本文主要是介绍[尚硅谷flink] 水位线,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在事件时间语义窗口下,标记当前时间之前的数据全部到达的一个逻辑标记时间戳。
文章目录
- 7.1 生成水位线的总体原则
- 7.2 水位线生成策略
- 7.3 flink 的内置水位线
- 有序流
- 乱序流
- 7.4 水位线的传递
- 7.5 迟到数据的处理
7.1 生成水位线的总体原则
完美的水位线是“绝对正确”的,也就是一个水位线一旦出现,就表示这个时间之前的数据已经全部到齐、之后再也不会出现了。不过如果要保证绝对正确,就必须等足够长的时间,这会带来更高的延迟。
如果我们希望处理得更快、实时性更强,那么可以将水位线延迟设得低一些。这种情况下,可能很多迟到数据会在水位线之后才到达,就会导致窗口遗漏数据,计算结果不准确。
当然,如果我们对准确性完全不考虑、一味地追求处理速度,可以直接使用处理时间语义,
这在理论上可以得到最低的延迟。
所以 Flink 中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把控制的权力交给了程序员,我们可以在代码中定义水位线的生成策略。
7.2 水位线生成策略
在Flink的DataStream API中,有一个单独用于生成水位线的方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间。具体使用如下:
DataStream<Event> stream = env.addSource(new ClickSource());DataStream<Event> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(<watermark strategy>);
说明:WatermarkStrategy作为参数,这就是所谓的“水位线生成策略”。WatermarkStrategy是一个接口,该接口中包含了一个“时间戳分配器”TimestampAssigner和一个“水位线生成器”WatermarkGenerator。
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>,WatermarkGeneratorSupplier<T>{// 负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础。@OverrideTimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);// 主要负责按照既定的方式,基于时间戳生成水位线@OverrideWatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
7.3 flink 的内置水位线
有序流
对于有序流,主要特点就是时间戳单调增长,所以永远不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景,直接调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。
package org.example.watermark;import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.example.bean.WaterSensor;
import org.example.utils.WaterSensorMapFunction;public class WatermarkMonoDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("localhost", 7777).map(new WaterSensorMapFunction());// TODO 1.定义Watermark策略WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy// 1.1 指定watermark生成:升序的watermark,没有等待时间.