本文主要是介绍鸡尾酒排序解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在数据处理的海洋中,排序算法无疑是引领我们探索数据规律的灯塔。今天,我们要探讨的是一种有趣且独特的排序算法——鸡尾酒排序。鸡尾酒排序,也被称为定向冒泡排序、双冒泡排序或搅拌排序,是冒泡排序的一种变体,它通过改变冒泡排序的单向性,实现了更为高效的排序过程。
一 冒泡排序的优化
让我们回顾一下刚才上一章冒泡排序描述的排序细节,如果[5,8,6,3,9,2,1,7]这个列表为例,当排序算法分别执行到第6、第7轮时,数列状态如下。
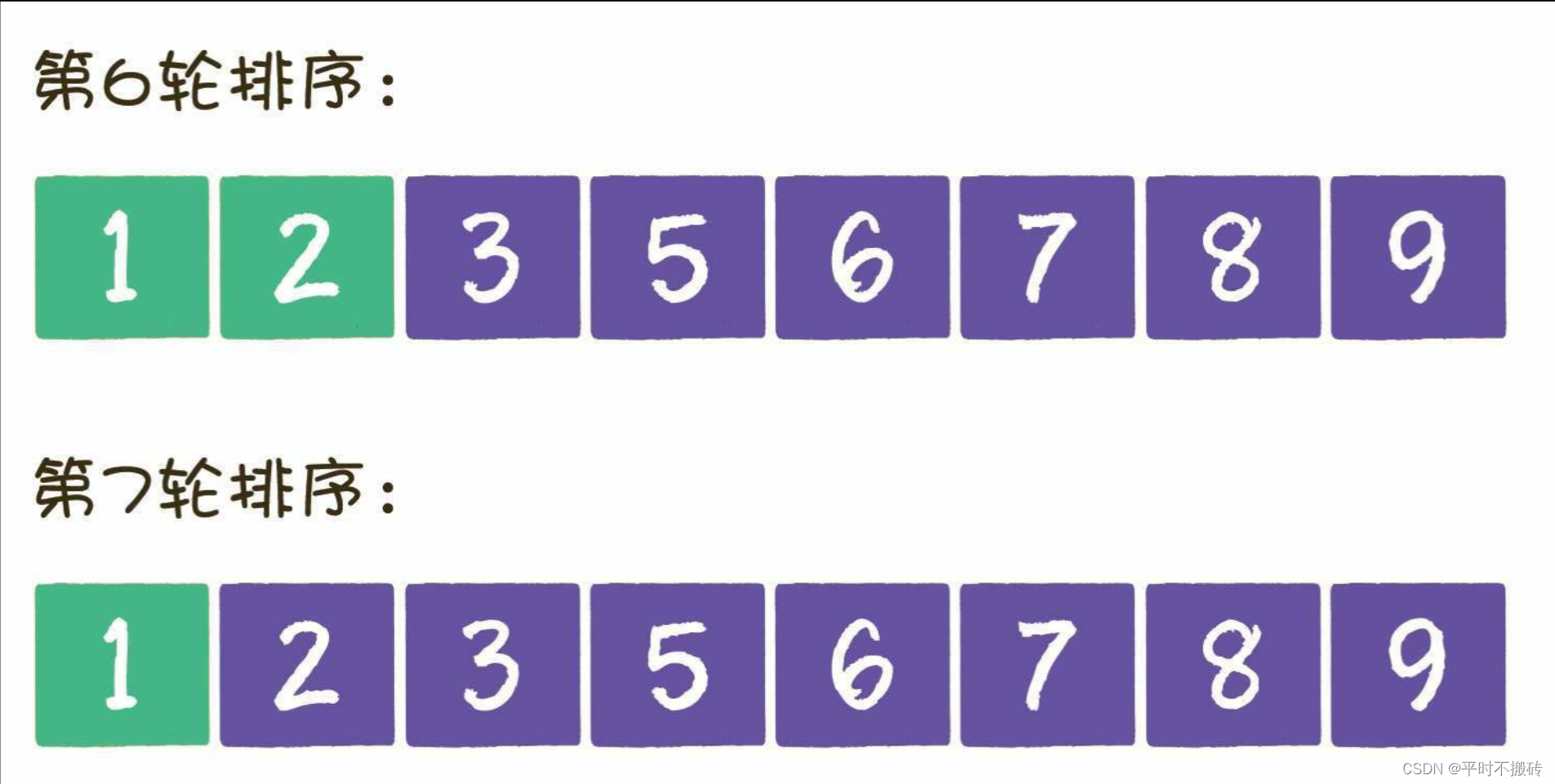
经过六轮排序时,整个列表已经时有序了,而冒泡排序不会感知排序的状态,会继续进行第七次排序。如果列表为[2, 1, 3, 4, 5, 6, 7, 8]呢,其实只是经过一次排序就能得出结构,但是还是会进行6次排序,所以冒泡排序算法的效率并不高。
优化:加标志位
我们知道冒泡排序有可能在提前就知道了排序的结果,那能不能加一个标志位来记录,排序好了就提前退出呢
外层循环加标志位
def optimized_bubble_sort(arr):sorted_num = 0n = len(arr)for i in range(n - 1):# 标志位,记录本轮是否有交换发生swapped = Falsefor j in range(0, n - i - 1):# 如果前一个元素大于后一个元素,则交换它们if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]# 发生了交换,将标志位设为Trueswapped = True# 如果本轮没有发生交换,说明序列已经有序,可以提前终止# 统计排序次数sorted_num += 1if not swapped:break print("排序次数:", sorted_num)return arr# 示例
arr = [2, 1, 3, 4, 5, 6, 7, 8]
sorted_arr = optimized_bubble_sort(arr)
print("Sorted array is:", sorted_arr)其实上面只是优化是通过减少排序的次数,也就是减少最外层循环的次数来优化排序算法,那能不能继续优化呢,答案是肯定的。
我们来看一个列表[3, 4, 2, 1, 5, 6, 7, 8]的冒泡排序
第一轮循环

后面的5, 6, 7, 8是有序,在第一次排序时内层循环4和1交换位置之后其实已经完成了,但是冒泡排序还是会继续将4和后面的5,6,7,8进行比较,同样内层循环也能加标志位来优化来减少内层循环的执行次数。
内层循环加标志位
