本文主要是介绍【JavaWeb】Day39.MySQL概述——数据库设计-DQL(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据库设计-DQL
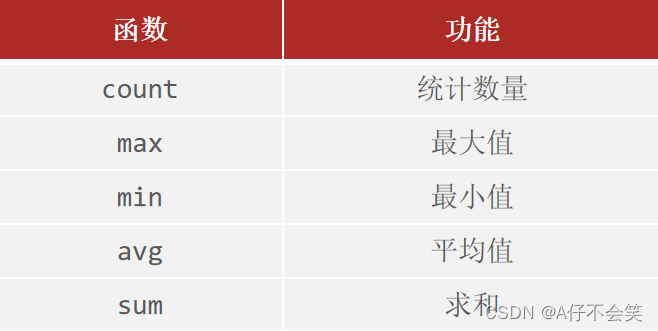
聚合函数
聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
语法:
select 聚合函数(字段列表) from 表名 ;
注意 : 聚合函数会忽略空值,对NULL值不作为统计。
- count :按照列去统计有多少行数据。
在根据指定的列统计的时候,如果这一列中有null的行,该行不会被统计在其中。
- sum :计算指定列的数值和,如果不是数值类型,那么计算结果为0
- max :计算指定列的最大值
- min :计算指定列的最小值
- avg :计算指定列的平均值
案例1:统计该企业员工数量
~~~mysql
# count(字段)
select count(id) from tb_emp;-- 结果:29
select count(job) from tb_emp;-- 结果:28 (聚合函数对NULL值不做计算)# count(常量)
select count(0) from tb_emp;
select count('A') from tb_emp;# count(*) 推荐此写法(MySQL底层进行了优化)
select count(*) from tb_emp;
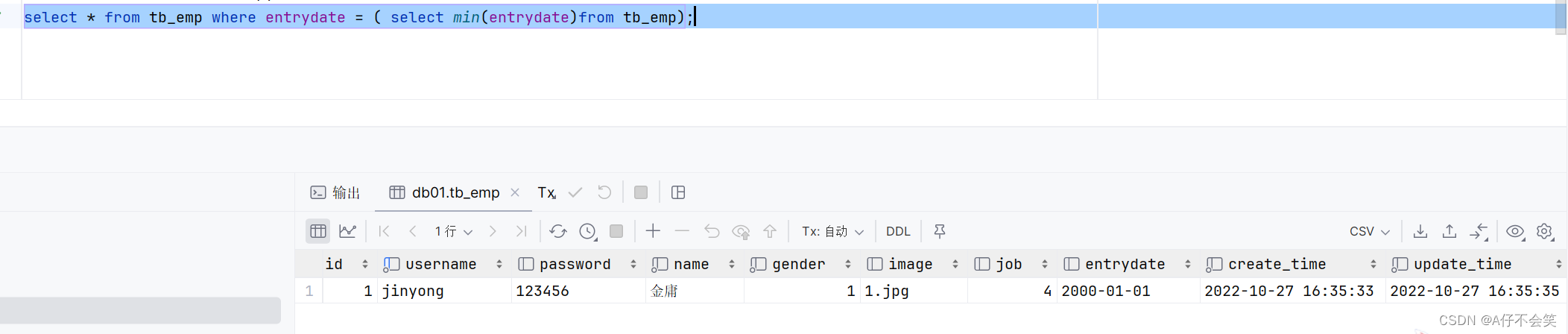