<WaterSensor>forMonotonousTimestamps()// 1.2 指定 时间戳分配器,从数据中提取.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor element, long recordTimestamp) {// 返回的时间戳,要 毫秒System.out.println("数据=" + element + ",recordTs=" + recordTimestamp);return element.getTs() * 1000L;}});// TODO 2. 指定 watermark策略SingleOutputStreamOperator<WaterSensor> sensorDSwithWatermark = sensorDS.assignTimestampsAndWatermarks(watermarkStrategy);sensorDSwithWatermark.keyBy(sensor -> sensor.getId())// TODO 3.使用 事件时间语义 的窗口.window(TumblingEventTimeWindows.of(Time.seconds(10))).process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {long startTs = context.window().getStart();long endTs = context.window().getEnd();String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}}).print();env.execute();}}输入
➜ ~ nc -lk 7777
s1,1,1
s2,2,2
s3,3,3
s4,4,4
s5,10,10
s6,12,12
s7,13,13
s9,19,19
s10,20,20
s11,1,1
s12,10,10
s13,30,30
输出
数据=WaterSensor{id='s1', ts=1, vc=1},recordTs=-9223372036854775808
数据=WaterSensor{id='s2', ts=2, vc=2},recordTs=-9223372036854775808
数据=WaterSensor{id='s3', ts=3, vc=3},recordTs=-9223372036854775808
数据=WaterSensor{id='s4', ts=4, vc=4},recordTs=-9223372036854775808
数据=WaterSensor{id='s5', ts=10, vc=10},recordTs=-9223372036854775808
key=s1的窗口[1970-01-01 08:00:00.000,1970-01-01 08:00:10.000)包含1条数据===>[WaterSensor{id='s1', ts=1, vc=1}]
key=s2的窗口[1970-01-01 08:00:00.000,1970-01-01 08:00:10.000)包含1条数据===>[WaterSensor{id='s2', ts=2, vc=2}]
key=s4的窗口[1970-01-01 08:00:00.000,1970-01-01 08:00:10.000)包含1条数据===>[WaterSensor{id='s4', ts=4, vc=4}]
key=s3的窗口[1970-01-01 08:00:00.000,1970-01-01 08:00:10.000)包含1条数据===>[WaterSensor{id='s3', ts=3, vc=3}]
数据=WaterSensor{id='s6', ts=12, vc=12},recordTs=-9223372036854775808
数据=WaterSensor{id='s7', ts=13, vc=13},recordTs=-9223372036854775808
