本文主要是介绍【教学类-50-06】20240410“数一数”4类星号图片制作PDF学具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作品展示:
背景需求:
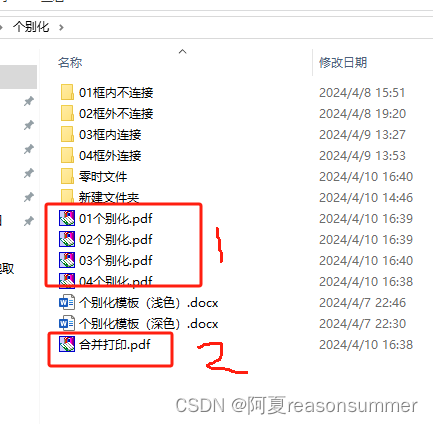
前文遍历四个文件夹,分别将每个文件夹内的10个图片的左上角加入星号,显示难度系数
【教学类-50-05】20240410“数一数”4类图片添加“难度星号”-CSDN博客文章浏览阅读55次,点赞2次,收藏2次。【教学类-50-05】20240410“数一数”4类图片添加“难度星号”https://blog.csdn.net/reasonsummer/article/details/137595258
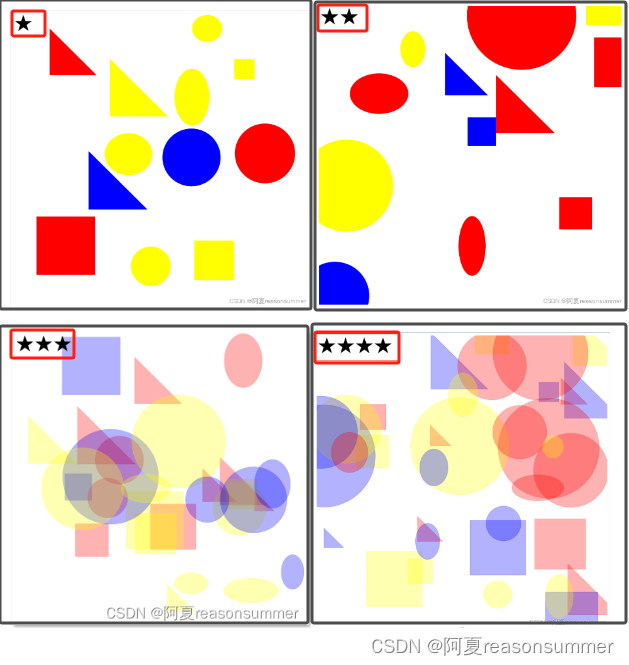
素材准备:
一、深色模板

