本文主要是介绍SCC,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注:大部分参见百度百科。
在有向图G中,如果两个顶点vi,vj间有一条从vi到vj的有向路径,同时还有一条从vj到vi的有向路径,则称两个顶点强连通(strongly connected)。如果有向图G的每两个顶点都强连通,称G是一个强连通图。非强连通图有向图的极大强连通子图,称为强连通分量(strongly connected components)。
主要有三个算法。他们基于一个定理
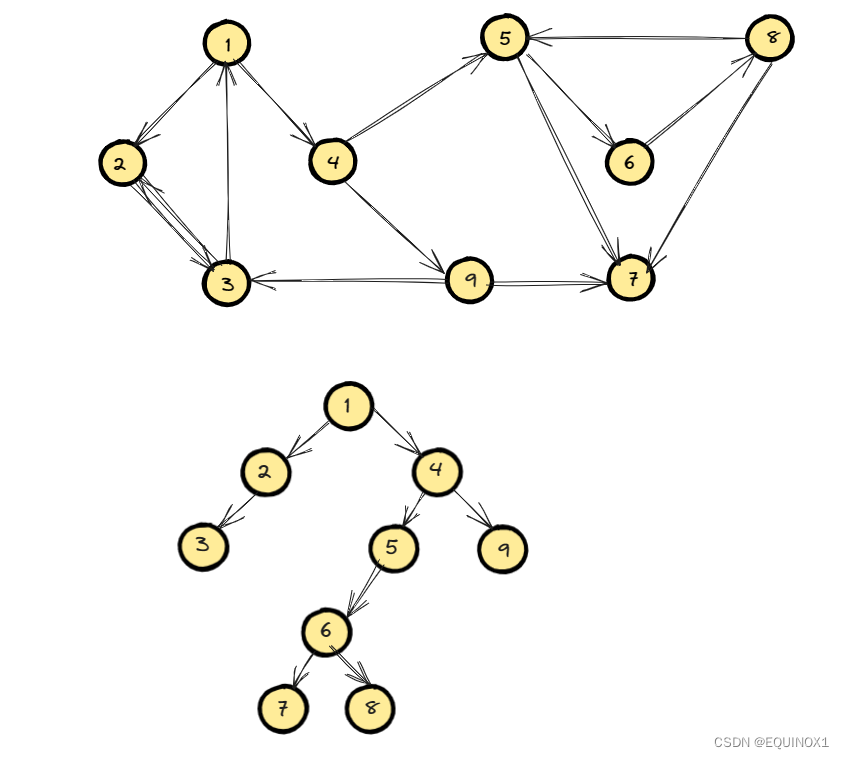
定理:在任何DFS中,同一SCC内的所有顶点均在同一棵深度优先树中。
该定理说明了强连通分量一定是有向图的某个深搜树子树。那么要找到一个分量,只要找到树根( 连接不同分量的桥的前端顶点) ,然后取出其所属分量的顶点即可。
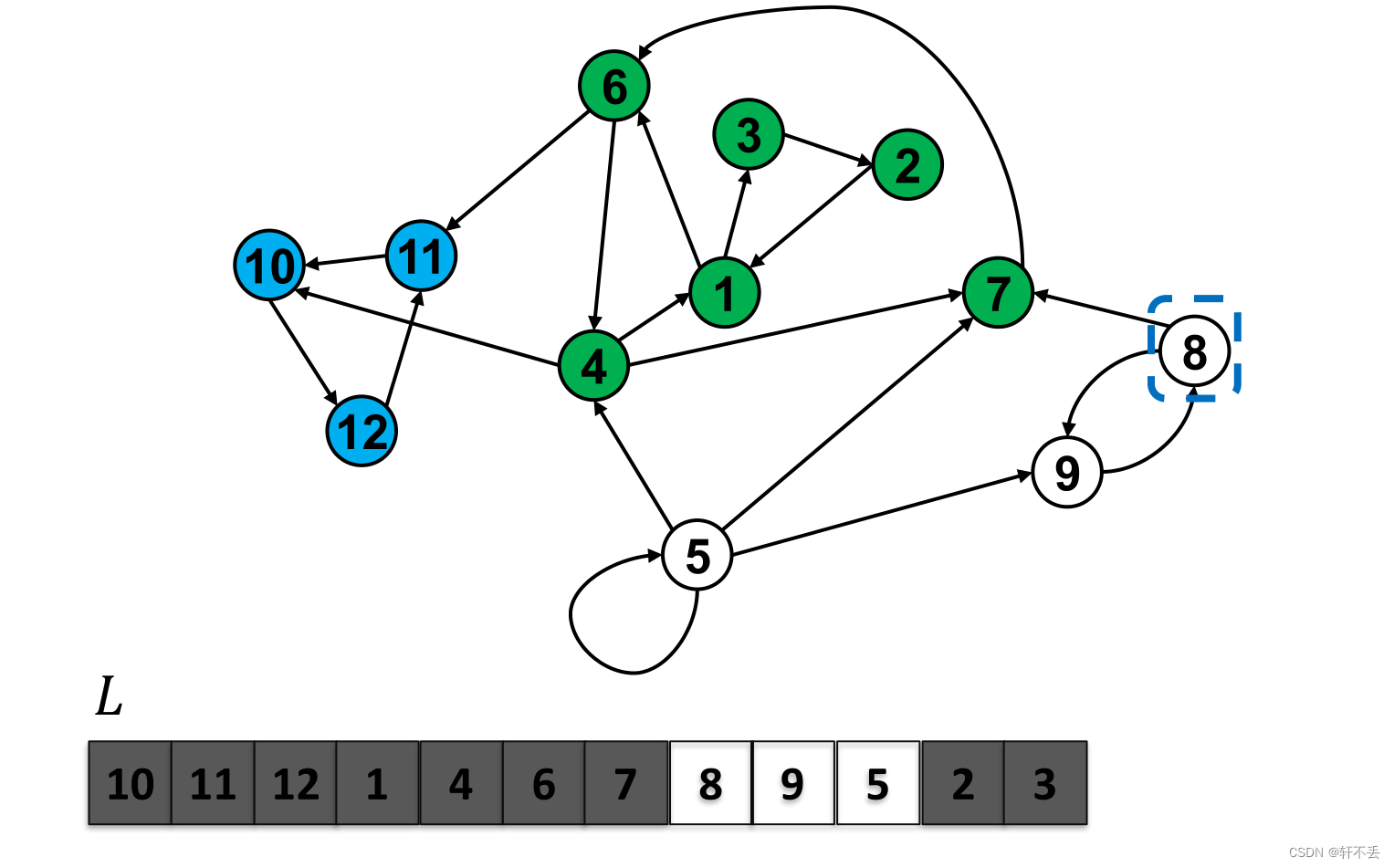
1. Kosaraju算法(也就是clrs中的算法) //时间代价O(E+V)
step1:对原图G进行深度优先遍历,记录每个节点的离开时间。
step2:选择具有最晚离开时间的顶点,对反图GT进行遍历,删除能够遍历到的顶点,这些顶点构成一个强连通分量。
step3:如果还有顶点没有删除,继续step2,否则算法结束。
2. Tarjan算法:DFS+堆+标记 //时间代价O(E+V)
根据白色路径引理,Tarjan确实能在线性时间内完成任务。
stack s;
graph G;
int dex;
tarjan(结点 u){
low(u) = dfu[u] = ++dex; //dfu[i]为节点i搜索的次序编号,low[i]为i或i的子树能够追溯到的最早的栈中节点的次序编号
u入栈;
for (每一个 结点u 能到达的 结点v){
if( 没有被搜到){
tarjan(v);
low[u] = min(low[u],low[v]);
}
else
low[u] = min(low[u],dfu[v]);
}
if (low[u] == dfu[u]) //当dfu(i)=low(i)时,以i为根的搜索子树上所有节点是一个强连通分量。
出栈直到元素为u; //标记层数cnt,记录i所属连通分支SCC[i]均在这里操作
}
