本文主要是介绍Understanding Flink,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- Flink 下载:
mkdir ~/flink && cd ~/flinkwget --no-check-certificate https://archive.apache.org/dist/flink/flink-1.15.3/flink-1.15.3-bin-scala_2.12.tgz
wget --no-check-certificate https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.1.1/flink-sql-connector-mysql-cdc-2.1.1.jar
wget --no-check-certificate https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-jdbc/1.15.3/flink-connector-jdbc-1.15.3.jar
wget --no-check-certificate https://repo.maven.apache.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jartar -xf flink-1.15.3-bin-scala_2.12.tgz
cp *.jar flink-1.15.3/lib/
cd flink-1.15.3
chmod -R 777 ./bin/*
./bin/start-cluster.sh
echo http://`hostname -i`:8081/
./bin/sql-client.sh- 对 Flink 的理解
Flink 有 cdc 的 connector,有 jdbc 的 connector。其中:
- 基于日志的CDC:cdc connector 用于做实时同步,jdbc 则用于数据写入。
假设源端使用的是 cdc,那么一个 Flink SQL Jobinsert into target select from cdc_table会一直在后台执行,监听数据的变化,并根据变化做计算。 - 基于查询的CDC:假设源端使用的是 jdbc connector,那么 Flink SQL 会立即执行,读取源端的全部数据并做计算,然后 Job 退出。源端有新的插入,也不会做任何同步操作,因为 Job 已经结束。
// https://cloud.tencent.com/developer/article/2193358
- Flink 的市场定位
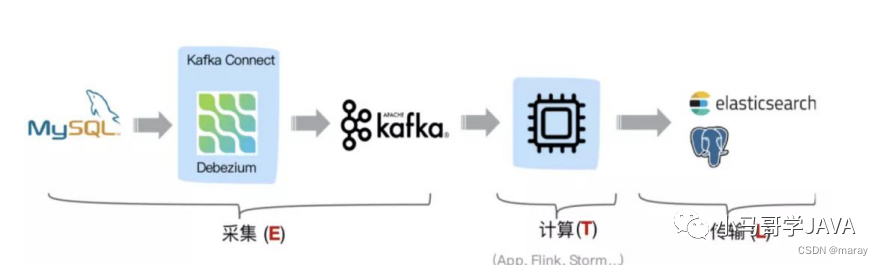
方案一、Debezium+Kafka+计算程序+存储系统
采用Debezium订阅MySql的Binlog传输到Kafka,后端是由计算程序从kafka里面进行消费,最后将数据写入到其他存储。
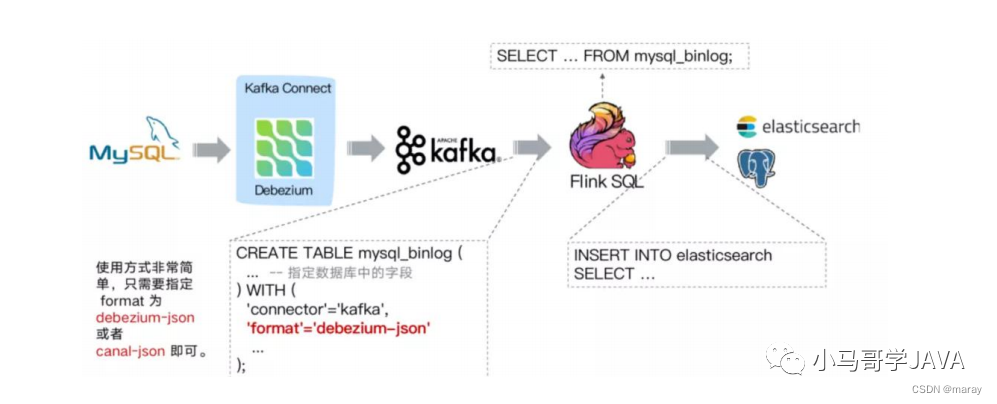
方案二、Debezium + Kafka + Flink Sql+存储系统
Flink Sql具备解析 Kafka 中 debezium-json 和 canal-json 格式的 binlog 能力,具体的框架如下
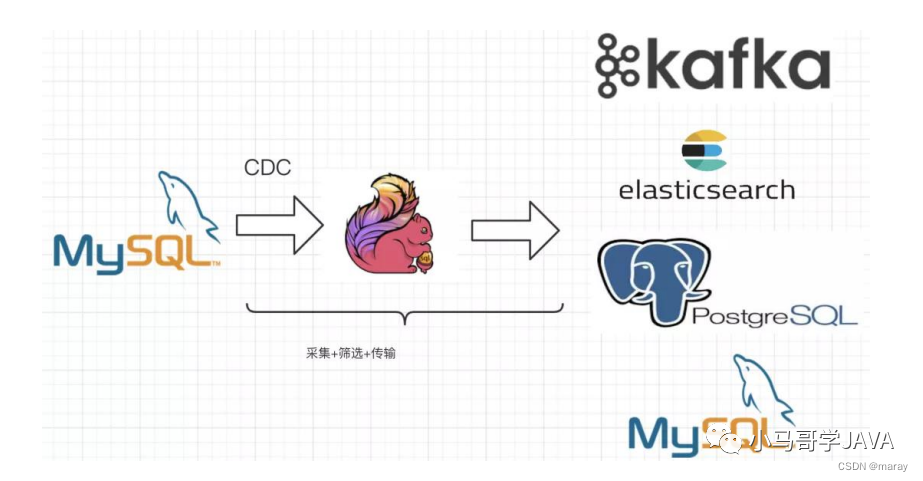
方案三、Flink CDC + JDBC Connector
方案一与方案二的相同点是组件维护复杂,Flink 1.11中CDC Connectors内置了 Debezium 引擎,可以替换 Debeziuum+Kafka.
总结:Flink 的市场定位就是干掉所有传输通道上的人。
通过Flink CDC Connector替换Debezium+Kafka的数据采集模块,实现 Flink Sql 采集+计算+传输(ETL)一体化。优点如下
- 开箱即用,容易上手
- 减少维护的组件,简化实时链路,减轻部署成本
- 减少端到端延迟
- Flink 自身支持Exactly Once的读取计算
- 数据不落地,减少存储成本
- 支持全量和增量流式读取
- binlog采集位点可回溯
最后,Flink 得到下面这样一个架构图:
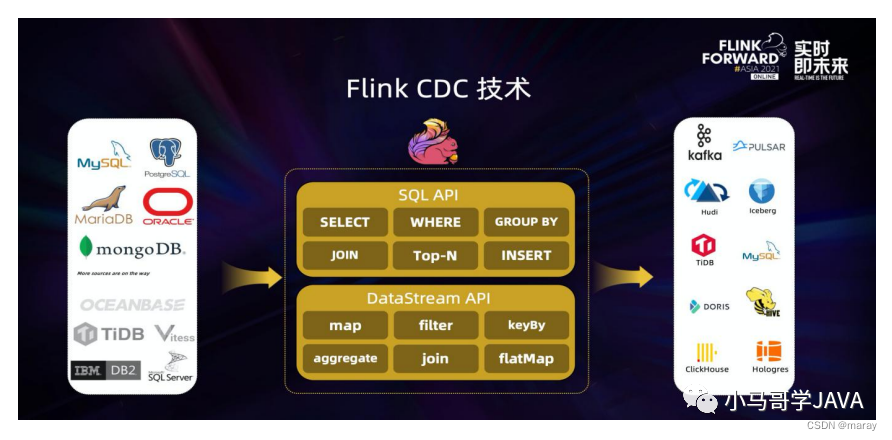
还有一点薄纱要翻开:Flink SQL 支持什么呢?
