本文主要是介绍超标量处理器中的分支预测实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 超标量的分支预测与标量分支预测的不同点:
- 在取指令时给出一个地址,会从 I-Cache 中取出多条指令,这些取出的指令组成了一个指令组(fetch group);
- 处理器会自动根据指令组中的指令个数,调整取指令的地址,用来进行下个周期的取指令。
- 因此超标量处理器中的取指令地址并不是连续的,每次增加的值等于指令组的字长,送入到I-Cache中取指令的地址其实只是指令组中第一条指令的地址而已。
- 如果此时仍旧只是使用取指令时的地址(也就是PC值)进行分支预测,那么就相当于只是对指令组中的第一条指令进行了分支预测,而指令组中后面的指令根本就没有顾及到,使超标量处理器无法从分支预测中获得太大的好处。
- 解决方式之一:对取指令进行限制;以4-way超标量处理器为例;
- 约束每次取指令位于4B对齐的边界内,此时可以使用PC[31:4]来寻址分支预测器;
- 分支预测器中,记录这4条指令中,第一个分支指令的信息即可;因为大部分情况下,每个4B对齐的四条指令中,最多也就存在一条分支指令;
- 此时还需要在分支预测器中,记录分支指令的位置,防止错误使用;
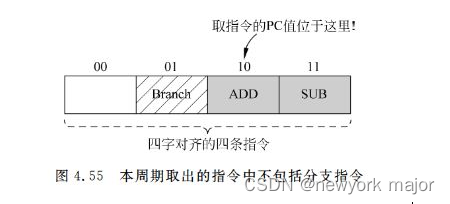
- 如下图所示,在如下的4B对齐的指令中,此时取指令的PC值位于branch之后,那么这个pc就不应该使用分支指令的预测信息
- 要想知道该信息,就需要在BTB中,记录分支指令的偏移值;
- 解决方式之二:不进行限制,全部进行分支预测;
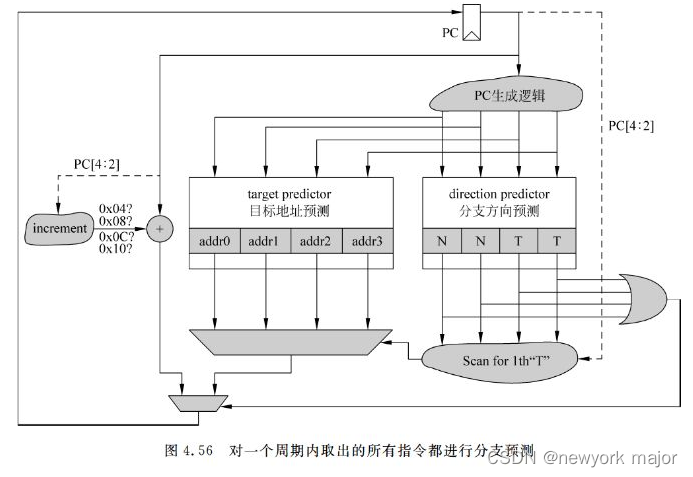
- 此时没有对齐限制,需要对所有的指令,进行分支预测;
- 第一个预测跳转的分支指令的目标地址,作为下一个周期取指令的地址;
- 取指令阶段使用的 PC 值只给出了指令组中第一条指令的 PC 值,需要使用三个加法器来实现 PC+4、PC+8 和 PC+12 的功能;
- 由于对目标地址的预测来说,需要在一个周期内提供四个PC值对应的目标地址,这就相当于需要BTB支持四个读端口,即使可以采用交叠(interleaving)的方式来避免真正的多端口,但是考虑到在使用过程中,最多只会使用其中的一个端口的值,所以这种方式对于硬件的利用效率是很低的。
- 其他方式:
- 进入icache之前,预解码,这样取出来之后,马上就可以识别出分支指令,快速计算出跳转目标地址;当然,如果是return类型的指令,这种方式不行;
- 不一定在一个周期得到分支预测结果,可以这样做, 降低设计复杂度:
- 方向预测和目标地址预测串行,在方向预测完成后,再利用其结果信息进行目标地址的预测,可以避免对BTB部件的多端口需求;
- 扩展:interleaving的处理,需要一个cycle内的pc值,译码到不同的bank, 从而不产生冲突,如果pc值做了hash, 但是又希望不同的pc hash后, 在同一个cycle内不会产生bank冲突,如何解决?
- 最简单的方式,将PC的[3:2]作为寻址低位即可;
这篇关于超标量处理器中的分支预测实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






