本文主要是介绍VTM可视化、统计(探索中),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
VTM可视化、统计(探索中)
参考博客 https://blog.csdn.net/Zzhaoyongbo/article/details/109136642
另外参考官方手册 VVCSoftware_VTM-master\doc\software-manual.pdf

一、如何配置VTM?https://blog.csdn.net/tiyloving/article/details/114323276
二、在配置好各个参数后,如何使用DecoderAnalyser 获取编码信息?
1、首先在vs中的TypeDef.h文件中查找 ENABLE_TRACING、K0149_BLOCK_STATISTICS,并设置为1(相当于打开开关);除此之外,打开BLOCK_STATS_AS_CSC 可以得到CSV格式的数据(但不支持可视化),方便导入excel中,不打开的话得到的格式如下图。
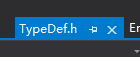
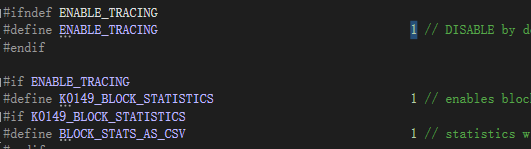

2、需要注意的是,该宏定义需要在编码前开启,最终才能得到编码信息。
在编解码后,运行DecoderAnalyserApp.exe ,参数命令为 -b str.bin --TraceFile=“str_coded1.vtmbmsstats” --TraceRule=“D_BLOCK_STATISTICS_CODED:poc>=0”
其中-b 是在编解码中生成的bin文件
–TraceFile="str_coded1.vtmbmsstats"是输出的vtmbmsstats文件名字,最后一句相当于选择统计模式,有两种方式可选择,具体参见手册


之后运行即可,此时会得到想要的文件,用excel等打开即可;如果是cvs格式,用excel打开后分列即可

三、可视化
下载软件 https://github.com/IENT/YUView
找到对应的版本,https://github.com/IENT/YUView/releases

2、打开,在下图位置右键添加一个overlay,并将重建的YUV文件和.vtmbmsstats 文件拖进去,注意顺序,要YUV再上。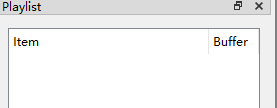
之后单击yuv,调整视频的参数,比如大小(416×240)和位深(8→10)

然后点击Overlay.Item
在右边框里选择你要显示的内容就可以了。

这篇关于VTM可视化、统计(探索中)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