~~~案例2:统计该企业最早入职的员工(使用子嵌套)
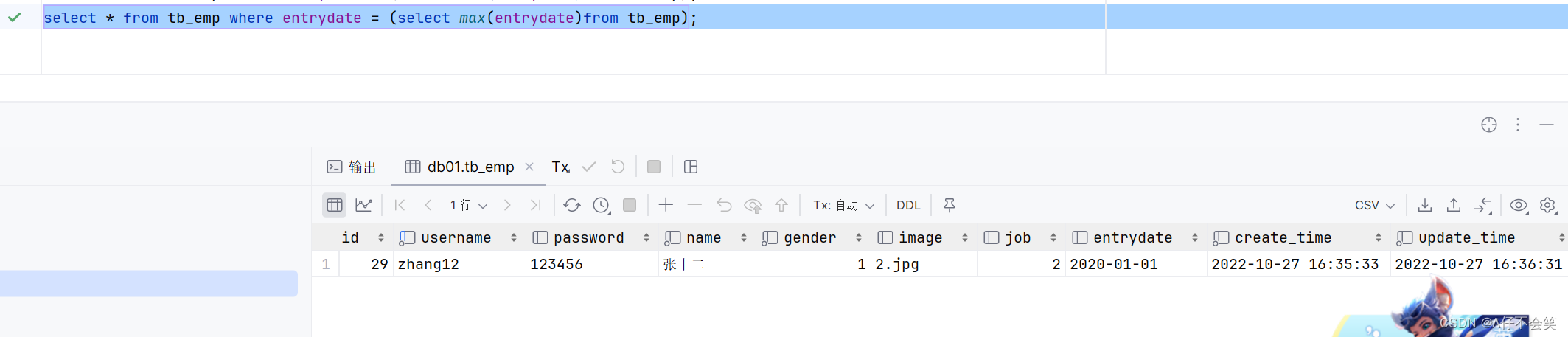
案例3:统计该企业最迟入职的员工
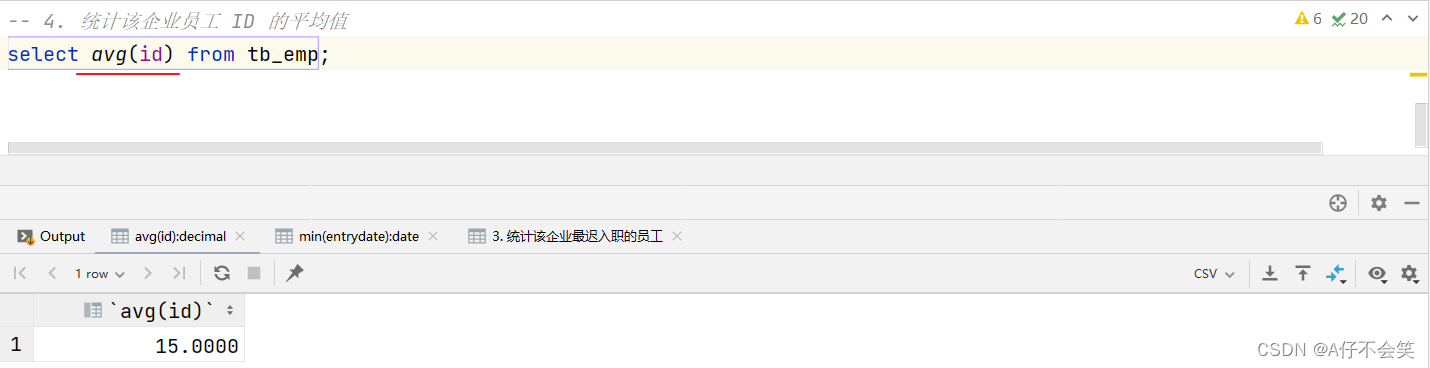
案例4:统计该企业员工 ID 的平均值
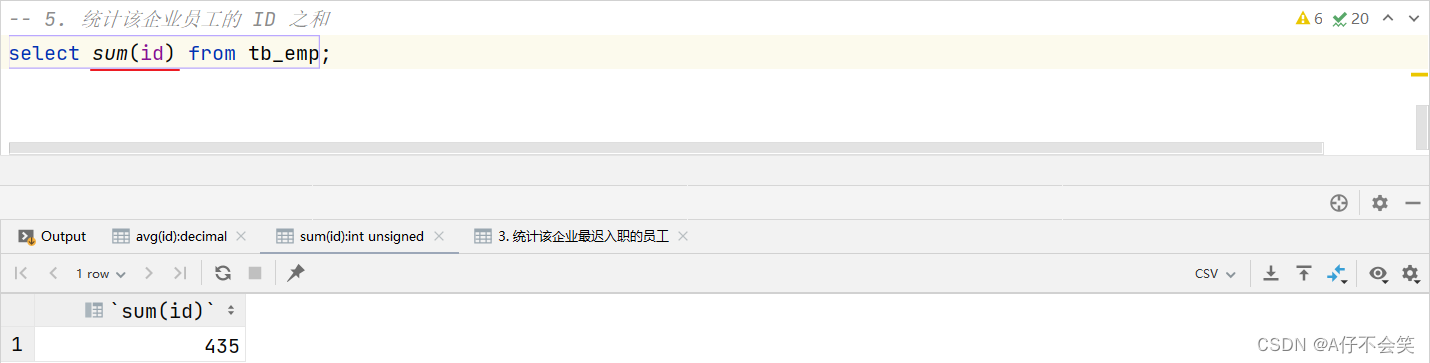
案例5:统计该企业员工的 ID 之和
分组查询
分组: 按照某一列或者某几列,把相同的数据进行合并输出。
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。分组查询通常会使用聚合函数进行计算。
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