数据=WaterSensor{id='s9', ts=19, vc=19},recordTs=-9223372036854775808
数据=WaterSensor{id='s10', ts=20, vc=20},recordTs=-9223372036854775808
key=s5的窗口[1970-01-01 08:00:10.000,1970-01-01 08:00:20.000)包含1条数据===>[WaterSensor{id='s5', ts=10, vc=10}]
key=s6的窗口[1970-01-01 08:00:10.000,1970-01-01 08:00:20.000)包含1条数据===>[WaterSensor{id='s6', ts=12, vc=12}]
key=s9的窗口[1970-01-01 08:00:10.000,1970-01-01 08:00:20.000)包含1条数据===>[WaterSensor{id='s9', ts=19, vc=19}]
key=s7的窗口[1970-01-01 08:00:10.000,1970-01-01 08:00:20.000)包含1条数据===>[WaterSensor{id='s7', ts=13, vc=13}]
数据=WaterSensor{id='s11', ts=1, vc=1},recordTs=-9223372036854775808
数据=WaterSensor{id='s12', ts=10, vc=10},recordTs=-9223372036854775808
数据=WaterSensor{id='s13', ts=30, vc=30},recordTs=-9223372036854775808
key=s10的窗口[1970-01-01 08:00:20.000,1970-01-01 08:00:30.000)包含1条数据===>[WaterSensor{id='s10', ts=20, vc=20}]
key=s13的窗口[1970-01-01 08:00:30.000,1970-01-01 08:00:40.000)包含1条数据===>[WaterSensor{id='s13', ts=30, vc=30}]注意过了水位线后面到达的数据,由于事件窗口已关闭,数据将由于延迟到达而丢失。
乱序流
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用WatermarkStrategy. forBoundedOutOfOrderness()方法就可以实现。这个方法需要传入一个maxOutOfOrderness参数,表示“最大乱序程度”,它表示数据流中乱序数据时间戳的最大差值;如果我们能确定乱序程度,那么设置对应时间长度的延迟,就可以等到所有的乱序数据了。
package org.example.watermark;import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.example.bean.WaterSensor;
import org.example.utils.WaterSensorMapFunction;import java.time.Duration;public class WatermarkOutOfOrdernessDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("localhost", 7777).map(new WaterSensorMapFunction());// TODO 1.定义Watermark策略WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy// 1.1 指定watermark生成:乱序的,等待3s.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))// 1.2 指定 时间戳分配器,从数据中提取.