本文主要是介绍纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目火了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
众所周知,大语言模型还在快速发展,应该有很多可以优化的地方。我用纯 C 语言来写,是不是能优化一大截?
也许很多人开过这样的脑洞,现在有大佬实现了。
今天凌晨,前特斯拉 Autopilot 负责人、OpenAI 科学家 Andrej Karpathy 发布了一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」。
GitHub 链接:https://github.com/karpathy/llm.c
消息一出,立即引发了机器学习社区的热烈讨论,项目的 Star 量不到七个小时就冲上了 2000。有网友表示,大佬从零开始用 C 语言写大模型只为好玩,我等只能膜拜:
纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目火了© 由 ZAKER科技 提供
llm.c 旨在让大模型(LM)训练变得简单 —— 使用纯 C 语言 / CUDA,不需要 245MB 的 PyTorch 或 107MB 的 cPython。例如,训练 GPT-2(CPU、fp32)仅需要单个文件中的大约 1000 行干净代码(clean code),可以立即编译运行,并且完全可以媲美 PyTorch 参考实现。
Karpathy 表示,选择从 GPT-2 开始,是因为它是 LLM 的鼻祖,是大语言模型体系首次以现代形式组合在一起,并且有可用的模型权重。
原始训练的实现在这里:https://github.com/karpathy/llm.c/blob/master/train_gpt2.c
你会看到,项目在开始时一次性分配所有所需的内存,这些内存是一大块 1D 内存。然后在训练过程中,不会创建或销毁任何内存,因此内存占用量保持不变,并且只是动态的,将数据批次流过。这里的关键在于手动实现所有单个层的前向和后向传递,然后将它们串联在一起。
纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目火了© 由 ZAKER科技 提供
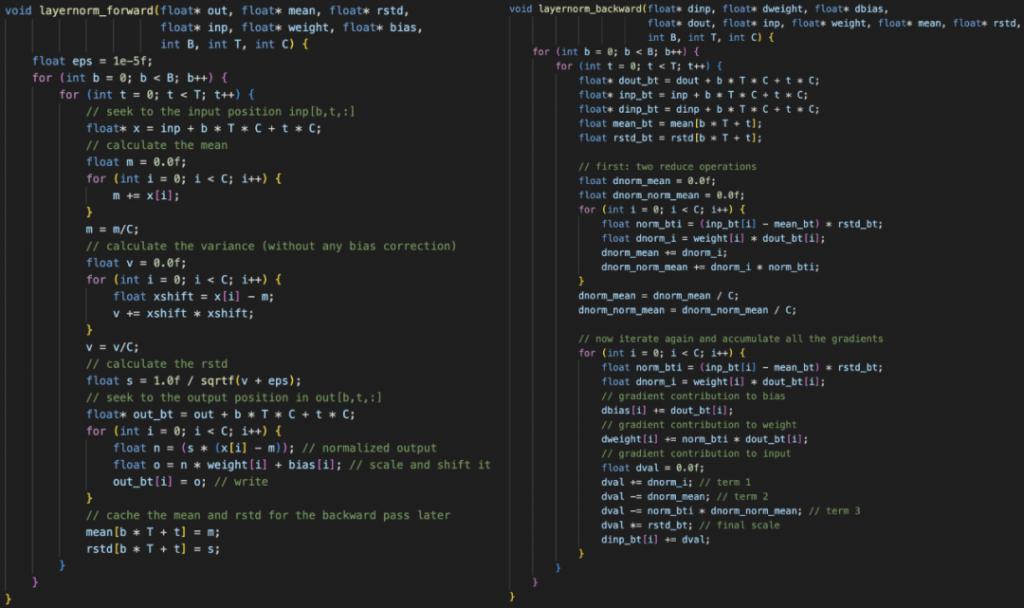
例如,这里是 layernorm 前向和后向传递。除了 layernorm 之外,我们还需要编码器、matmul、自注意力、gelu、残差、softmax 和交叉熵损失。
「一旦你拥有了所有的层,接下来的工作只是将它们串在一起。讲道理,写起来相当乏味和自虐,因为你必须确保所有指针和张量偏移都正确排列, 」Karpathy 评论道。
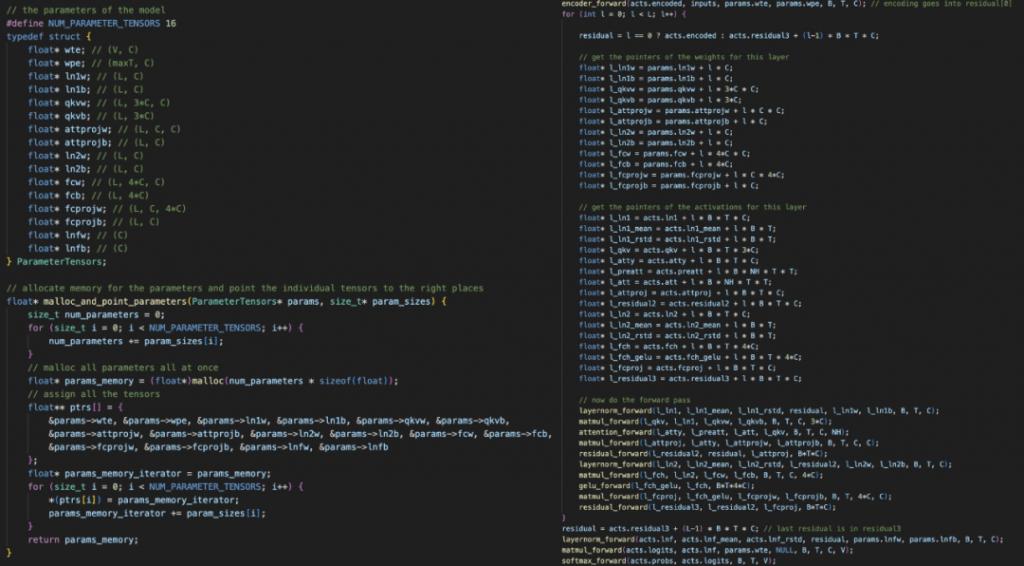
纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目火了© 由 ZAKER科技 提供
左:我们分配一个 1D 内存数组,然后将所有模型权重和激活指向它。右:我们需要非常非常小心地进行所有指针运算。
一旦你有了前向 / 后向,其余部分(数据加载器、Adam 更新等)大多就不足为惧了。
不过,真正的乐趣现在才开始:Karpathy 表示,他现在正在逐层将其移植到 CUDA 上,以便提高效率,甚至期待能在 PyTorch 的合理范围内,但没有任何严重的依赖关系 —— 现在工作已经完成了几层。所以这是一个非常有趣的 CUDA 练习。
对此,有网友表示:即使顶着指针 ptsd,我也能感受到这些代码的美。
纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目火了© 由 ZAKER科技 提供
也有人说,这项目简直就是完美的机器学习工程师在线面试答案。
从这开始,未来该项目的延伸会包括将精度从 fp32 降低到 fp16 / 以下,以及增加几个层(例如 RoPE)以支持更现代的架构,如 llama 2/mistral/gemma/ 等模型。
最后,Andrej Karpathy 表示,一旦项目稳定起来,就会出关于从头开始用 C 语言写大模型的视频。
llm.c 下一步的目标包括:
直接的 CUDA 实现,让速度更快,并且可能接近 PyTorch;
