本文主要是介绍ABAP 前导0的处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前导0这个东西真的很烦,经常因为前导0导致连接条件有问题,出不来数据,这里就总结一下前导0 在sql语句中的添加和去除
文章目录
- ABAP 前导0的处理
- 添加前导0-自适应
- 运行结果
- 去除前导0
- 方法一、使用SUBSTRING截取
- 运行结果
- 方法二、去零法
- 运行结果
ABAP 前导0的处理
添加前导0-自适应
应用场景:需要用前导0来填充某些字段
REPORT z_test_zero_lhy.SELECTcarrid, "航线connid, "航班号lpad( connid, 10, '0' ) AS connid_l "在前面添加前导0,填充到10个长度为止FROM sflightINTO TABLE @DATA(lt_lpad).cl_demo_output=>display( lt_lpad ).运行结果
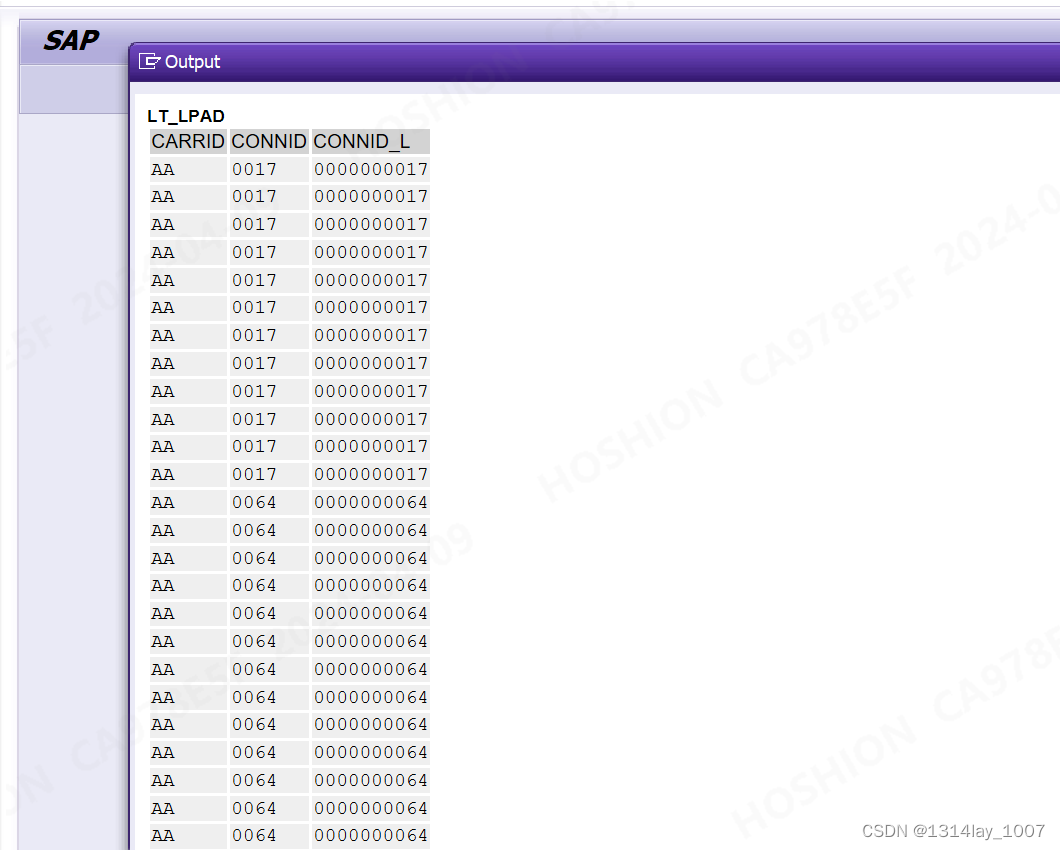
在没有添加前导0的时候,查询不到数据
REPORT z_test_zero_lhy.DATA: BEGIN OF gs_data,werks TYPE mseg-werks,matnr TYPE marc-matnr,END OF gs_data.DATA gt_data LIKE TABLE OF gs_data.gs_data-werks = '1000'.
gs_data-matnr = '1781'.
