本文主要是介绍clfB-tree: Cacheline Friendly Persistent B-tree for NVRAM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(一)研究目的
The goal of clfB-tree is to minimize the overhead of failure-atomic update on a B-tree.
(二)研究背景
B-tree 是为易失内存和块设备存储设计的,确保对每个磁盘页进行 tri-atomic(never updated,complete,or unreadable) 写操作,对于这样的块设备存储,使用传统的 shadowing 或是 redo logging 来保证 B-tree 的原子性持久化。
NVRAM 通过 memory bus 而不是 PCI 接口进行访问,且其原子性单元不是 4 KBytes 而是 a cache line,所以 NVRAM 上如何以原子方式更新 B-tree nodes ?
(三)研究概述
clfB-tree 内部节点采用 Differential Encoding,叶节点有两种,一种与内部结点一样采用Differential Encoding,另一种采用 wB+Tree 和 NV-Tree 中的 append-only 策略。
显式地使用限制性事务内存(restricted transactional memory,RTM)实现了 failure-atomic cache line write 函数,并隐式地利用了 write combining store buffer。failure-atomic cache line write 函数有助于最小化 cache line flush 的次数,因此只需要一条 cache line flush 指令就可以更新一个树节点。
clfB-tree 中的 Short-Circuit Shadowing 会导致 upward cascading shadowing problem,为解决此问题,使用 In-Place Update 来自动更新 clfB-tree 节点。
(四)关键技术
clfB-tree
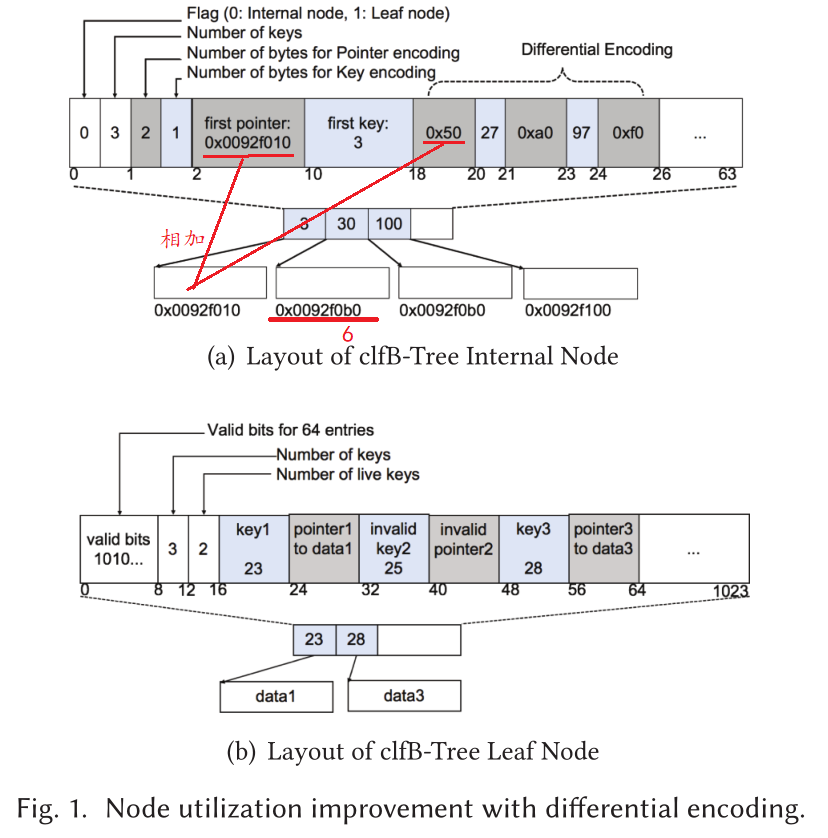
Differential Encoding in Internal Node
clfB-tree 内部节点的布局如图 1(a) 所示,内部节点的大小设置为 cache line 大小(图中为 64 bytes)。第一个字节标记是叶节点还是内部节点,以及节点中有多少键。第二个字节存储用于编码指针和键的字节数。 第三个字节开始存储第一个 8 字节指针和第一个键,对于其余的指针和键,计算与第一个值的差值。最好情况:指针编码和键编码只需要 1 字节,那么 64 字节的树节点最多有 23 个键和 24 个子指针;最坏情况:指针编码和键编码需要8字节,那么 64 字节的树节点最多有 3 个键和 4 个子指针。
Insertion to Leaf Node
clfB-tree 中设计并实现了两种不同的叶子节点。
第一种:与内部节点一样,称之为编码的叶子,缺点是不能容纳大量的 entries。
