本文主要是介绍巨型页原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当运行内存需求量较大的应用程序时,如果使用长度位4KB的页,将会产生较多的TLB未命中和缺页异常,严重影响应用程序的性能;如果使用长度为2MB甚至更大的巨型页,可以大幅减少TLB未命中和缺页异常的数量,大幅提高应用程序的性能;这正是引入巨型页(Huge Page)的直接原因;
巨型页首先需要处理器能够支持,然后需要内核支持;
内核对巨型页的支持
内核有两种实现方式:
1)使用hugetlbfs伪文件系统实现巨型页;hugetlbfs文件系统是一个假的文件系统,只是利用了文件系统的编程接口;使用hugetlbfs文件系统实现的巨型页成为hugetlbfs巨型页、传统巨型页或者标准巨型页;
2)透明巨型页;标准巨型页的优点是预先分配巨型页到巨型页池,进程申请巨型页的时候从巨型页池取,成功的概率很高,缺点是应用程序需要使用文件系统的编程接口;透明巨型页的优点是对应用程序透明,缺点是动态分配,在内存碎片化的时候分配成功的概率很低;
本文主要介绍标准巨型页;
处理器对巨型页的支持
ARM64处理器支持巨型页的方式有两种:
1)通过块描述符支持;
2)通过页/块描述符的连续位支持;
通过块描述符支持巨型页
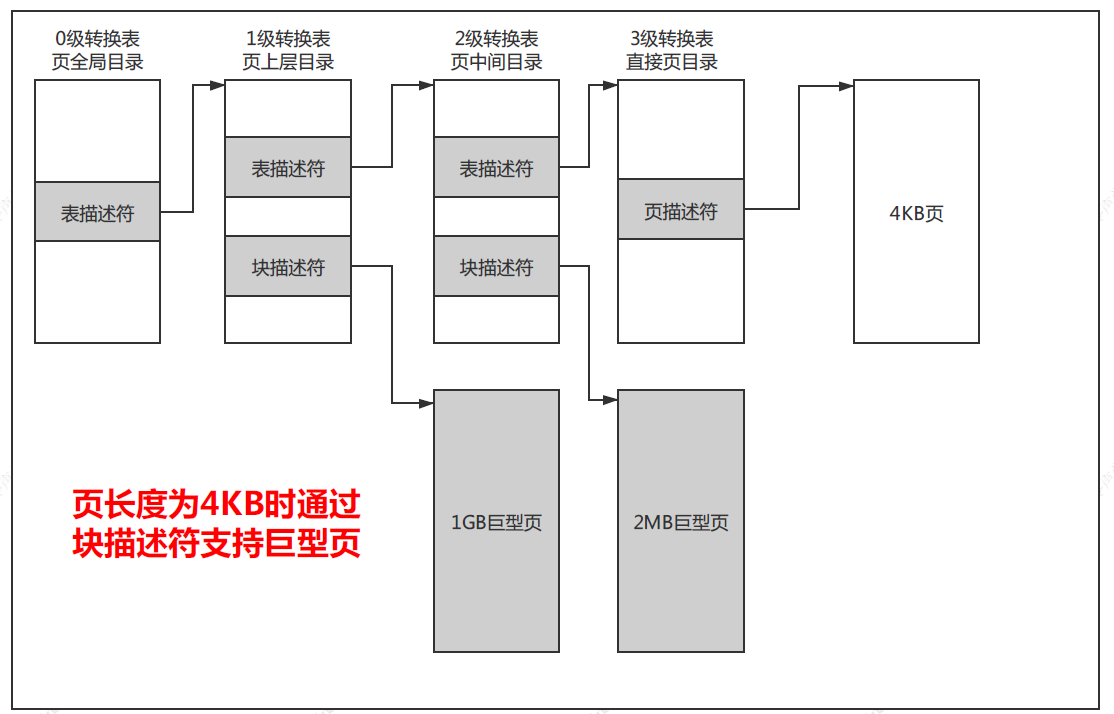
如下图所示,如果页长度是4KB,那么使用4级转换表,0级转换表不能使用块描述符,1级转换表的块描述符指向1GB巨型页,2级转换表的描述符指向2MB巨型页;
通过页/块描述符的连续位支持巨型页
页/块描述符中的连续位指示表项是一个连续表项集合中的一条表项,一个连续表项集合可以被缓存在一条TLB表项里面;
通俗地说,进程申请了n页地虚拟内存区域,然后申请了n页的物理内存区域,使用n个连续的页表项把每个虚拟页映射到物理页,每个页表项都设置连续标志位,当处理器的MMU遍历内存中的页表时,访问到该n个页表项中的任何一个页表项,发现页表项设置了连续标志位,就会把n个页表项合并后填充到一个TLB表项;
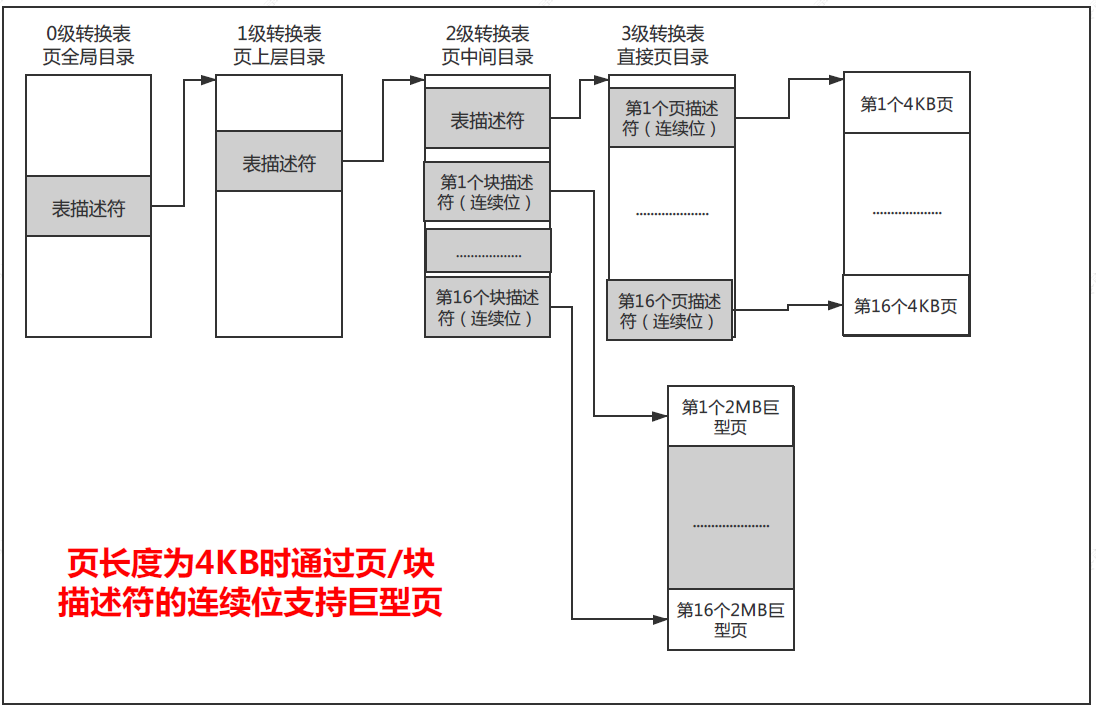
如果页长度时4KB,那么使用4级转换表,1级转换表的块描述符不能使用连续位;2级转换表的块描述符支持16个连续块,即支持16*2MB=32MB的巨型页;3级转换表的页描述符支持16个连续页,即支持16*4KB=64KB的巨型页;如下图所示:
标准巨型页
标准巨型页是预先分配巨型页到巨型页池,进程申请巨型页的时候从巨型页池取;通过文件“cat /proc/sys/vm/nr_hugepages”指定巨型页池中永久巨型页的数量;通过文件“cat /proc/sys/vm/nr_overcommit_hugepages”指定巨型页池中临时巨型页的数量;当永久巨型页使用完的时候,可以从页分配器申请临时巨型页;
nr_hugepages是巨型页池的最小长度;nr_hugepages+nr_overcommit_hugepages是巨型页池的最大长度,这两个参数默认值都是0,至少要设置一个,否则分配巨型页会失败;
cat /proc/meminfo可以查看巨型页信息;
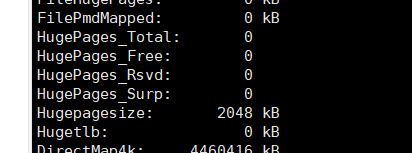
HugePages_Total,巨型页池的大小;
HugePages_Free,巨型页池中没有分配的巨型页的数量;
