本文主要是介绍改变LoRA的初始化方式,北大新方法PiSSA显著提升微调效果,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注

随着大模型的参数量日益增长,微调整个模型的开销逐渐变得难以接受。
为此,北京大学的研究团队提出了一种名为 PiSSA 的参数高效微调方法,在主流数据集上都超过了目前广泛使用的 LoRA 的微调效果。

-
论文: PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
-
论文链接: https://arxiv.org/pdf/2404.02948.pdf
-
代码链接: https://github.com/GraphPKU/PiSSA
如图 1 所示,PiSSA (图 1c) 在模型架构上和 LoRA [1] 完全一致 (图 1b),只是初始化 Adapter 的方式不同。LoRA 使用高斯噪声初始化 A,使用 0 初始化 B。而 PiSSA 使用主奇异值和奇异向量 (Principal Singular values and Singular vectors) 来初始化 Adapter 来初始化 A 和 B。
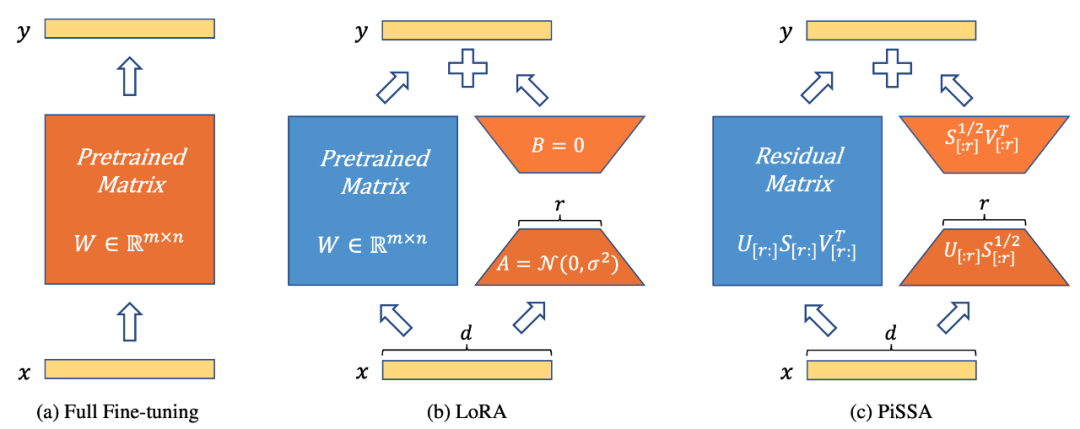
图 1)从左到右依次为全参数微调、LoRA、以及 PiSSA。蓝色代表冻结的参数,橘黄色代表可训练参数及它们的初始化方式。相比全参数微调,LoRA 和 PiSSA 都大幅节省了可训练参数量。对于相同输入,这三种方法的初始输出完全相等。然而,PiSSA 冻结模型的次要成分,直接微调主成分(前 r 个奇异值和奇异向量);而 LoRA 可看作冻结模型的主要部分,而去微调 noise 部分。
在不同的任务上对比 PiSSA、LoRA 的微调效果
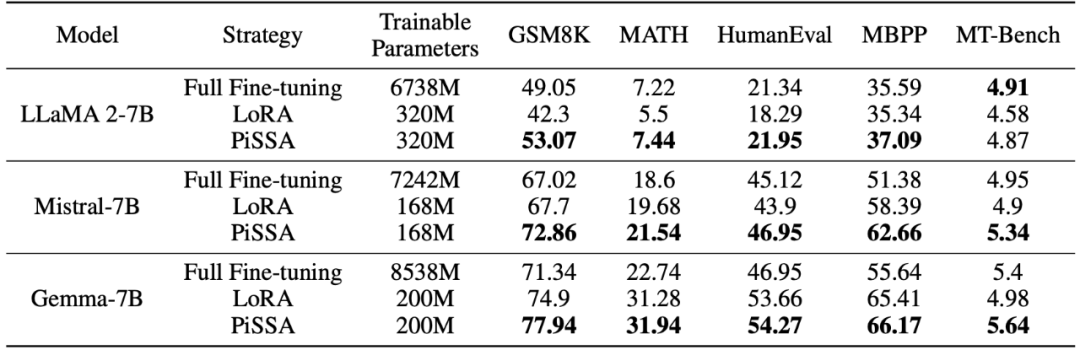
研究团队使用 llama 2-7B、Mistral-7B 以及 Gemma-7B 作为基础模型,通过微调提升它们的数学、代码和对话能力。其中包括:在 MetaMathQA 上训练,在 GSM8K 和 MATH 数据集上验证模型的数学能力;在 CodeFeedBack 上训练,在 HumanEval 和 MBPP 数据集上验证模型的代码能力;在 WizardLM-Evol-Instruct 上训练,在 MT-Bench 上验证模型的对话能力。从下表的实验结果可以看出,使用相同规模的可训练参数,PiSSA 的微调效果显著超越了 LoRA,甚至超越了全参数微调。