第二种:采用 wB+Tree 和 NV-Tree 中的 append-only 策略。插入操作将一个新条目追加到第一个可用的空槽中,一旦新的条目通过 cache line flush 和 store fence 指令安全地写回 NVRAM,就自动地将条目在有效性位图数组中的位设置为 1,并调用另一个 cache line flush 和 store fence 指令。对于删除和更新操作,NV-tree 会附加一个负标志使现有的条目无效,这需要像插入操作一样执行两条刷新缓存行指令。但是 wB+tree 和 clfB-tree 只是通过翻转叶节点位图数组中的有效性位来使现有条目无效。这种 append-only 方法减少了缓存行刷新次数。但是这种方法的一个明显的缺点是键是没有排序的,除非树节点有关于排序的额外信息,否则不能使用二叉搜索。因此,wB+tree 管理两个元数据数组,一个用于有效性的位图数组,另一个用于条目排序的槽数组。在树节点中有两个元数据数组的缺点是它需要额外的缓存行刷新。
FAILURE-ATOMIC CACHE LINE UPDATES
通过使用限制事务内存(Restricted Transactional Memory,RTM)可以实现 failure-atomic cache line write operation。RTM 在 Intel Haswell-EX 架构中是可用的。RTM 提供了三个新的指令——XBEGIN、XEND 和 XABORT,它们允许程序员指定事务的开始和结束,并在事务不能成功执行时显式地中止事务。RTM 最初的设计目的是为多线程应用程序提供硬件事务内存支持。然而,如果 RTM 和写组合存储缓冲区一起使用,我们可以实现 failure-atomic cache line write operation 的预期行为。算法1展示了一个 failure-atomic cache line write 函数的实现。


算法 2 展示了使用 atomicCacheLineWrite 能使 clfB-tree 方便地将两个子指针原子地存储在父节点中。为了加强对 clfB-tree 节点的更改的持久性,我们仍然需要调用缓存行刷新和存储栅栏指令,但只调用一次,如图2(a)所示。
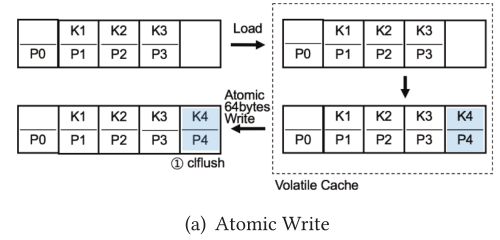
CLFB-TREE UPDATES VIA 8 BYTES ATOMIC WRITES
虽然通过 RTM 和 write combining store buffer 可以实现 failure-atomic cache line write operation,但并不是所有的处理器都支持硬件事务性内存扩展。clfB-tree 使用 shadowing 或 in-place updates 代替 RTM 自动更新树节点。
Short-Circuit Shadowing
Shadowing 是一种 copy-on-write 技术,广泛用于在数据库系统中提供原子性和持久性。Shadowing 复制树节点生成一个副本,然后修改副本,副本持久化则原始节点的父节点通过 8 字节原子写操作更新其指针指向副本。但如果原始节点分裂,则父节点需要同时更新两个指针,这使得 Short-Circuit Shadowing 变得复杂,要自动更新两个指针,需要创建父节点的副本。
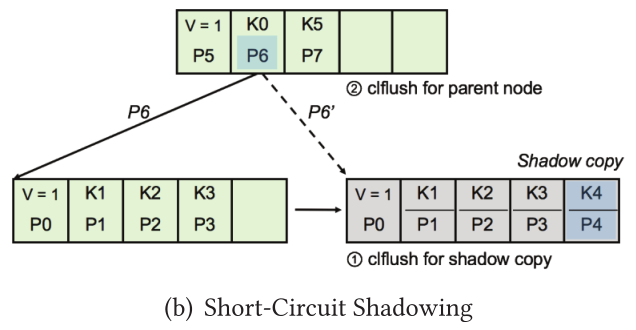
clfB-tree 中的 Short-Circuit Shadowing 需要两个 cache line flush 指令,一个用于 shadow node,一个用于 parent node。shadow node 只需要一个cache line flush 指令的原因是树节点的大小就是 cache line 的大小。
但是 clfB-tree 中的 Short-Circuit Shadowing 会导致 cascading split 问题,因为指向 shadow node 的指针可能比指向原始节点的指针需要更多字节,比如 shadow node 的地址离第一个节点的地址很远,那么 differential encoding 可能需要更多字节,导致父节点中所有指针都必须重新编码并更新整个 cache line。这个问题称为 upward cascading shadowing problem。