使用 SIMD 指令、x86 上的 AVX2 / ARM 上的 NEON(例如苹果 M 系列芯片的电脑)来加速 CPU 版本;
更多新型架构,例如 Llama2、Gemma 等。
看起来,想让速度更快的目的没有达到,这里不得不佩服 PyTorch 如今的效率。对于存储库,作者希望维护干净、简单的参考实现,以及可以接近 PyTorch 的更优化版本,但代码和依赖项只占一小部分。
使用方法
要使用 llm.c,首先要下载并 tokenize 数据集。tinyshakespeare 数据集的下载和 tokenize 速度最快:
输出:
.bin 文件是 int32 数字的原始字节流,使用 GPT-2 tokenizer 标记 token ID,或者也可以使用 prepro_tinystories.py tokenize TinyStories 数据集。
原则上,llm.c 到这一步已经可以训练模型。然而,基线 CPU/fp32 参考代码的效率很低,从头开始训练这些模型不切实际。因此,这里使用 OpenAI 发布的 GPT-2 权重进行初始化,然后再进行微调,所以必须下载 GPT-2 权重并将它们保存为可以在 C 中加载的检查点:
该脚本将下载 GPT-2 ( 124M ) 模型,对单批数据进行 10 次迭代的过拟合,运行几个生成步骤,最重要的是,它将保存两个文件:
gpt2_124M.bin 文件,包含在 C 语言中加载模型所需的权重;
gpt2_124M_debug_state.bin 文件,包含更多调试状态:输入、目标、logits 和损失。这对于调试 C 语言代码、单元测试以及确保 llm.c 与 PyTorch 参考实现完全可媲美非常重要。
现在,使用 gpt2_124M.bin 中的模型权重进行初始化并使用纯 C 语言进行训练,首先编译代码:
这里可以查看 Makefile 及其注释。它将尝试自动检测 OpenMP 在当前系统上是否可用,这对于以极低的代码复杂性成本加速代码非常有帮助。编译 train_gpt2 后,运行:
这里应该根据 CPU 的核心数量来调整线程数量。该程序将加载模型权重、token,并使用 Adam 运行几次迭代的微调 loop,然后从模型生成样本。在 MacBook Pro ( Apple Silicon M3 Max ) 上,输出如下所示:
但这一步生成的只是 token ID,还需要将其解码回文本。这一点可以很容易地用 C 语言实现,因为解码非常简单,可以使用 tiktoken:
输出:
值得注意的是,这里没有尝试调整微调超参数,因此很可能还有大幅改进的空间,特别是在训练时间更长的情况下。
附上一个简单的单元测试,以确保 C 代码与 PyTorch 代码一致。编译并运行:
这里加载 gpt2_124M_debug_state.bin 文件,运行前向传递,将 logits 和损失与 PyTorch 参考实现进行比较,然后使用 Adam 进行 10 次迭代训练,确保损失可与 PyTorch 参考实现媲美。

纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目火了© 由 ZAKER科技 提供
最后,Karpathy 还附上了一个简单的教程。这是一个简单的分步指南,用于实现 GPT-2 模型的单层(layernorm 层),可以帮助你理解如何用 C 语言实现语言模型。
教程地址:doc/layernorm/layernorm.md
我们知道,最近 Andrej Karpathy 沉迷于制作教程。去年 11 月,他录制的《大语言模型入门》在 YouTube 上吸引了很多人观看。
纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目火了© 由 ZAKER科技 提供
这次新项目的配套视频什么时候出?我们都很期待。
参考内容:
机器之心 AI 技术论坛「视频生成技术与应用 — Sora 时代」,将于 4.13 在北京海淀举办。
论坛聚焦于 Sora、视频生成技术、多模态大模型等前沿领域的技术突破和应用实践,助力企业和从业者紧跟技术发展潮流、掌握最新技术进展与技术突破。
这篇关于纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目火了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







