本文主要是介绍(转载)Oracle关于pivot与unpivot用法介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Pivot 和 Unpivot
使用简单的 SQL 以电子表格类型的交叉表报表显示任何关系表中的信息,并将交叉表中的所有数据存储到关系表中。
如您所知,关系表是表格化的,即,它们以列-值对的形式出现。假设一个表名为 CUSTOMERS。
Pivot
SQL> desc customersName Null? Type----------------------------------------- -------- ---------------------------CUST_ID NUMBER(10)CUST_NAME VARCHAR2(20)STATE_CODE VARCHAR2(2)TIMES_PURCHASED NUMBER(3)
选定该表:
select cust_id, state_code, times_purchased
from customers
order by cust_id;输出结果如下:
CUST_ID STATE_CODE TIMES_PURCHASED ------- ---------- ---------------1 CT 12 NY 103 NJ 24 NY 4 ... and so on ...
注意数据是如何以行值的形式显示的:针对每个客户,该记录显示了客户所在的州以及该客户在商店购物的次数。当该客户从商店购买更多物品时,列 times_purchased 会进行更新。
现在,假设您希望统计一个报表,以了解各个州的购买频率,即,各个州有多少客户只购物一次、两次、三次等等。如果使用常规 SQL,您可以执行以下语句:
select state_code, times_purchased, count(1) cnt
from customers
group by state_code, times_purchased;
输出如下:
ST TIMES_PURCHASED CNT -- --------------- ---------- CT 0 90 CT 1 165 CT 2 179 CT 3 173 CT 4 173 CT 5 152 ... and so on ...
这就是您所要的信息,但是看起来不太方便。使用交叉表报表可能可以更好地显示这些数据,这样,您可以垂直排列数据,水平排列各个州,就像电子表格一样:
Times_purchasedCT NY NJ ... and so on ...1 0 1 0 ... 2 23 119 37 ... 3 17 45 1 ... ... and so on ...
在 Oracle 数据库 11g 推出之前,您需要针对每个值通过 decode 函数进行以上操作,并将每个不同的值编写为一个单独的列。但是,该方法一点也不直观。
庆幸的是,您现在可以使用一种很棒的新特性 PIVOT 通过一种新的操作符以交叉表格式显示任何查询,该操作符相应地称为 pivot。下面是查询的编写方式:
select * from (select times_purchased, state_codefrom customers t
)
pivot
(count(state_code)for state_code in ('NY','CT','NJ','FL','MO')
)
order by times_purchased
输出如下:
. TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO' --------------- ---------- ---------- ---------- ---------- ----------0 16601 90 0 0 01 33048 165 0 0 02 33151 179 0 0 03 32978 173 0 0 04 33109 173 0 1 0 ... and so on ...
这表明了 pivot 操作符的威力。state_codes 作为标题行而不是列显示。下面是传统的表格化格式的图示:

图 1 传统的表格化显示
在交叉表报表中,您希望将 Times Purchased 列的位置掉换到标题行,如图 2 所示。该列变为行,就好像该列逆时针旋转 90 度而变为标题行一样。该象征性的旋转需要有一个支点 (pivot point),在本例中,该支点为 count(state_code) 表达式。
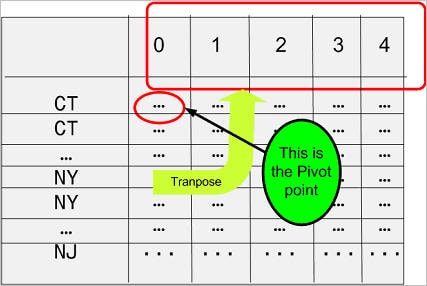
图 2 执行了 Pivot 操作的显示
该表达式需要采用以下查询语法:
...
pivot
(count(state_code)for state_code in ('NY','CT','NJ','FL','MO')
)
...
第二行“for state_code ...”限制查询对象仅为这些值。该行是必需的,因此不幸的是,您需要预先知道可能的值。该限制在 XML 格式的查询将有所放宽,如本文后面部分所述。
注意输出中的标题行:
. TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'--------------- ---------- ---------- ---------- ---------- ----------
列标题是来自表本身的数据:州代码。缩写可能已经相当清楚无需更多解释,但是假设您希望显示州名而非缩写(“Connecticut”而非“CT”),那又该如何呢?如果是这样,您需要在查询的 FOR 子句中进行一些调整,如下所示:
select * from (select times_purchased as "Puchase Frequency", state_codefrom customers t
)
pivot
(count(state_code)for state_code in ('NY' as "New York",'CT' "Connecticut",'NJ' "New Jersey",'FL' "Florida",'MO' as "Missouri")
)
order by 1
Puchase Frequency New York Connecticut New Jersey Florida Missouri ----------------- ---------- ----------- ---------- ---------- ----------0 16601 90 0 0 01 33048 165 0 0 02 33151 179 0 0 03 32978 173 0 0 04 33109 173 0 1 0 ... and so on ...