In-Place Update
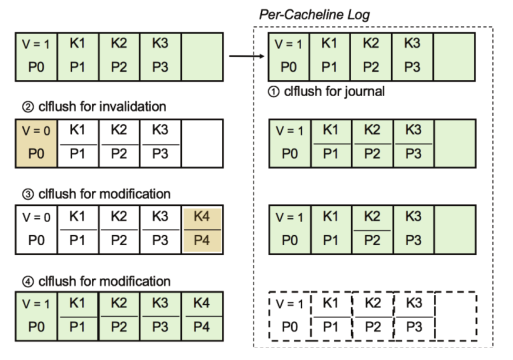
为了解决 upward cascading shadowing problem,使用 In-Place Update 来自动更新 clfB-tree 节点。如算法3所示,In-Place Update 在创建备份副本后对原始树节点进行更改。由于父节点中编码的子节点指针不会更新,除非子节点拆分,否则 In-Place Update 不会出现不必要的 upward cascading shadowing problem,除非叶节点溢出。

然而 In-Place Update 需要 4 次 cache line flushes。
- 首先,当一个新条目存储在树节点时,原始树节点的副本被保存为 per-cacheline log。此副本需要1次 cache line flush。
- 然后,通过将原始节点的有效位设置为 false 来使其无效,这需要另一次 cache line flush。
- 将有效位设置为 false 后,可以通过多次写操作更新原始树节点。如果系统在此步骤中崩溃,那么可以检查树节点的一致性,并通过检查有效位从故障中恢复过来,并使用保存的 per-cacheline log 覆盖原始树节点。在将所有更改写入原始树节点后,另调用一次 cache line flush 来持久化这些更改。
- 最后,验证更新后的原始树节点,需要另一次 cache line flush 来翻转有效位。
write-atomic B+tree (wB+tree)
write-atomic B+tree (wB+tree) 是 NV-tree 的改进版本,两个都通过 append-only updates 来减少 cache line flashes。
wB+tree的节点需要两个元数据:bitmap array 和 slot array。bitmap array 存储有效条目的位置,slot array 存储条目的排序顺序。wB+tree 的节点结构如图3(a)所示。

当一个新条目被插入到 wB+tree 节点时,(i)它首先通过在位图中翻转一个位来使槽位数组失效。此步骤需要 clflush 指令。(ii)下一步,它将新条目存储在第一个可用槽中,这需要另一个 clflush 指令。(iii)用更新后的表项顺序更新槽位数组,这一步需要多条 clflush 指令,因为插槽数组的大小可能大于缓存线的大小。(iv)一旦槽位数组被写回 NVRAM,它会用一个 clflush 指令更新位图数组,以标记新的条目和槽位数是有效的。
更新和删除操作类似于插入操作,可以通过更新槽位数组和位图数组来持久化对树节点的更改。对于槽数组和位图数组,wB±tree 每个事务至少需要4次缓存行刷新。
**wB+tree 的一个变体是 slot-only wB+tree(图3b),它在更新响应时间方面优于 bitmap+slot wB+tree,因为它减少了缓存行刷新的次数。**slot-only wB+tree 限制了wB+tree 节点的最大条目数,也就是说,每个树节点存储的条目不超过7个。通过限制条目的数量,wB+tree可以将位图数组和槽位数组结合起来,因为槽位数组可以容纳8个字节,并且槽位数组可以自动更新。通过消除位图数组,只要节点不拆分,slot-only wB+tree 将每次插入的缓存线刷新次数减少到2次。当一个新条目存储在 slot-only wB+tree 节点时,(i)该条目存储在第一个可用槽中,并调用 clflush 指令。