本文主要是介绍TCP/IP网络编程之优于select的epoll(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于epoll的回声服务端
在TCP/IP网络编程之优于select的epoll(一)这一章中,我们介绍了epoll的相关函数,接下来给出基于epoll的回声服务端示例。
echo_epollserv.c
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
|
之前解释过关键代码,而且程序结构与select方式没有区别,故省略代码说明。
条件触发和边缘触发
条件触发的方式中,只要输入缓冲有数据就会一直通知该事件。例如,服务端输入缓冲收到50字节的数据时,服务端操作系统将通知该事件(注册到发生变化的文件描述符)。但服务端读取20字节后还剩30字节的情况下,仍会注册事件。也就是说,条件触发方式中,只要输入缓冲中还剩有数据,就将以事件方式再次注册。而边缘触发中输入缓冲收到数据时仅注册一次事件,即使输入缓冲中还留有数据,也不会再进行注册
接下来通过代码了解条件触发的事件注册方式
echo_EPLTserv.c
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
|
上述示例与之前的echo_epollserv.c之间的差异如下:
- 第10行:将调用read函数时使用的缓冲大小缩减为4字节
- 第58行:插入验证epoll_wait函数调用次数的语句
减少缓冲大小是为了阻止服务端一次性读取接收的数据。换言之,调用read函数后,输入缓冲中仍然有数据需要读取。而且会因此注册新的事件并从epoll_wait函数返回时将循环输出“return epoll_wait”字符串。前提是条件触发的工作方式与之前描述一致。接下来观察运行结果
编译echo_EPLTserv.c 并运行
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
运行echo_client ONE:
| 1 2 3 4 5 |
|
运行echo_client TWO:
| 1 2 3 4 5 |
|
从运行结果可以看出,每当接收到客户端数据时,都会注册该事件,并且多次调用epoll_wait函数
边缘触发的服务端实现中必知的两点:
- 通过error变量验证错误原因
- 为了完成非阻塞I/O,更改套接字特性
Linux套接字相关函数一般通过返回-1通知发生错误,虽然知道发生了错误,但仅凭这些内容无法得知产生错误的原因。因此,为了在发生错误时提供额外的信息,Linux声明了全局变量:int errno;为了访问该变量,需要引入error.h头文件,因为此头文件中有上述变量的extern声明。另外,每种函数发生错误时,保存到error变量的值都不同。
下面讲解将套接字改为非阻塞方式的方法,Linux提供更改或读取文件属性的如下方法:
| 1 2 |
|
- filedes:属性更改目标的文件描述符
- cmd:表示函数调用的目的
从上述声明中可以看到,fcntl具有可变参数形式。如果向第二个参数传递F_GETFL,可以获得第一个参数所指的文件描述符属性(int型)。反之,如果传递F_SETFL,可以更改文件描述符属性。若希望将文件(套接字)改为非阻塞模式,需要如下两条语句
| 1 2 |
|
通过第一条语句获取之前设置的属性信息,通过第二条语句在此基础上添加非阻塞O_NONBLOCK标志。调用read和write函数时,无论是否存在数据,都会形成非阻塞文件(套接字)
echo_EPETserv.c
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
|
- 第11行:为了验证边缘触发的工作方式,将缓冲设置为4个字节
- 第61行:为观察事件发生数而添加的输出字符串的语句
- 第68、69行:第68行将accept函数创建的套接字改为非阻塞模式,第69行向EPOLLIN添加EPOLLET标志,将套接字事件注册方式改为边缘触发
- 第76、78行:之前的条件触发回声服务端中没有while循环,边缘触发方式中,发生事件时需要读取输入缓冲中的所有数据,因此需要循环调用read函数,如第78行所示
- 第86行:read函数返回-1且errno值为EAGAIN时,意味着读取了输入缓冲中的全部数据,因此需要通过break语句跳出第76行的循环
编译echo_EPETserv.c运行
| 1 2 3 4 5 6 7 8 |
|
运行客户端程序
| 1 2 3 4 5 6 7 8 9 |
|
上述运行结果中需要注意的是,客户端发送消息次数和服务端epoll_wait函数调用次数。客户端从请求连接到断开连接共发送数据5次,服务端也相应产生5个事件
条件触发和边缘触发孰优孰劣
我们从理论和代码的角度充分理解了条件触发和边缘触发,但仅凭这些还无法理解边缘触发相对于条件触发的优点。边缘触发可以做到分离接收数据和处理时间的时间点。虽然比较简单,但非常准确有力地说明了边缘触发的优点,现在我们来看图1-1
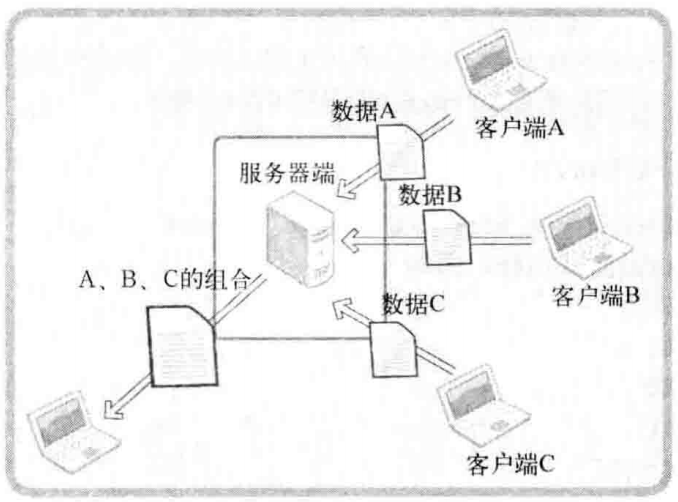
图1-1 理解边缘触发
图1-1的运行流程如下:
- 服务端分别从客户端A、B、C接收数据
- 服务端按照A、B、C的顺序重新组合收到的数据
- 组合的数据将发送给任意主机
为了完成该过程,若能按如下流程运行程序,服务端的实现并不难
- 客户端按照A、B、C的顺序连接服务端,并依序向服务端发送数据
- 需要接收数据的客户端应在客户端A、B、C之前连接到服务端并等待
但现实中可能频繁出现如下这些情况,换言之,如下情况更符合实际
- 客户端C和B向服务端发送数据,但A尚未连接到服务端
- 客户端A、B、C乱序发送数据
- 服务端已收到数据,但要接收数据的目标客户端还未连接到服务端
因此,即使输入缓冲收到数据(注册相应事件),服务端也能决定读取和处理这些数据的时间点,这样就给服务端的实现带来巨大的灵活性。
那么,条件触发中无法区分数据接收和处理吗?并非不可能。但在输入缓冲收到数据的情况下,如果不读取(延迟处理),则每次调用epoll_wait函数时都会产生相应事件。而且事件数也会累加,服务端能承受吗?这在现实中是不合理的
条件触发和边缘触发的区别主要应从服务端实现模型的角度讨论,从实现模型来看,边缘触发更有可能带来高性能,但不能简单地认为“只要使用边缘触发就一定能提高速度”
https://www.cnblogs.com/beiluowuzheng/p/9696641.html#top
这篇关于TCP/IP网络编程之优于select的epoll(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