对比 PiSSA、LoRA 在不同的可训练参数量下微调的效果
研究团队在数学任务上对模型的可训练参数量和效果之间的关系进行消融实验。从图 2.1 发现在训练初期,PiSSA 的训练 loss 下降特别快,而 LoRA 存在不下降,甚至略有上升的阶段。此外,PiSSA 的训练 loss 全程低于 LoRA,说明对训练集拟合得更好;从图 2.2、2.3、2.4 可以看出在每种 setting 下,PiSSA 的 loss 始终比 LoRA 低,准确率始终比 LoRA 高,PiSSA 能够使用更少的可训练参数追赶上全参数微调的效果。
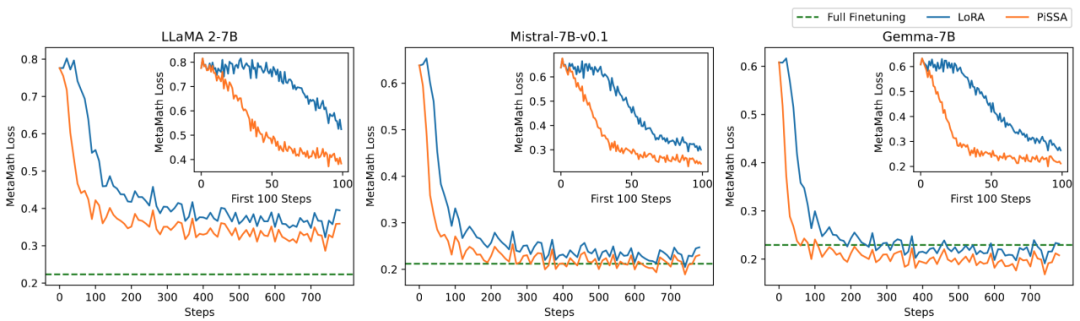
图 2.1) 当秩为 1 时 PiSSA、LoRA 在训练过程中的 loss。每幅图的右上角是前 100 步迭代放大的曲线。其中 PiSSA 用橙色线表示,LoRA 用蓝色线表示,全参数微调用绿线展示了最终的 loss 作为参考。秩为 [2,4,8,16,32,64,128] 时的现象与此一致,详见文章附录。
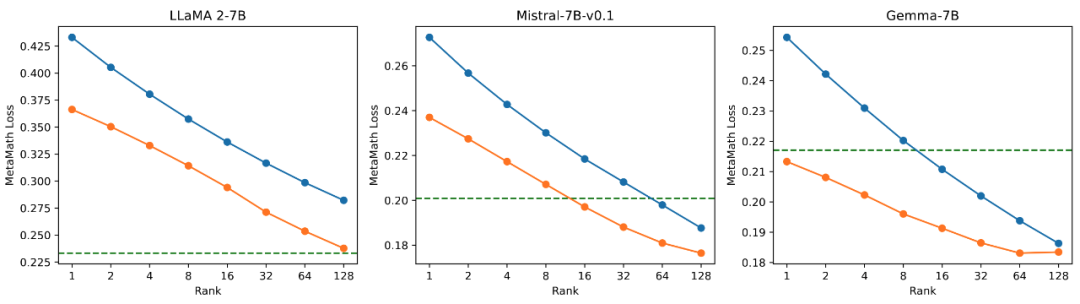
图 2.2)使用秩为 [1,2,4,8,16,32,64,128] 的 PiSSA 和 LoRA 的最终 training loss。
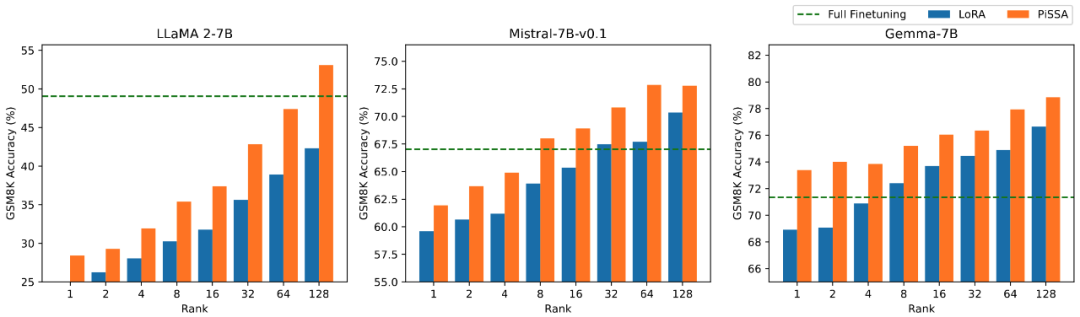
图 2.3)使用秩为 [1,2,4,8,16,32,64,128] 的 PiSSA 和 LoRA 微调的模型在 GSM8K 上的准确率。
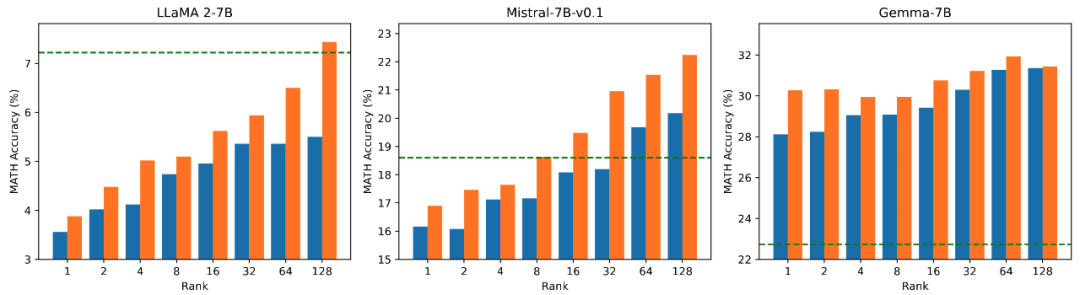
图 2.4)使用秩为 [1,2,4,8,16,32,64,128] 的 PiSSA 和 LoRA 微调的模型在 MATH 上的准确率。
PiSSA 方法详解
受到 Intrinsic SAID [2]“预训练大模型参数具有低秩性” 的启发,PiSSA 对预训练模型的参数矩阵
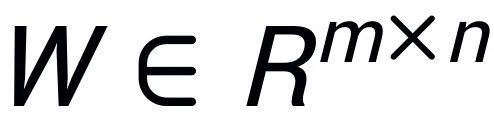
进行奇异值分解,其中前 r 个奇异值和奇异向量用来初始化适配器 (adapter) 的两个矩阵