其一个实现参考博文《Poj-2186“Popular Cows” && poj2553"The Bottom of A Graph"》
3. Gabow算法:DFS+堆+堆 //时间代价O(E+V)
这个算法其实就是Tarjan算法的变异体,我们观察一下,只是它用第二个堆栈来辅助求出强连通分量的根,而不是Tarjan算法里面的 dfu[ ] 和 low[ ] 数组。那么,我们说一下如何使用第二个堆栈来辅助求出强连通分量的根。
我们使用类比方法,在Tarjan算法中,每次low[i]的修改都是由于环的出现(不然,low[i]的值不可能变小),每次出现环,在这个环里面只剩下一个low[i]没有被改变(深度最低的那个),或者全部被改变,因为那个深度最低的节点在另一个环内。那么Gabow算法中的第二堆栈变化就是删除构成环的节点,只剩深度最低的节点,或者全部删除,这个过程是通过出栈来实现,因为深度最低的那个顶点一定比前面的先访问,那么只要出栈一直到栈顶那个顶点的访问时间不大于深度最低的那个顶点。其中每个被弹出的节点属于同一个强连通分量。那有人会问:为什么弹出的都是同一个强连通分量?因为在这个节点访问之前,能够构成强连通分量的那些节点已经被弹出了,那么Tarjan算法中的判断根我们用什么来代替呢?其实就是看看第二个堆栈的顶元素是不是当前顶点就可以了。
其实Tarjan算法和Gabow算法其实是同一个思想的不同实现,但是,Gabow算法更精妙,时间更少(不用频繁更新low[ ])。
step1: 找一个没有被访问过的节点v,goto step2(v)。否则,算法结束。
step2(v):
将v压入堆栈stk1[]和stk2[]
对于v所有的邻接顶点u:
1) 如果没有访问过,则step2(u)
2) 如果访问过,但没有删除,维护stk2[](处理环的过程)
如果stk2[]的顶元素==v,那么输出相应的强连通分量
4. 总结:
Kosaraju算法的第二次深搜隐藏了一个拓扑性质,而Tarjan算法和Gabow算法省略了第二次深搜,所以,它们不具有拓扑性质。Tarjan算法用堆栈和标记,Gabow用两个堆栈(其中一个堆栈的实质是代替了Tarjan算法的标记部分)来代替Kosaraju算法的第二次深搜,所以只用一次深搜,效率比Kosaraju算法要高。
这篇关于SCC的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!