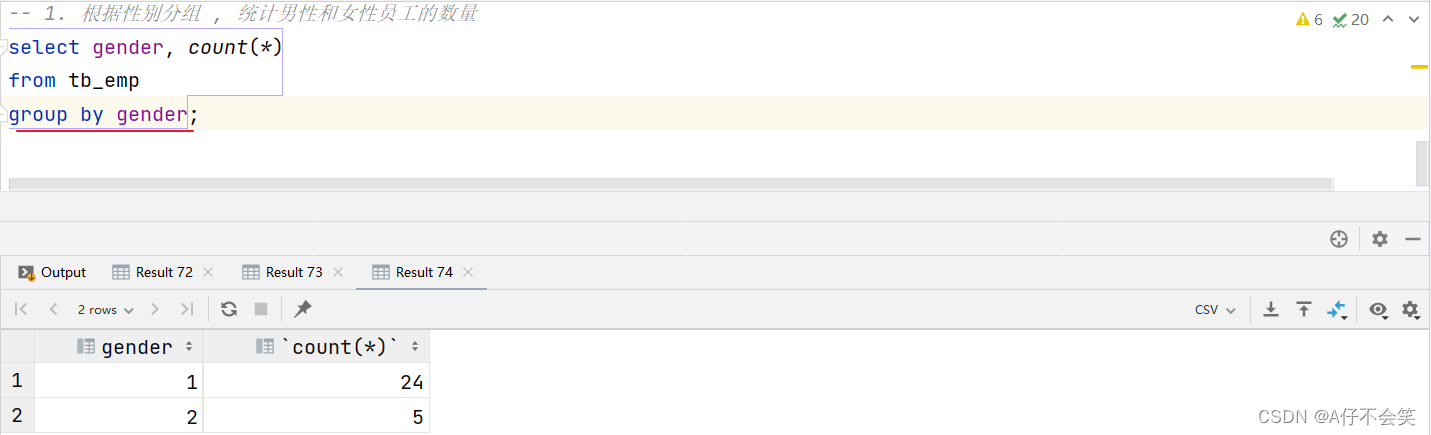
案例1:根据性别分组 , 统计男性和女性员工的数量
select gender, count(*) from tb_emp
group by gender; -- 按照gender字段进行分组(gender字段下相同的数据归为一组)
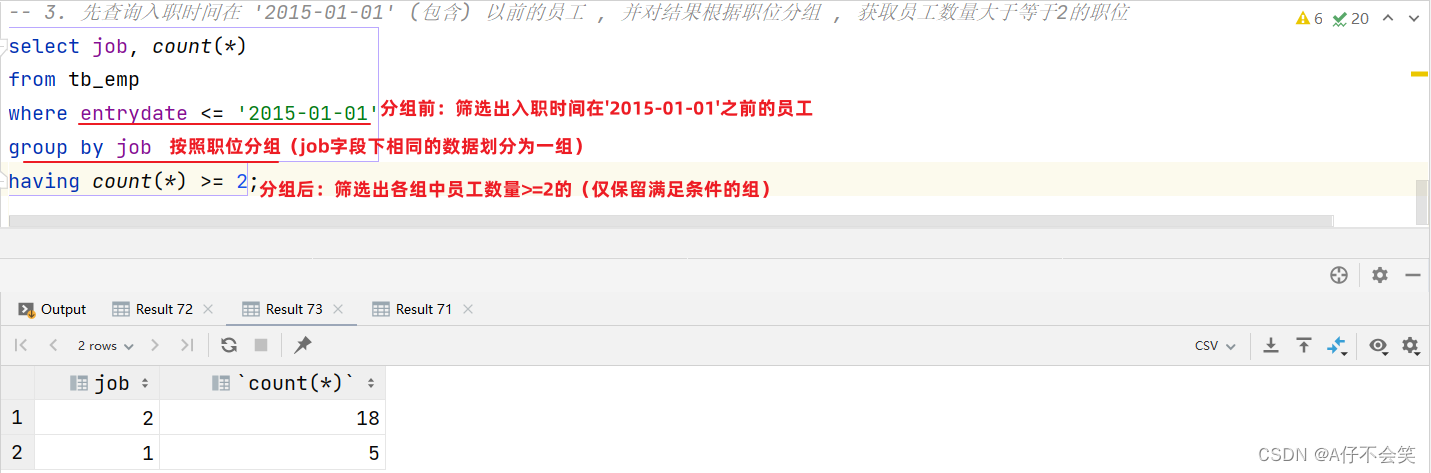
案例2:查询入职时间在 '2015-01-01' (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位
注意事项:
• 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