和

,

;剩余的奇异值和奇异向量用来构造残差矩阵

,使得
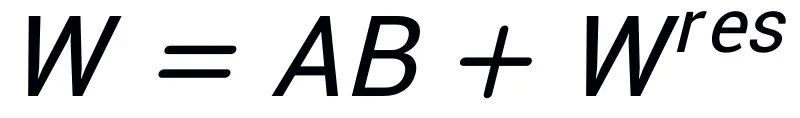
。因此,适配器中的参数包含了模型的核心参数,而残差矩阵中的参数是修正参数。通过微调参数量较小的核心适配器 A、B,冻结参数量较大的残差矩阵

,就达成了用很少的参数近似全参数微调的效果。
尽管同样受到 Intrinsic SAID [1] 启发,PiSSA 和 LoRA 背后的原理却截然不同。
LoRA 认为大模型微调前后矩阵的变化 △W 具有很低的本征秩 r,因此通过

和

相乘得到的低秩矩阵来模拟模型的变化 △W。初始阶段,LoRA 使用高斯噪声初始化 A,使用 0 初始化 B,因此

,以此保证模型初始能力没有变化,并微调 A 和 B 实现对 W 进行更新。与此相比,PiSSA 不关心 △W,而是认为 W 具有很低的本征秩 r。因此直接对 W 进行奇异值分解,分解成主成分 A、B,以及残差项