APPEND gs_data TO gt_data.SELECTb~werks,b~matnr,c~maktxFROM @gt_data AS aLEFT JOIN marc AS b ON a~werks = b~werks AND a~matnr = b~matnrLEFT JOIN makt AS c ON a~matnr = c~matnrWHERE c~spras = @sy-languINTO TABLE @DATA(lt_matnr).cl_demo_output=>display( lt_matnr ).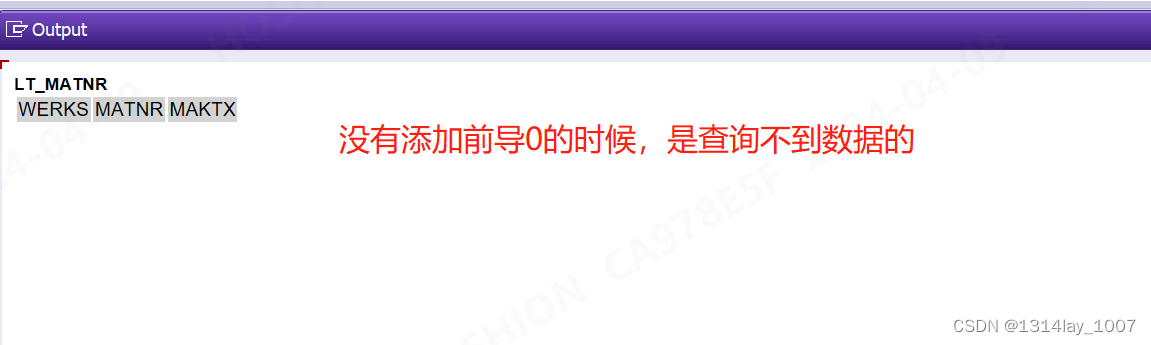
添加前导0之后
REPORT z_test_zero_lhy.DATA: BEGIN OF gs_data,werks TYPE mseg-werks,matnr TYPE marc-matnr,END OF gs_data.DATA gt_data LIKE TABLE OF gs_data.gs_data-werks = '1000'.
gs_data-matnr = '1781'.
APPEND gs_data TO gt_data.SELECTb~werks AS marc_werks,b~matnr AS marc_matnr,c~maktxFROM @gt_data AS aLEFT JOIN marc AS b ON a~werks = b~werks AND lpad( a~matnr,18,'0' ) = b~matnrLEFT JOIN makt AS c ON lpad( a~matnr,18,'0' ) = c~matnrWHERE c~spras = @sy-languINTO TABLE @DATA(lt_matnr).cl_demo_output=>display( lt_matnr ).在添加完前导0之后,才可以查询出相关的数据:
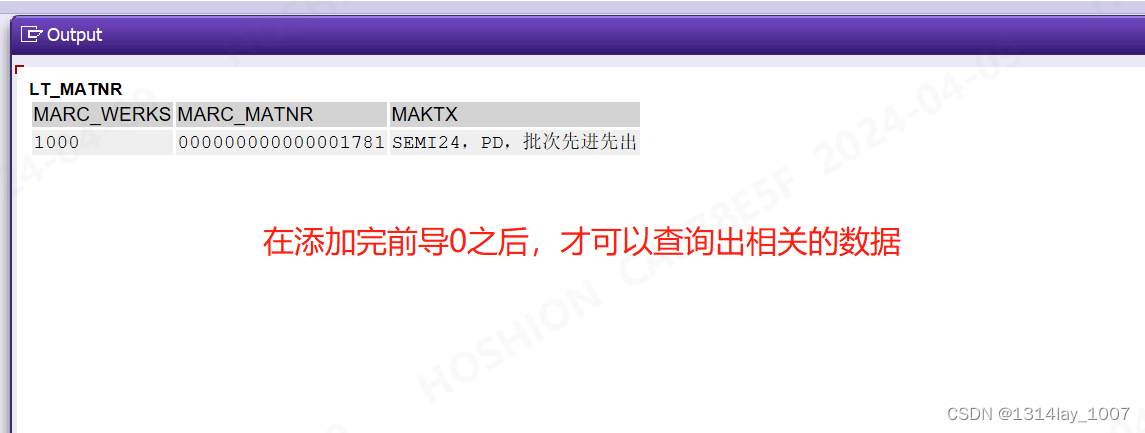
去除前导0
应用场景
A表A1字段取值后面两位与B表B1字段进行匹配连表,即连接条件的两个字段的长度不相等的时候,需要截取一段长度
方法一、使用SUBSTRING截取
这个方法适用于知道需要截取的位数,如下:
