一个文件,我们来举出一个例子,然后进行分析,首先就是我们需要创建一个头文件,一个就是Fun.h,然后就是fun.cpp,还有就是test.cpp
Fun.h
#pragma once#include<iostream>
using namespace std;template<class T>
T Add(const T& x, const T& y);void Fun();
fun.cpp
#include"Fun.h"template<class T>
T Add(const T& x, const T& y)
{return x + y;
}void Fun()
{cout << "void Fun()" << endl;}test.cpp
#include"Fun.h"int main()
{int ret = Add(1, 3);return 0;
}然后进行编译就会出现这样的报错信息

但是我们的普通函数就是可以通过,而且要注意这里的报错不是编译问题,而是链接问题
分析程序在预处理,编译,汇编以及链接做的事情
预处理
预处理这一部分需要做的是条件编译,宏替换,去注释,头文件展开,所以我们的每个.cpp文件里的头文件都会进行展开,因为编译器是不会对我们写的.h文件进行编译的。
编译
编译这一步很重要,会进行的事情很多,比如要语法分析,语意分析,还会生成语法树,就是在检出我们写的代码语法是不是正确,最后就是生成汇编代码。
汇编
生成二进制代码,形成目标文件
链接
合并生成可执行文件
注意: 这里只是讲个大概,具体的之前的文章也是讲过的。

两个文件都进行编译之后生成的目标文件,然后进行链接之后,我们的fun函数是有它的地址的,这个地址相当于一个跳转的指令,和我们之前所得call地址可以认为是一样的,fun函数是能成功生生call地址的,但是我们的函数模板,它会按需实例化,我们也不知道T要变成什么类型,这也就导致了最后链接时候找不到地址,所以才会链接错误
解决办法
1.模板的声明和定义放在同一个头文件,不要进行分离编译
2.声明类型,让编译器能实例化。也就是显示实例化

结论就是我们还是最好模板的声明和定义放在一起,这才是最好的解决方法。
模板的优缺点

这篇关于模板进阶 | 非类型模板参数 | 类模板的特化 | 模板的分离编译 | 模板的优缺点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