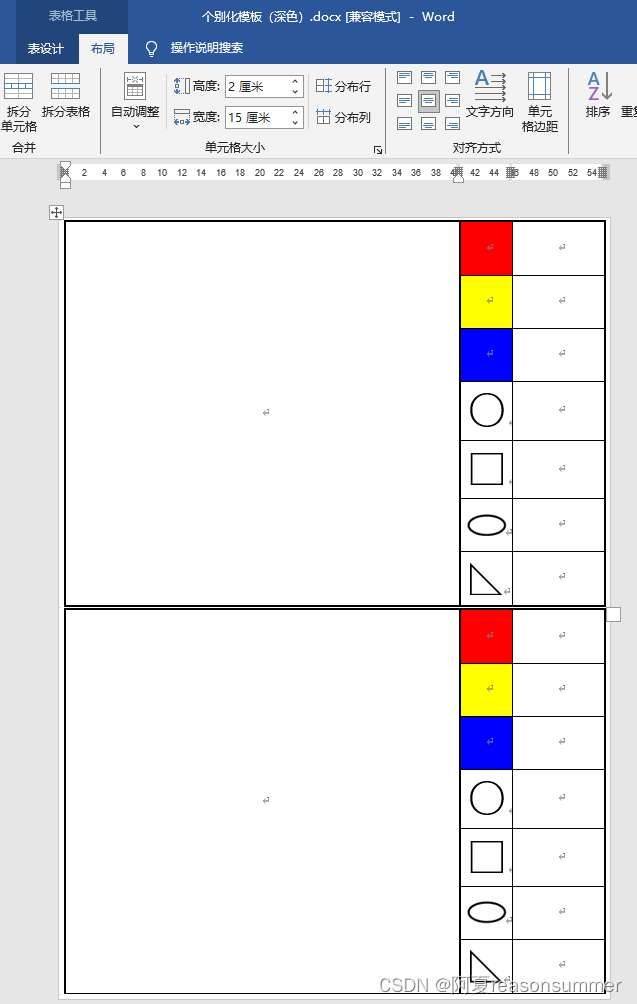
二、浅色模板
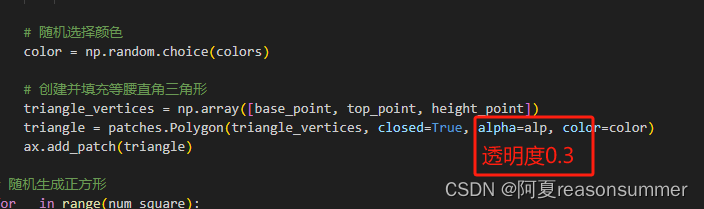
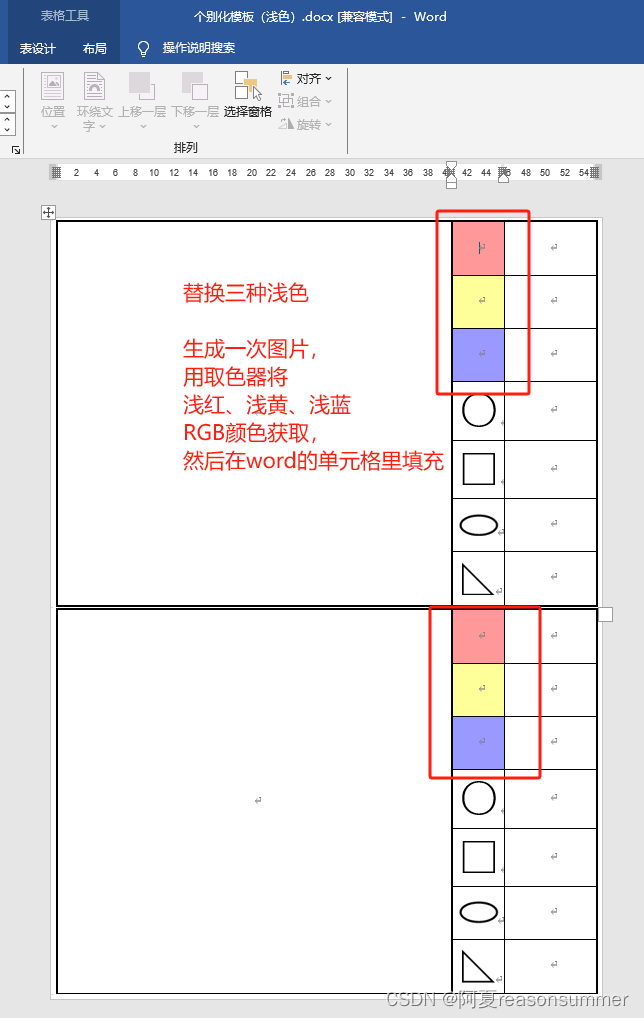
代码展示
'''
把图片插入模板,生成4个pdf,合并成1个打印用的pdf
作者:AI对话大师,阿夏
时间:2024年4月8日
'''import os,time
import glob
from docx import Document
from docx.shared import Cmpath = r'C:\Users\jg2yXRZ\OneDrive\桌面\个别化'item=['01框内不连接','02框外不连接','03框内连接','04框外连接']
mb=['深','深','浅','浅']for r in range(len(item)):input_folder = os.path.join(path, f'{item[r]}')output_folder = os.path.join(path, '零时文件')# 创建输出文件夹if not os.path.exists(output_folder):os.makedirs(output_folder)# 获取234文件夹内的所有png图片路径image_files = glob.glob(os.path.join(input_folder, '*.png'))# 创建新的docx文档doc = Document(path + fr'\个别化模板({mb[r]}色).docx')# 插入图片到表格中的00格子for i, img_path in enumerate(image_files):table = doc.tables[i % 2]cell = table.cell(0, 0)cell.paragraphs[0].clear() # 清空单元格中原有内容cell.paragraphs[0].alignment = 1 # 设置居中对齐run = cell.paragraphs[0].add_run()run.add_picture(img_path, width=Cm(14.6), height=Cm(14.6))# 每插入两张图片保存一次文件if (i+1) % 2 == 0:doc.save(os.path.join(output_folder, f'{i//2:02d}.docx'))# # 保存为docx文件# doc.save(os.path.join(output_folder, f'{len(image_files)//2:02d}.docx'))time.sleep(1)# 将10个docx转为PDFimport osfrom docx2pdf import convertfrom PyPDF2 import PdfFileMerger# from PyPDF4 import PdfMerger# output_folder = output_folderpdf_output_path = path+fr'\{r+1:02d}个别化.pdf'# 将所有DOCX文件转换为PDFfor docx_file in os.listdir(output_folder):if docx_file.endswith('.docx'):docx_path = os.path.join(output_folder, docx_file)convert(docx_path, docx_path.replace('.docx', '.pdf'))# 合并零时文件里所有PDF文件merger = PdfFileMerger()for pdf_file in os.listdir(output_folder):if pdf_file.endswith('.pdf'):pdf_path = os.path.join(output_folder, pdf_file)merger.append(pdf_path)time.sleep(2)# 保存合并后的PDF文件merger.write(pdf_output_path)merger.close()import shutil# 删除输出文件夹shutil.rmtree(output_folder)# 四个文件合并import os
from PyPDF2 import PdfMergerall_folder = r'C:\Users\jg2yXRZ\OneDrive\桌面\个别化'
output_file = all_folder+r'\合并打印.pdf'# 创建一个PdfMerger对象
merger = PdfMerger()# 遍历输入文件夹中的所有PDF文件
for filename in os.listdir(all_folder):if filename.endswith('.pdf'):filepath = os.path.join(all_folder, filename)merger.append(filepath)# 合并PDF文件并保存为输出文件
merger.write(output_file)
merger.close()
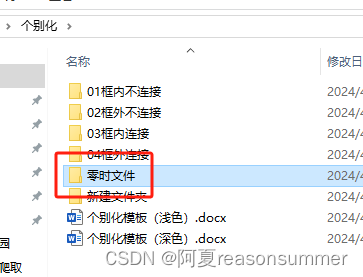
1:生成5个docx(10张图片)
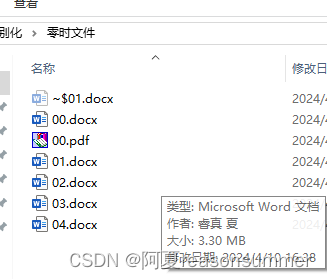
2:把5个docx转成5个PDF
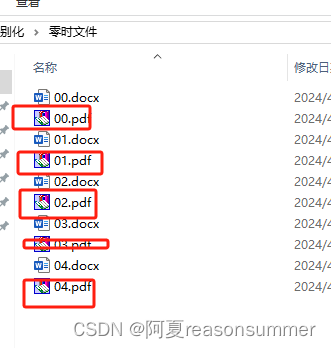
3、读取零食文件里面的所有PDF,合并01个别化.pdf
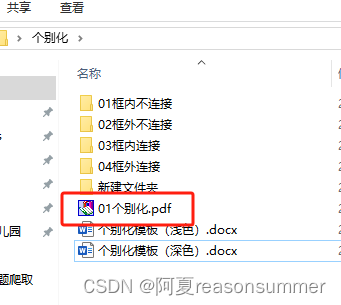
4、01-04.pdf都生成后,合并成一个PDF
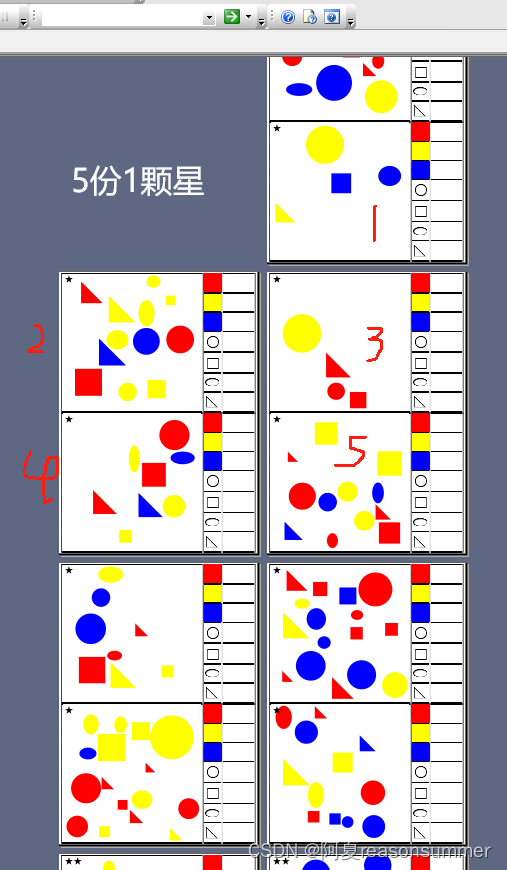
作品展示:

打印设置
正反打印(一张纸等于2份,每份正反2个题目)




我每套随机生成20张,删除星号把图形遮住的图片,每种打印3张,切开6分(每份正反两套题目)





裁切边缘




塑封(便于反复使用)





完成了
感悟:
1、 AI对话大师编写python代码,让我在设计和制作“幼儿个别化学习的学具”时,如虎添翼,设计出层次性(1-4颗星)、随机性(每张图案的出现的数量、形成的颜色、图案的大小都不同)的“数一数”益智区材料。
2、 AI对话大师+python代码让一些我曾经想过但无法实现的学具内容和样式(如迷宫图、拼图、随机图案点数等),在2024年顺利诞生!真正展现了技术改变思维,编程优化教学的作用
这篇关于【教学类-50-06】20240410“数一数”4类星号图片制作PDF学具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