,使得
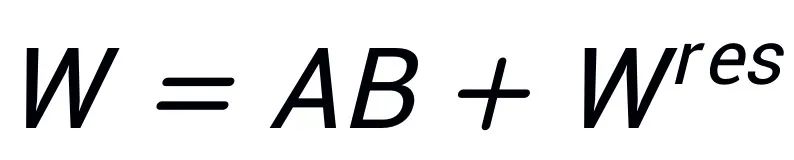
。假设 W 的奇异值分解为

,A、B 使用 SVD 分解后奇异值最大的 r 个奇异值、奇异向量进行初始化:
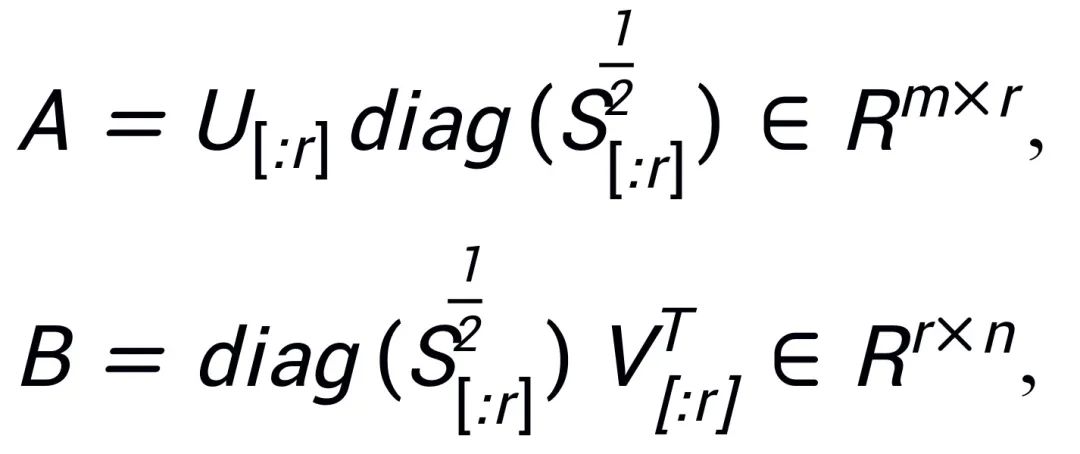
残差矩阵使用其余的奇异值、奇异向量进行初始化:
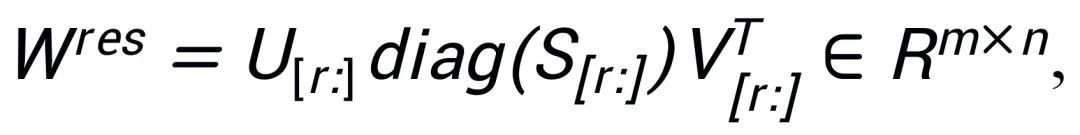
PiSSA 直接对 W 的低秩主成分 A、B 进行微调,冻结次要的修正项。相比 LoRA 用高斯噪声以及 0 初始化适配器参数、冻结核心模型参数,PiSSA 收敛更快、效果更好。
PiSSA 的发音类似 “披萨”(pizza)--- 如果把整个大模型类比为一个完整的披萨,PiSSA 切掉其中一角,而且是馅料最丰富的一角(主奇异值、奇异向量),重新烘焙(在下游任务上微调)成喜欢的口味。
由于 PiSSA 采用了和 LoRA 完全相同的架构,其可以作为 LoRA 的一种可选初始化方式,在 peft 包中很方便的进行修改和调用 (如以下代码所示)。相同的架构也使得 PiSSA 继承了大多数 LoRA 的优点,如:对残差模型使用 4bit 量化 [3],减小训练开销;微调完成后适配器能合并进残差模型,不改变推理过程的模型架构;无需分享完整模型参数,只需要分享参数量很少的 PiSSA 模块,使用者直接加载 PiSSA 模块就能自动进行奇异值分解以及赋值;一个模型可以同时使用多个 PiSSA 模块等等。一些对 LoRA 方法的改进,也能与 PiSSA 进行结合:比如不固定每层的秩,通过学习找到最佳的秩 [4];用 PiSSA 指导的更新 [5],从而突破秩的限制等等。
# 在 peft 包中 LoRA 的初始化方式后面增加了一种 PiSSA 初始化选项:if use_lora:nn.init.normal_(self.lora_A.weight, std=1 /self.r)nn.init.zeros_(self.lora_B.weight)elif use_pissa:Ur, Sr, Vr = svd_lowrank (self.base_layer.weight, self.r, niter=4)# 注意:由于 self.base_layer.weight 的维度是 (out_channel,in_channel, 所以 AB 的顺序相比图示颠倒了一下)self.lora_A.weight = torch.diag (torch.sqrt (Sr)) @ Vh.t ()self.lora_B.weight = Ur @ torch.diag (torch.sqrt (Sr))self.base_layer.weight = self.base_layer.weight - self.lora_B.weight @ self.lora_A.weight
对比高中低奇异值微调效果实验