• 执行顺序:where > 聚合函数 > having
where与having区别:
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
语法:
select 字段列表
from 表名
[where 条件列表]
[group by 分组字段 ]
order by 字段1 排序方式1 , 字段2 排序方式2 … ;
排序方式:
ASC :升序(默认值)
DESC:降序
案例1:根据入职时间, 对员工进行升序排序
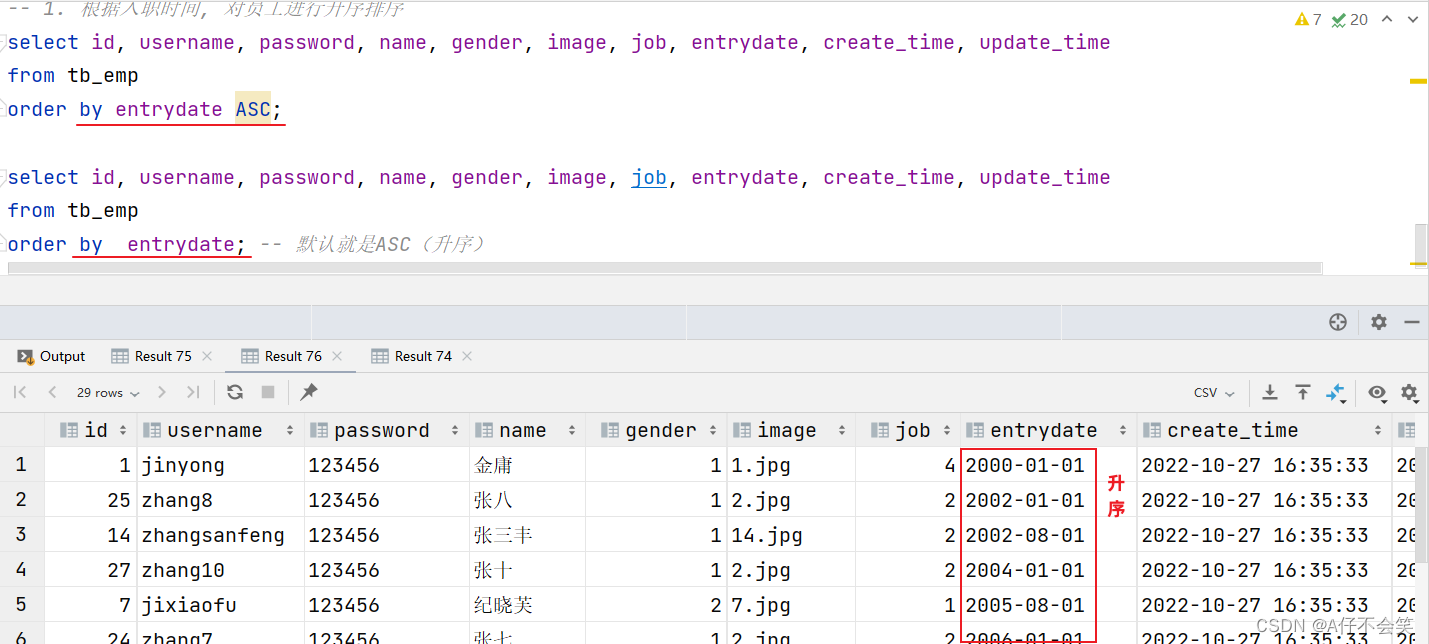
注意事项:如果是升序, 可以不指定排序方式ASC
案例2:根据入职时间,对员工进行降序排序