REPORT z_test_zero_lhy."工厂和供应商连接
SELECTmarc~werks, "工厂marc~matnr, "物料l~lifnr "供应商或债权人的帐号FROM marcLEFT JOIN lfa1 AS l ON substring( l~lifnr,7,4 ) = marc~werks "substring 供应商号 第七位开始取值4位 与 工厂匹配WHERE marc~werks = '1000'INTO TABLE @DATA(lt_temp)UP TO 20 ROWS.IF sy-subrc = 0.cl_demo_output=>display( lt_temp ).ENDIF.运行结果
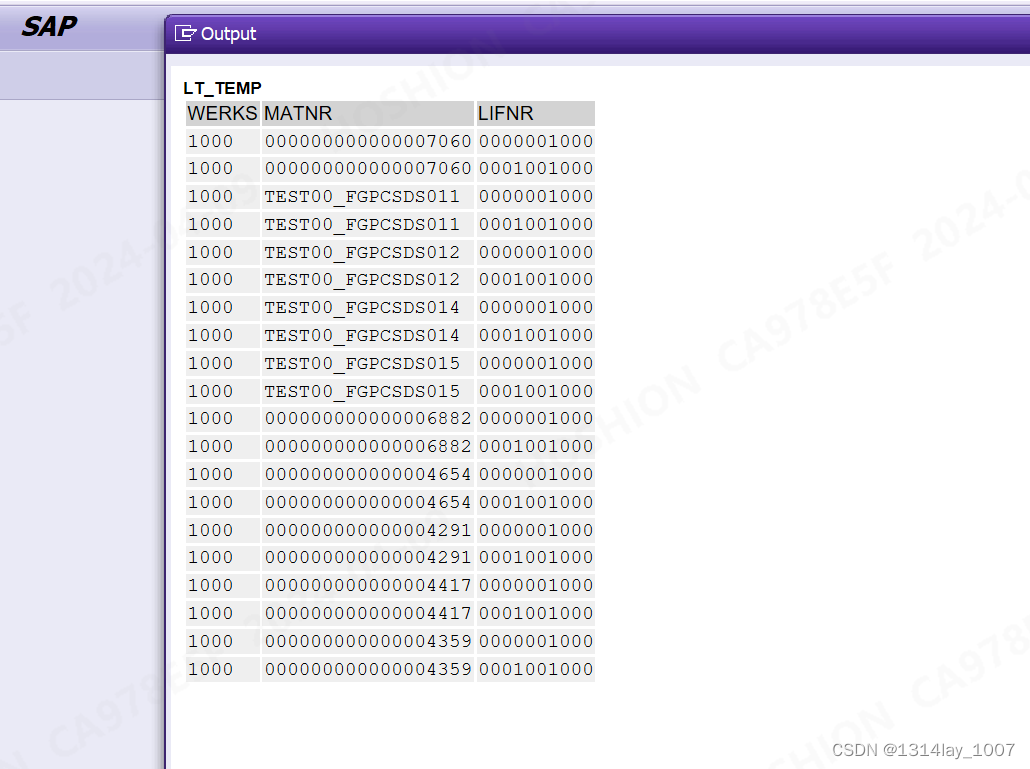
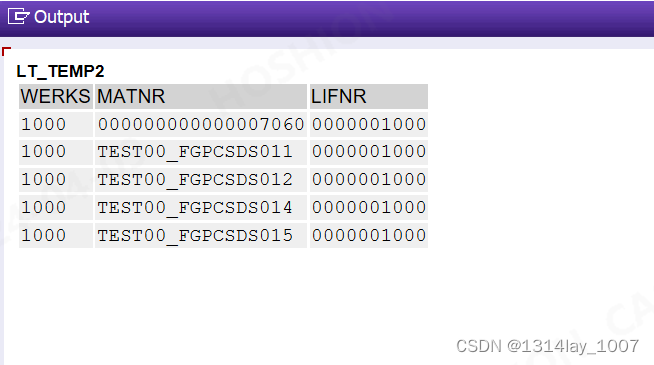
方法二、去零法
这个方法适用于不知道需要截取位数的情况下,可以使用去零法
LTRIM( arg, char ), String with the content of arg in which all trailing blanks and leading characters are removed that match the character in char. A blank in char is significant.
翻译:内容为arg的字符串,删除所有与char中字符匹配的尾随空格和前导字符。char中的空白是重要的。
"工厂和供应商连接
SELECTmarc~werks, "工厂marc~matnr, "物料l~lifnr "供应商或债权人的帐号FROM marcLEFT JOIN lfa1 AS l ON ltrim( l~lifnr,'0' ) = marc~werks "ltrim 供应商号 去掉0WHERE marc~werks = '1000'INTO TABLE @DATA(lt_temp2)UP TO 5 ROWS.IF sy-subrc = 0.cl_demo_output=>display( lt_temp2 ).ENDIF.运行结果
这篇关于ABAP 前导0的处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