为了验证使用不同大小奇异值、奇异向量初始化适配器对模型的影响,研究人员分别使用高、中、低奇异值初始化 LLaMA 2-7B、Mistral-7B-v0.1、Gemma-7B 的适配器,然后在 MetaMathQA 数据集上进行微调,实验结果展示在图 3 中。从图中可以看出,使用主要奇异值初始化的方法训练损失最小,在 GSM8K 和 MATH 验证集上的准确率更高。这一现象验证了微调主要奇异值、奇异向量的有效性。
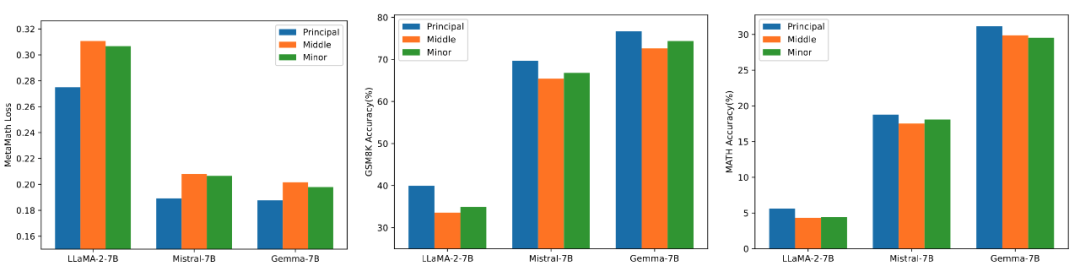
图 3)从左到右依次为训练 loss、在 GSM8K 上的准确率、在 MATH 上的准确率。其中蓝色表示最大奇异值、橙色表示中等奇异值、绿色表示最小奇异值。
快速奇异值分解
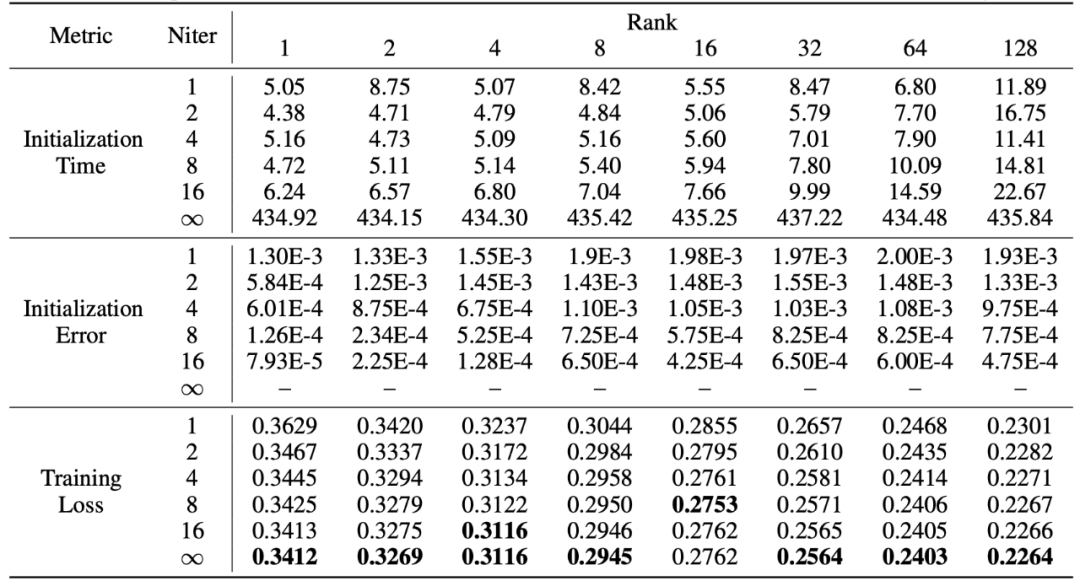
PiSSA 继承了 LoRA 的优点,使用起来方便,效果超越 LoRA。代价是在初始化阶段,需要对模型进行奇异值分解。虽然仅需要在初始化时分解一次,但是仍然可能需要几分钟甚至几十分钟的开销。因此,研究人员使用一种快速奇异值分解 [6] 方法替代标准的 SVD 分解,通过下表的实验可以看出,仅需几秒钟的时间,就能逼近标准 SVD 分解的训练集拟合效果。其中 Niter 表示迭代次数,Niter 越大,时间越久但是误差越小。Niter = ∞表示标准 SVD。表格中的平均误差表示快速奇异值分解与标准 SVD 得到的 A、B 之间的平均 L_1 距离。
总结与展望
本工作对预训练模型的权重进行奇异值分解,通过将其中最重要的参数用于初始化一个名为 PiSSA 的适配器,微调这个适配器来近似微调完整模型的效果。实验表明,PiSSA 比 LoRA 收敛更快,最终效果更好,唯一的代价仅是需要几秒的 SVD 初始化过程。
那么,您愿意为了更好的训练效果,多花几秒钟时间,一键更改 LoRA 的初始化为 PiSSA 吗?
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注
这篇关于改变LoRA的初始化方式,北大新方法PiSSA显著提升微调效果的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