FOR 子句可以提供其中的值(这些值将成为列标题)的别名。
Unpivot
就像有物质就有反物质一样,有 pivot 就应该有“unpivot”,对吧?
好了,不开玩笑,但 pivot 的反向操作确实需要。假设您有一个显示交叉表报表的电子表格,如下所示:
| Purchase Frequency | New York | Connecticut | New Jersey | Florida | Missouri |
| 0 | 12 | 11 | 1 | 0 | 0 |
| 1 | 900 | 14 | 22 | 98 | 78 |
| 2 | 866 | 78 | 13 | 3 | 9 |
| ... | . |
现在,您希望将这些数据加载到一个名为 CUSTOMERS 的关系表中:
SQL> desc customersName Null? Type----------------------------------------- -------- ---------------------------CUST_ID NUMBER(10)CUST_NAME VARCHAR2(20)STATE_CODE VARCHAR2(2)TIMES_PURCHASED NUMBER(3)
必须将电子表格数据去规范化为关系格式,然后再进行存储。当然,您可以使用 DECODE 编写一个复杂的 SQL*:Loader 或 SQL 脚本,以将数据加载到 CUSTOMERS 表中。或者,您可以使用 pivot 的反向操作 UNPIVOT,将列打乱变为行,这在 Oracle 数据库 11g 中可以实现。
通过一个示例对此进行演示可能更简单。让我们首先使用 pivot 操作创建一个交叉表:
create table cust_matrixasselect * from (select times_purchased as "Puchase Frequency", state_codefrom customers t)pivot(count(state_code)for state_code in ('NY' as "New York",'CT' "Conn",'NJ' "New Jersey",'FL' "Florida",'MO' as "Missouri"))order by 1您可以查看数据在表中的存储方式:
SQL> select * from cust_matrix2 /Puchase Frequency New York Conn New Jersey Florida Missouri ----------------- ---------- ---------- ---------- ---------- ----------1 33048 165 0 0 02 33151 179 0 0 03 32978 173 0 0 04 33109 173 0 1 0 ... and so on ...
这是数据在电子表格中的存储方式:每个州是表中的一个列(“New York”、“Conn”等等)。
SQL> desc cust_matrixName Null? Type----------------------------------------- -------- ---------------------------Puchase Frequency NUMBER(3)New York NUMBERConn NUMBERNew Jersey NUMBERFlorida NUMBERMissouri NUMBER
您需要将该表打乱,使行仅显示州代码和该州的购物人数。通过 unpivot 操作可以达到此目的,如下所示:
select *from cust_matrix
unpivot
(state_countsfor state_code in ("New York","Conn","New Jersey","Florida","Missouri")
)
order by "Puchase Frequency", state_code
输出如下:
Puchase Frequency STATE_CODE STATE_COUNTS ----------------- ---------- ------------1 Conn 1651 Florida 01 Missouri 01 New Jersey 01 New York 330482 Conn 1792 Florida 02 Missouri 0 ... and so on ...