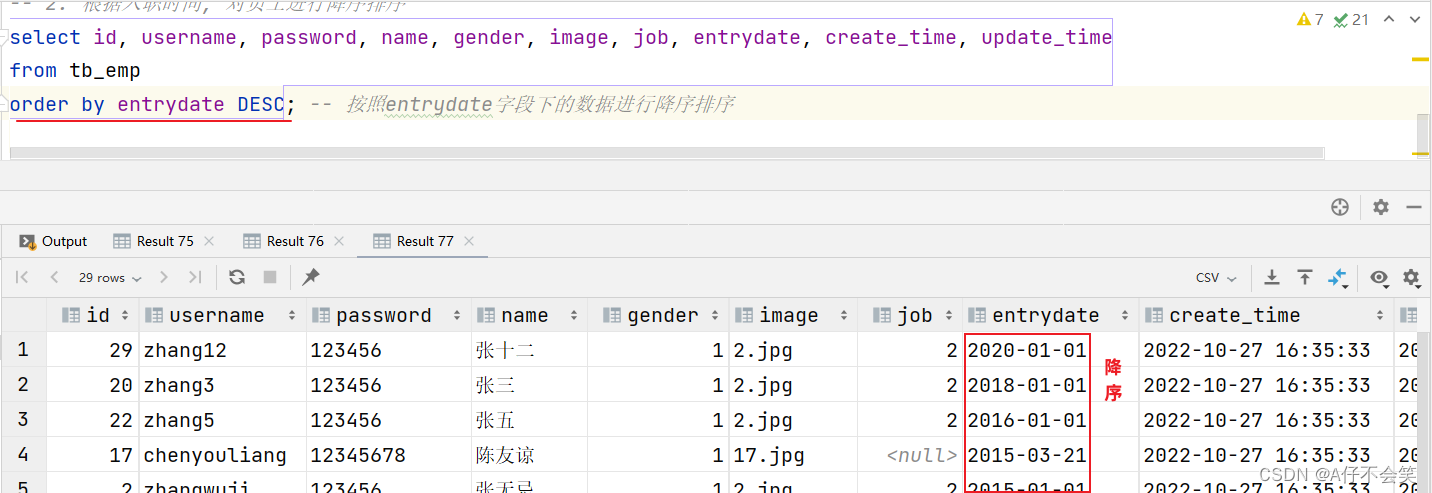
案例3:根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
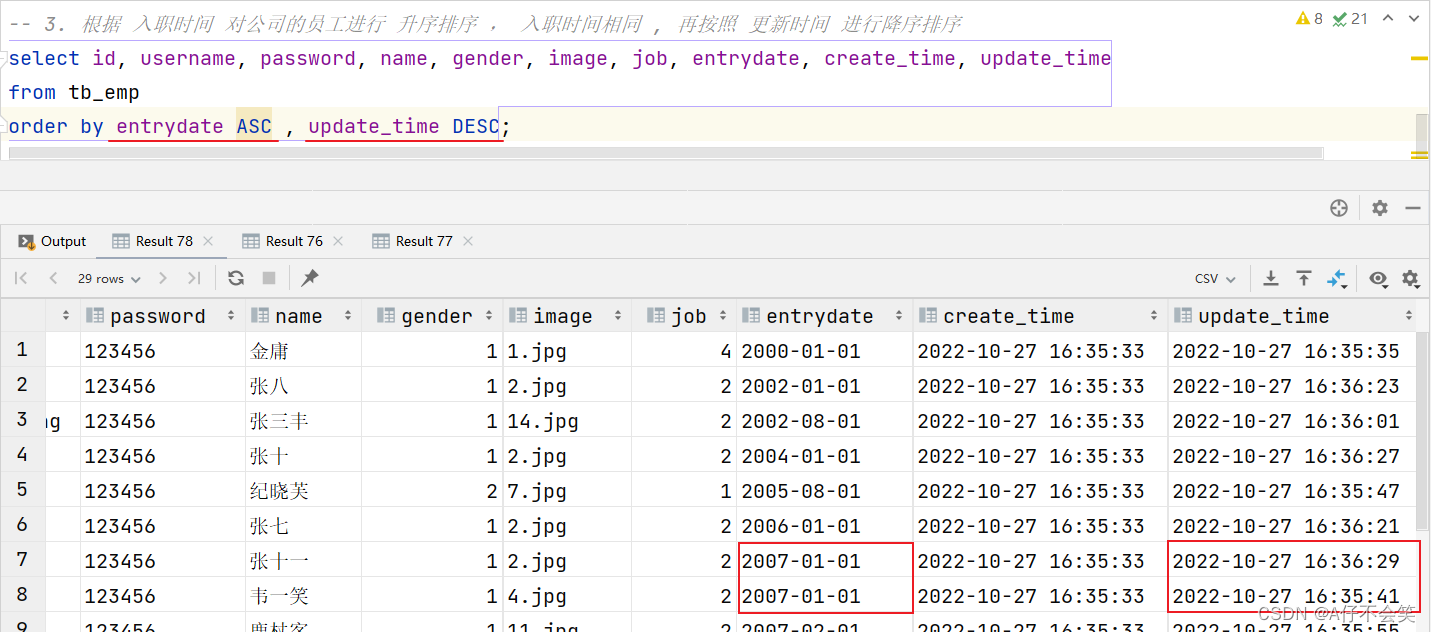
注意事项:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,日常我们在网站中看到的各种各样的分页条,后台也都需要借助于数据库的分页操作。
分页查询语法:
select 字段列表 from 表名 limit 起始索引, 查询记录数 ;
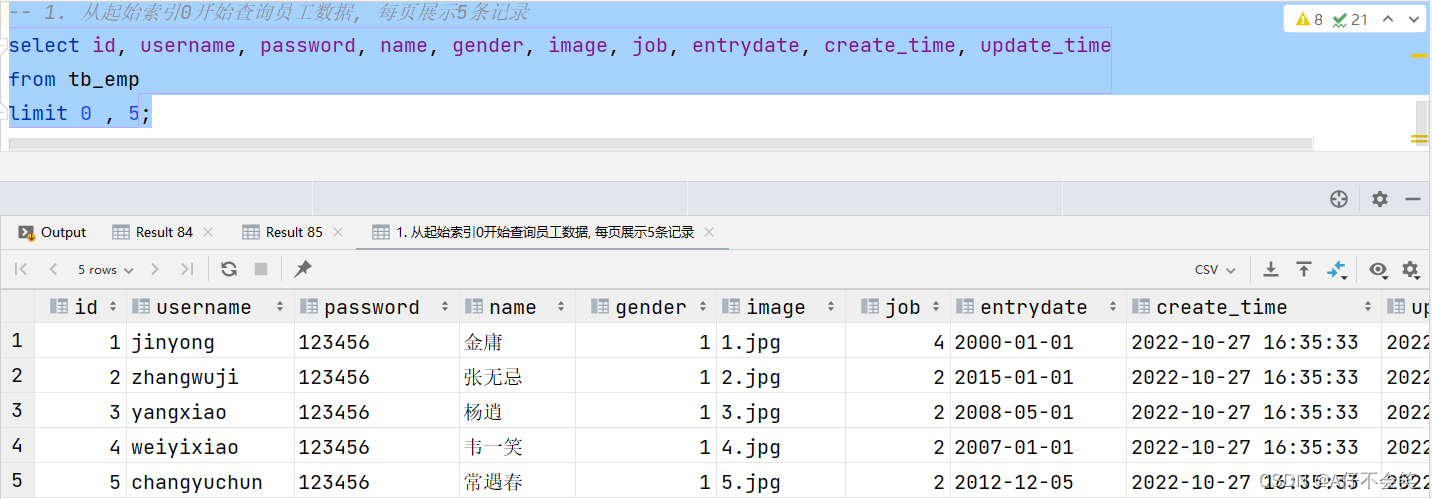
案例1:从起始索引0开始查询员工数据, 每页展示5条记录