- CTE
WITH orders_with_total AS (SELECT order_id, price + tax AS totalFROM Orders
)
SELECT order_id, SUM(total)
FROM orders_with_total
GROUP BY order_id;
- SELECT & WHERE
SELECT price + tax FROM Orders WHERE id = 10
- SELECT DISTINCT
SELECT DISTINCT id FROM Orders
- Windowing table-valued functions (Windowing TVFs)
Apache Flink provides 3 built-in windowing TVFs: TUMBLE, HOP and CUMULATE. 利用这些 table function,可以把原始表的数据进行分组/扩行。例如下面的例子,用 TUMBLE 把 6 行数据按照 10 分钟的间隔分成了 2 组,然后基于这些组就能做进一步的聚合分析。
Flink 支持等间隔窗口(TUMBLE)、滑动窗口(HOP)、累积窗口(CUMULATE),可以根据实际业务场景选用。比如:
- 实时统计每个小时的销量,用 TUMBLE 就比较合适,按小时划分间隔。
- 实时统计最近 60 分钟的销量,则使用 HOP(60min)比较合适,每分钟更新一次。
Flink SQL> SELECT * FROM Bid;
+------------------+-------+------+
| bidtime | price | item |
+------------------+-------+------+
| 2020-04-15 08:05 | 4.00 | C |
| 2020-04-15 08:07 | 2.00 | A |
| 2020-04-15 08:09 | 5.00 | D |
| 2020-04-15 08:11 | 3.00 | B |
| 2020-04-15 08:13 | 1.00 | E |
| 2020-04-15 08:17 | 6.00 | F |
+------------------+-------+------+Flink SQL> SELECT * FROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
Flink SQL> SELECT * FROM TABLE(TUMBLE(DATA => TABLE Bid,TIMECOL => DESCRIPTOR(bidtime),SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+-- apply aggregation on the tumbling windowed table
Flink SQL> SELECT window_start, window_end, SUM(price)FROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+
- Window Aggregate
这就是基于上面的 TVF 的应用。上面 Windowing table-valued functions 提供了数据输入,基于这些数据输入做聚合,就能得到一些统计信息。
SELECT ...
FROM <windowed_table> -- relation applied windowing TVF
GROUP BY window_start, window_end, ...-- hopping window aggregation
Flink SQL> SELECT window_start, window_end, SUM(price)FROM TABLE(HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES))GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:05 | 2020-04-15 08:15 | 15.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
| 2020-04-15 08:15 | 2020-04-15 08:25 | 6.00 |
+------------------+------------------+-------+- GROUPING SET
基于 Window 做一些更高级的窗口函数,按照多种分组方式统计数据。
Flink SQL> SELECT window_start, window_end, supplier_id, SUM(price) as priceFROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))GROUP BY window_start, window_end, GROUPING SETS ((supplier_id), ());
+------------------+------------------+-------------+-------+
| window_start | window_end | supplier_id | price |
+------------------+------------------+-------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | (NULL) | 11.00 |
| 2020-04-15 08:00 | 2020-04-15 08:10 | supplier2 | 5.00 |
| 2020-04-15 08:00 | 2020-04-15 08:10 | supplier1 | 6.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | (NULL) | 10.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | supplier2 | 9.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | supplier1 | 1.00 |
+------------------+------------------+-------------+-------+
-
ROLLUP、CUBE
这些都是 GROUPING SET 的简写,把所有的组合都枚举出来。计算不要钱么?坑爹! ▄█▀█● -
GROUP
这里就是各种分组聚合的语法,包括一般聚合函数,DISTINCT,GROUP BY、GROUPING SET、CUBE、ROLLUP、HAVING 等。
SELECT COUNT(*) FROM Orders; // COUNT, SUM, AVG (average), MAX (maximum) and MIN (minimum) SELECT COUNT(DISTINCT order_id) FROM Orders;SELECT supplier_id, rating, COUNT(*) AS total
FROM (VALUES('supplier1', 'product1', 4),('supplier1', 'product2', 3),('supplier2', 'product3', 3),('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS ((supplier_id, rating), (supplier_id), ());SELECT SUM(amount)
FROM Orders
GROUP BY users
HAVING SUM(amount) > 50;
- OVER () 标准窗口函数
SELECT order_id, order_time, amount,SUM(amount) OVER (PARTITION BY productORDER BY order_timeRANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW) AS one_hour_prod_amount_sum
FROM Orders
- INNER Equi-JOIN
不是在 流上 join,而是和所有数据做 join,过去的、现在的。
SELECT * FROM Orders
INNER JOIN Product
ON Orders.productId = Product.id
- OUTER Equi-JOIN
不是在 流上 join,而是和所有数据做 join,过去的、现在的。
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.idSELECT *
FROM Orders
RIGHT JOIN Product
ON Orders.product_id = Product.idSELECT *
FROM Orders
FULL OUTER JOIN Product
ON Orders.product_id = Product.id
- Temporal Joins
SELECT order_id,price,orders.currency,conversion_rate,order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;
等等。对于 Flink 来说,Join 是它的重头戏。
Flink 也支持常见的 funciton,字符串的,算术运算的,比较的等等。
这篇关于Understanding Flink的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