注意每个列名如何变为 STATE_CODE 列中的一个值。Oracle 如何知道 state_code 是一个列名?它是通过查询中的子句知道的,如下所示:
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
这里,您指定“New York”、“Conn”等值是您要对其执行 unpivot 操作的 state_code 新列的值。我们来看看部分原始数据:
Puchase Frequency New York Conn New Jersey Florida Missouri ----------------- ---------- ---------- ---------- ---------- ----------1 33048 165 0 0 0
当列“纽约”突然变为一个行中的值时,您会怎样显示值 33048 呢?该值应该显示在哪一列下呢?上述查询中 unpivot 操作符内的 for 子句上面的子句对此进行了解答。您指定了 state_counts,它就是在生成的输出中创建的新列的名称。
Unpivot 可以是 pivot 的反向操作,但不要以为前者可以对后者所进行的任何操作进行反向操作。例如,在上述示例中,您对 CUSTOMERS 表使用 pivot 操作创建了一个新表 CUST_MATRIX。然后,您对 CUST_MATRIX 表使用了 unpivot,但这并没有取回原始表 CUSTOMERS 的详细信息。相反,交叉表报表以便于您将数据加载到关系表中的不同方式显示。因此 unpivot 并不是为了取消pivot 所进行的操作。在使用 pivot 创建一个表然后删除原始表之前,您应该慎重考虑。
unpivot 的某些很有趣的用法超出了通常的强大数据操作功能范围(如上面的示例)。Amis Technologies 的 Oracle ACE 总监 Lucas Jellema 介绍了如何生成若干行特定数据用于测试。在此,我将对他的原始代码稍加修改,以显示英语字母表中的元音:
select value
from
((select'a' v1,'e' v2,'i' v3,'o' v4,'u' v5from dual)unpivot(valuefor value_type in(v1,v2,v3,v4,v5))
)
输出如下:
V - a e i o u
该模型可以扩展为包含任何类型的行生成器。感谢 Lucas 为我们提供了这一巧妙招术。
XML 类型
在上述示例中,注意您指定有效的 state_codes 的方式:
for state_code in ('NY','CT','NJ','FL','MO')
该要求假设您知道 state_code 列中显示的值。如果您不知道都有哪些值,您怎么构建查询呢?
pivot 操作中的另一个子句 XML 可用于解决此问题。该子句允许您以 XML 格式创建执行了 pivot 操作的输出,在此输出中,您可以指定一个特殊的子句 ANY 而非文字值。示例如下:
select * from (select times_purchased as "Purchase Frequency", state_codefrom customers t
)pivot xml
(count(state_code)for state_code in (any)
)
order by 1
输出恢复为 CLOB 以确保 LONGSIZE 在查询运行之前设置为大值。
SQL> set long 99999
较之原始的 pivot 操作,该查询有两处明显不同(用粗体显示)。首先,您指定了一个子句 pivot xml 而不只是 pivot。该子句生成 XML 格式的输出。其次,for 子句显示 for state_code in (any) 而非长列表的 state_code 值。该 XML 表示法允许您使用 ANY 关键字,您不必输入 state_code 值。输出如下:
Purchase Frequency STATE_CODE_XML ------------------ --------------------------------------------------1 <PivotSet><item><column name = "STATE_CODE">CT</column><column name = "COUNT(STATE_CODE)">165</column></item><item><column name = "STATE_CODE">NY</column><column name = "COUNT(STATE_CODE)">33048</column></item></PivotSet>2 <PivotSet><item><column name = "STATE_CODE">CT</column><column name = "COUNT(STATE_CODE)">179</column></item><item><column name = "STATE_CODE">NY</column><column name = "COUNT(STATE_CODE)">33151</column></item></PivotSet>... and so on ...
如您所见,列 STATE_CODE_XML 是 XMLTYPE,其中根元素是 <PivotSet>。每个值以名称-值元素对的形式表示。您可以使用任何 XML 分析器中的输出生成更有用的输出。
除了 ANY 子句外,您还可以编写一个子查询。假设您有一个优先州列表并希望仅选择这些州的行。您将优先州放在一个名为 preferred_states 的新表中:
SQL> create table preferred_states2 (3 state_code varchar2(2)4 )5 /Table created.SQL> insert into preferred_states values ('FL')2> /1 row created.SQL> commit;Commit complete.
现在 pivot 操作如下所示:
select * from (select times_purchased as "Puchase Frequency", state_codefrom customers t ) pivot xml (count(state_code)for state_code in (select state_code from preferred_states) ) order by 1 /
for 子句中的子查询可以是您需要的任何内容。例如,如果希望选择所有记录而不限于任何优先州,您可以使用以下内容作为 for 子句:
for state_code in (select distinct state_code from customers)
子查询必须返回不同的值,否则查询将失败。这就是我们指定上述 DISTINCT 子句的原因。
结论
Pivot 为 SQL 语言增添了一个非常重要且实用的功能。您可以使用 pivot 函数针对任何关系表创建一个交叉表报表,而不必编写包含大量 decode 函数的令人费解的、不直观的代码。同样,您可以使用 unpivot 操作转换任何交叉表报表,以常规关系表的形式对其进行存储。 Pivot 可以生成常规文本或 XML 格式的输出。如果是 XML 格式的输出,您不必指定 pivot 操作需要搜索的值域。
有关 pivot 和 unpivot 操作的详细信息,请参考 Oracle 数据库 11g SQL 语言参考 。
这篇关于(转载)Oracle关于pivot与unpivot用法介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