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor element, long recordTimestamp) {// 返回的时间戳,要 毫秒System.out.println("数据=" + element + ",recordTs=" + recordTimestamp);return element.getTs() * 1000L;}});// TODO 2. 指定 watermark策略SingleOutputStreamOperator<WaterSensor> sensorDSwithWatermark = sensorDS.assignTimestampsAndWatermarks(watermarkStrategy);sensorDSwithWatermark.keyBy(sensor -> sensor.getId())// TODO 3.使用 事件时间语义 的窗口.window(TumblingEventTimeWindows.of(Time.seconds(10))).process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {long startTs = context.window().getStart();long endTs = context.window().getEnd();String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}}).print();env.execute();}}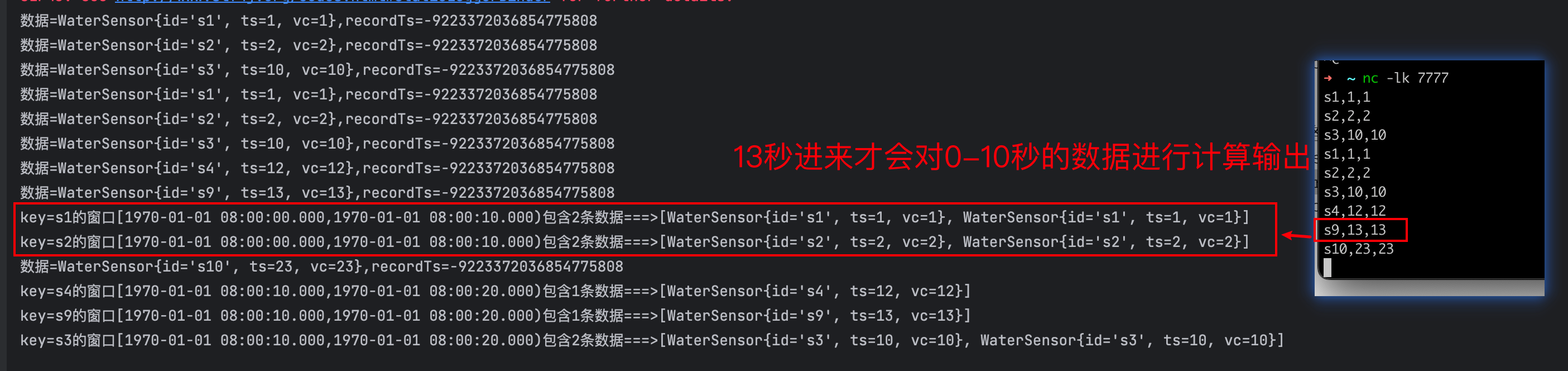
7.4 水位线的传递
- 接收到上游多个取最小
- 往下游进行广播发送
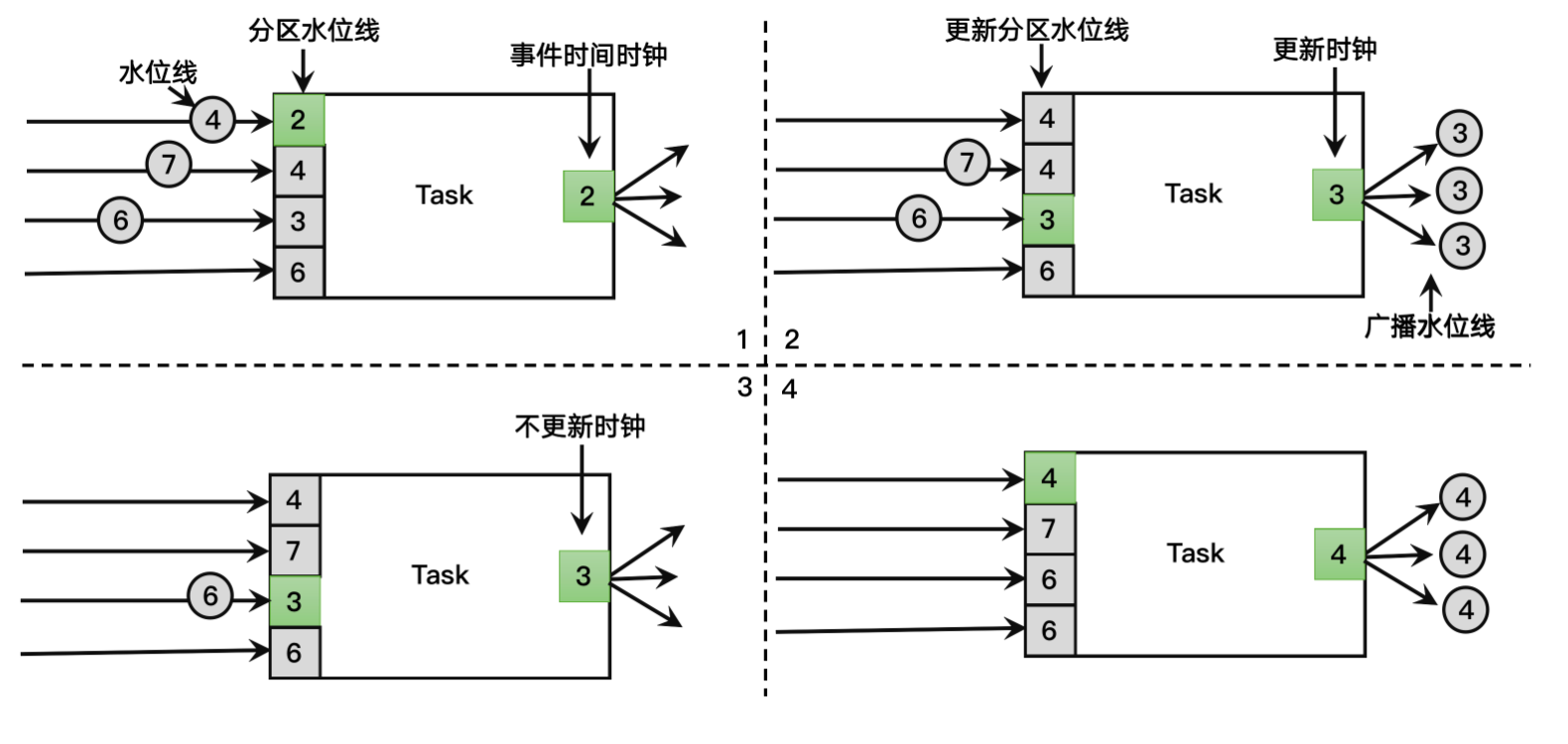
在多个上游并行任务中,如果有其中一个没有数据,由于当前Task是以最小的那个作为当前任务的事件时钟,就会导致当前Task的水位线无法推进,就可能导致窗口无法触发。这时候可以设置空闲等待。
// 自定义分区器:数据%分区数,只输入奇数,都只会去往map的一个子任务SingleOutputStreamOperator<Integer> socketDS = env.socketTextStream("hadoop102", 7777)// 自定义分区.partitionCustom(new MyPartitioner(), r -> r).map(r -> Integer.parseInt(r)).assignTimestampsAndWatermarks(WatermarkStrategy.<Integer>forMonotonousTimestamps().withTimestampAssigner((r, ts) -> r * 1000L).withIdleness(Duration.ofSeconds(5)) //空闲等待5s);
7.5 迟到数据的处理
- 推迟水印推进
在水印产生时,设置一个乱序容忍度,推迟系统时间的推进,保证窗口计算被延迟执行,为乱序的数据争取更多的时间进入窗口。
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
- 设置窗口延迟关闭
Flink的窗口,也允许迟到数据。当触发了窗口计算后,会先计算当前的结果,但是此时并不会关闭窗口。
以后每来一条迟到数据,就触发一次这条数据所在窗口计算(增量计算)。直到wartermark 超过了窗口结束时间+推迟时间,此时窗口会真正关闭。
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
注意:
允许迟到只能运用在event time上。
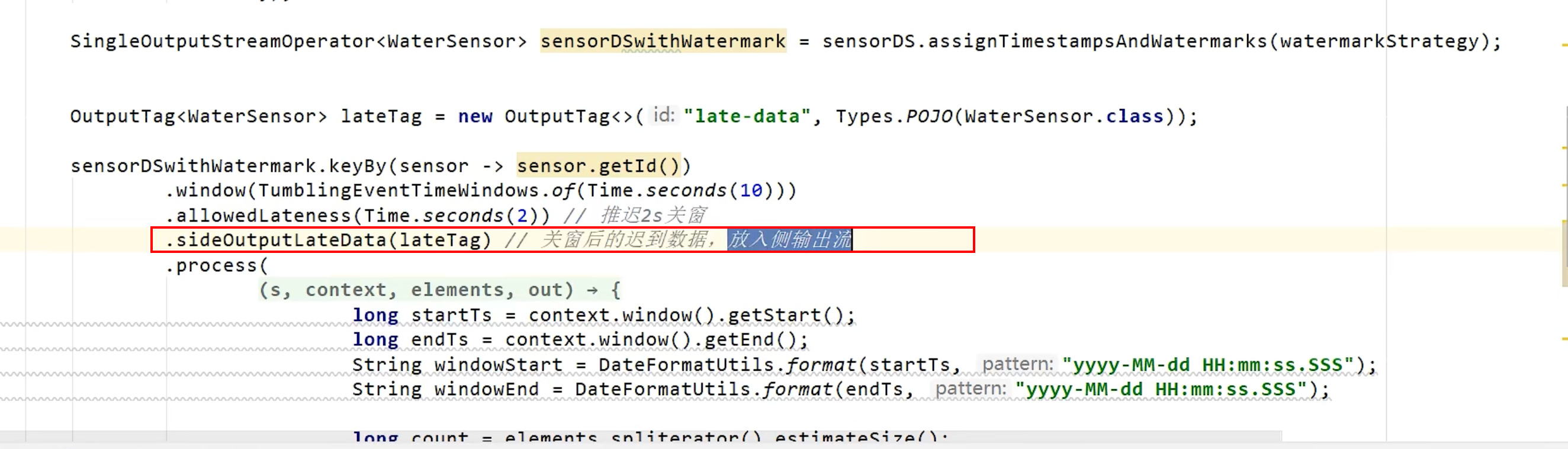
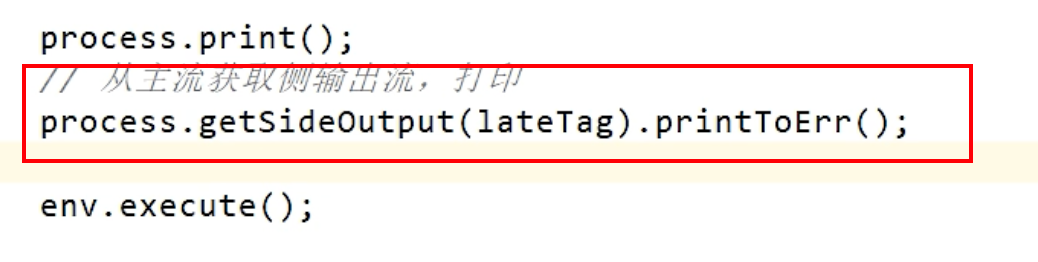
- 使用侧流接收迟到的数据
总结

这篇关于[尚硅谷flink] 水位线的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






