本文主要是介绍DataWhale集成学习【中】:(一)投票法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 这篇博文是 DataWhale集成学习【中】 的第一部分,主要是介绍投票法
- 参考资料为DataWhale开源项目:机器学习集成学习与模型融合(基于python)和scikit-learn官网
- 学习交流欢迎联系 obito0401@163.com
文章目录
- 原理
- 案例
原理
- 投票法是集成学习中的常用方法,通过集成多个模型,可以提高模型的泛化能力,减少错误率
- 其思路在于一个假定,即一般情况下,错误总是较小概率发生,次数较少,而大多数情况下都是正确的,借助少数服从多数的投票思路,可以很好地提升决策的正确性
- 投票法在回归模型和分类模型上均可使用
- 回归投票法:预测结果是所有集成模型中预测结果的平均值
- 分类投票法:预测结果是所有集成模型中出现最多的预测结果
- 硬投票:预测结果是所有投票结果中出现最多的类
- 软投票:预测结果是所有投票结果中概率加和最大的类
- 在投票法中,还要考虑到基模型的影响。通常来说,要想产生更好的效果,有两点需要注意:
- 基模型之间效果不能相差过大:当某个模型效果过差时,该模型可能会成为噪声,影响整体模型的准确度
- 基模型之间应该有较小的同质性:在基模型预测结果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型的投票
- 投票法的局限性在于:它对所有模型的处理是一致的,也就是说所有模型对预测的贡献程度是相同的,而在模型性能有较大差异时,加权才是比较合适的方法,这是需要注意的地方
案例
- Python 的 sklearn 库中提供了
VotingRegressor和VotingClassifier两种投票方法 - 该两种投票方法的操作相同,并采用相同的参数
- 使用该方法需要提供一个模型列表,列表中每个模型采用
tuple的形式:第一个元素代表模型名称,第二个元素代表模型方法,每个模型方法的模型名称唯一
# 创建一个1000个样本,20个特征的随机数据集
from sklearn.datasets import make_classificationdef get_dataset():X,y = make_classification(n_samples=1000,n_features=20,n_informative=15,n_redundant=5,random_state=3)return X,y# 采用多个KNN为基模型演示投票法,每个KNN采用不同的K值
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import VotingClassifier
def get_voting():models = []models.append(('KNN1',KNeighborsClassifier(n_neighbors=1)))models.append(('KNN3',KNeighborsClassifier(n_neighbors=3)))models.append(('KNN5',KNeighborsClassifier(n_neighbors=5)))models.append(('KNN7',KNeighborsClassifier(n_neighbors=7)))models.append(('KNN9',KNeighborsClassifier(n_neighbors=9)))ensemble = VotingClassifier(estimators=models,voting="hard") # 硬投票return ensemble# 创建模型列表来评估投票带来的提升
def get_models():models = dict()models['knn1'] = KNeighborsClassifier(n_neighbors=1)models['knn3'] = KNeighborsClassifier(n_neighbors=3)models['knn5'] = KNeighborsClassifier(n_neighbors=5)models['knn7'] = KNeighborsClassifier(n_neighbors=7)models['knn9'] = KNeighborsClassifier(n_neighbors=9)models['hard-voting'] = get_voting()return models# 创建函数接收模型实例,并以分层10倍交叉验证三次重复的分数列表形式返回
from sklearn.model_selection import RepeatedStratifiedKFold,cross_val_score
def evaluate_model(model,X,y):cv = RepeatedStratifiedKFold(n_splits=10,n_repeats=3,random_state=1)scores = cross_val_score(model,X,y,scoring="accuracy",cv=cv,n_jobs=-1,error_score="raise")return scores# 报告每个算法的平均性能,并可视化展示
from numpy import mean,std
from matplotlib import pyplotX,y = get_dataset()
models = get_models()
results,names = [],[]
for name,model in models.items():scores = evaluate_model(model,X,y)results.append(scores)names.append(name)print(">%s %.3f (%.3f)" % (name,mean(scores),std(scores)))pyplot.boxplot(results,labels=names,showmeans=True)
pyplot.show()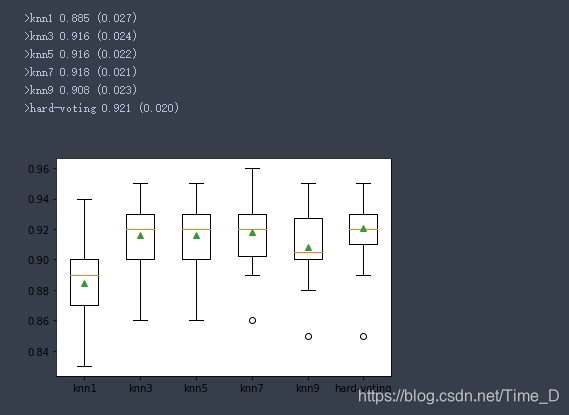
这篇关于DataWhale集成学习【中】:(一)投票法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