HugePages_Rsvd,预留的巨型页,是已经承诺从巨型页池中分配但是还没有分配的巨型页的数量;预留的巨型页保证应用程序在发生缺页异常的时候能够从巨型页池中分配一个巨型页;
HugePages_Surp,Surplus,多余的,是巨型页池中临时巨型页的数量;临时巨型页的最大数量是nr_overcommit_hugepages;
HugePagesize,巨型页的大小;
巨型页池
内核使用巨型页池管理巨型页;有的处理器架构支持多种巨型页长度,没种巨型页长度对应一个巨型页池,有一个默认的巨型页长度,默认只创建巨型页长度是默认长度的巨型页池;如ARM64架构在页长度为4KB的时候支持的巨型页长度是1GB、32MB、2MB和64KB,默认巨型页长度是2MB,默认只创建巨型页长度是2MB的巨型页池;
struct hstate {int next_nid_to_alloc;int next_nid_to_free;unsigned int order;unsigned long mask;unsigned long max_huge_pages;unsigned long nr_huge_pages;unsigned long free_huge_pages;unsigned long resv_huge_pages;unsigned long surplus_huge_pages;unsigned long nr_overcommit_huge_pages;struct list_head hugepage_activelist;struct list_head hugepage_freelists[MAX_NUMNODES];unsigned int nr_huge_pages_node[MAX_NUMNODES];unsigned int free_huge_pages_node[MAX_NUMNODES];unsigned int surplus_huge_pages_node[MAX_NUMNODES];
#ifdef CONFIG_CGROUP_HUGETLB/* cgroup control files */struct cftype cgroup_files[5];
#endifchar name[HSTATE_NAME_LEN];
};
int hugetlb_max_hstate __read_mostly;
unsigned int default_hstate_idx;
struct hstate hstates[HUGE_MAX_HSTATE];
struct hstate,巨型页池的数据结构;
hstates,巨型页池全局数组;
hugetlb_max_hstate,巨型页池的数量;
default_hstate_idx,默认巨型页池的索引;
巨型页池中的巨型页分为两种:
1)永久巨型页:永久巨型页是保留的,不能有其他用途,被预先分配到巨型页池,当进程释放永久巨型页的时候,永久巨型页被归还到巨型页池;
2)临时巨型页:也称为多余的(surplus)巨型页,当永久巨型页用完的时候,可以从页分配器分配临时的巨型页;进程释放临时巨型页的时候,直接释放到页分配器;当设备长时间运行后,内存可能碎片化,分配临时巨型页可能失败;
hugetlb相当于hugepages的页面管理者,页面的分配及释放,都由此模块负责;
hugetlbfs则用于向用户提供一套基于文件系统的巨型页使用界面,下层功能的实现,主要依赖于hugetlb;
这篇关于巨型页原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