(ii)在新的条目被写入NVRAM之后,插槽数组需要通过另一个 clflush 指令进行更新。
当叶子节点溢出时,wB+tree 依赖于 redo-logging,该重写日志调用至少两个缓存行刷新指令,如图4(a)所示。当叶节点拆分时,wB+tree 将溢出的叶节点的一半条目复制到新的右同级节点,并在其父节点中插入指向新同级节点的指针。注意,对父节点的更新和对溢出节点的槽位数组的更新必须同时自动执行。如果系统在更新原始节点的槽位数组之前崩溃,那么原始树节点和新的右兄弟节点可能有多余的条目。为了解决这个问题,wB+tree 使用了 redo-logging,这需要额外的缓存行刷新操作。
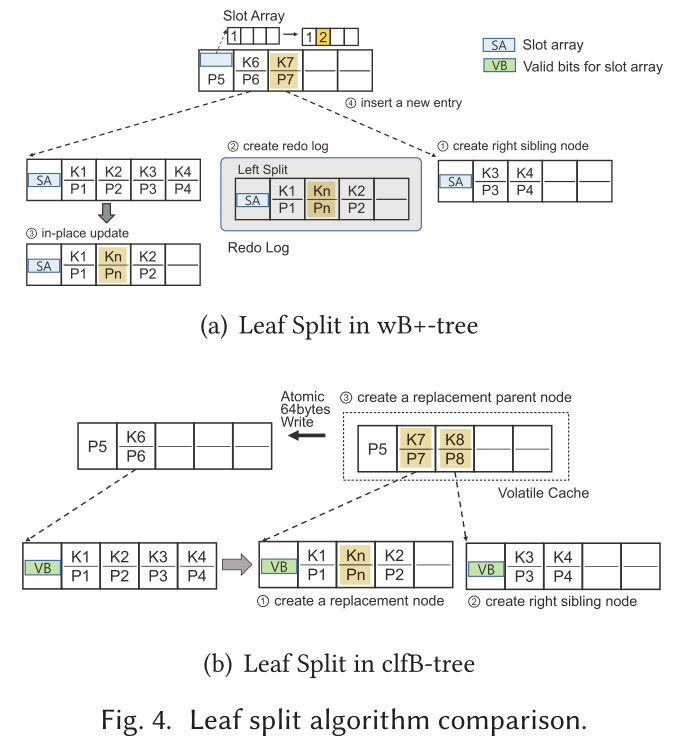
与 wB+tree 不同,clfB-tree 创建两个新的叶节点,并在叶节点溢出时将一半的条目复制到每个节点,如图4(b)所示。在持久化两个新条目之后,在易失性缓存中创建父节点的副本,并将两个指针存储在父节点中。由于父节点可以通过 atomicCacheLineWrite() 或 in-place parent update 自动覆盖现有的父节点,所以只要叶子节点的大小是缓存线大小,clfB-tree 叶子节点的 split 只需要3次 cache line flush 操作。如果一个叶子节点大于缓存线的大小,并且整个叶子节点的更新需要k次cache line flush,那么 clfB-tree 调用 2k + 1 次 cache line flush(1次刷新父节点,2次刷新两个新节点)。在 wB+tree 中,叶子节点拆分需要 2k + 4 次缓存行刷新(2次用于溢出节点的原地更新,k次用于重做日志记录,k次用于右兄弟节点,另外2次用于父节点更新)。
(五)实验
用C语言实现了clfB-tree、slot-only wB-tree 和 CDDS B-tree,与一个 NVRAM 堆管理器 Heapo 集成在一起,并进行实验比较。没有评估 NVtree 和 FP-tree,因为它们不能保证内部树节点的故障原子性。它们不是持久索引,因为当系统故障时,它们需要从叶子节点重建整个树结构。我们将这三个持久b树与一个NVRAM堆管理器—heapo[8]集成在一起。
实验平台:
一个平台是拥有一个 Intel Xeon E7-4809 v3 处理器(2.00GHz, 8 × 32KB指令缓存,8 × 3 2 KB 数据缓存,8 × 256KBytes L2 caches,,20MBytes L3 cache) 和 64GB DDR3 DRAM 的工作站。Xeon E7-4809 v3 处理器支持 TSX (Transactional Synchronization Extensions) 包括 RTM 功能。在这个平台中,假设 NVRAM 和 DRAM 一样快,并且 DRAM 的特定地址范围是 NVRAM。
另一个平台是一个 NVRAM 仿真板–Tuna,拥有 ARM Cortex-A9 处理器, Xilinx Zynq XC7Z020 ARM-FPGA SoC, 以及可以控制两个 DRAM 中的一个的读/写延迟来模拟 NVRAM 延迟的 FPGA 可编程逻辑。
(六)总结
实验结果表明,clfB-tree 在插入和搜索性能上优于 slot-only wB-tree。
这篇关于clfB-tree: Cacheline Friendly Persistent B-tree for NVRAM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[LeetCode] 863. All Nodes Distance K in Binary Tree](/front/images/it_default2.jpg)