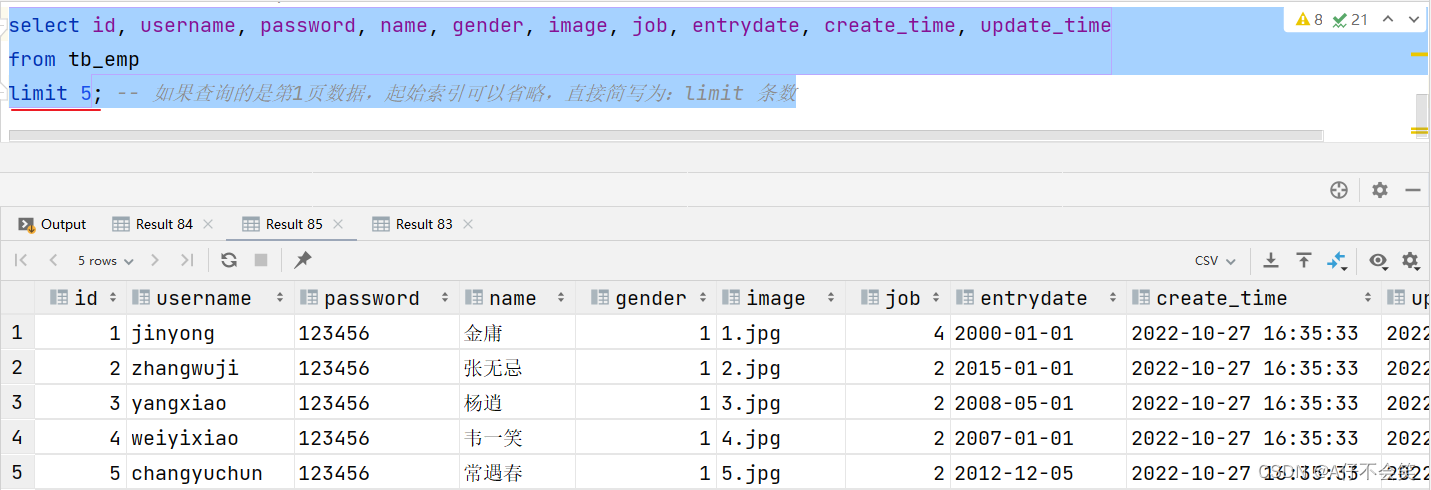
案例2:查询 第1页 员工数据, 每页展示5条记录
案例3:查询 第2页 员工数据, 每页展示5条记录
注意事项:
1. 起始索引从0开始。 计算公式 : 起始索引 = (查询页码 - 1)* 每页显示记录数
2. 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT
3. 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 条数
这篇关于【JavaWeb】Day39.MySQL概述——数据库设计-DQL(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