def optimized_bubble_sort(arr):n = len(arr)for i in range(n - 1):# 标志位,记录本轮内层循环是否有交换发生 swapped = Falsefor j in range(0, n - i - 1):# 如果前一个元素大于后一个元素,则交换它们 if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]# 发生了交换,将标志位设为True swapped = True# 如果内层循环中没有发生交换,说明该部分已经有序,可以提前终止本轮外层循环 if not swapped:breakreturn arr# 示例
arr = [64, 34, 25, 12, 22, 11, 90]
sorted_arr = optimized_bubble_sort(arr)
print("Sorted array is:", sorted_arr)
如上如的代码,每轮内层循环中已经排好序了就直接跳出循环直接进行下一轮循环。但是这两次优化都不是最优的解,下面的鸡尾酒排序是对冒泡排序更进一步的优化。
二、鸡尾酒排序的原理
鸡尾酒排序的核心思想是在序列中来回进行升序和降序的冒泡排序。这种排序方式就像是调制一杯鸡尾酒,来回搅拌,直到所有的元素都按照预定的顺序排列好。
具体来说,鸡尾酒排序的步骤如下:
- 首先,从左到右进行一轮升序的冒泡排序,使得较大的元素逐渐向右移动。
- 然后,从右到左进行一轮降序的冒泡排序,使得较小的元素逐渐向左移动。
- 通过不断重复上述两个步骤,序列中的元素会逐渐变得有序。每一轮排序后,未排序的部分会逐渐缩小,直到整个序列完全有序。
三、鸡尾酒排序的实现
鸡尾酒排序的实现相对简单,但需要注意边界的处理。下面是一个使用Python编写的鸡尾酒排序算法示例:

def cocktail_sort(arr): n = len(arr) swapped = True start = 0 end = n - 1 while (swapped == True): swapped = False for i in range(start, end): if arr[i] > arr[i + 1]: arr[i], arr[i + 1] = arr[i + 1], arr[i] swapped = True if swapped == False: break swapped = False end = end - 1 for i in range(end - 1, start - 1, -1): if arr[i] > arr[i + 1]: arr[i], arr[i + 1] = arr[i + 1], arr[i] swapped = True start = start + 1 return arr
在这个实现中,我们使用了两个指针start和end来标记当前排序的边界。通过不断缩小边界并交替进行升序和降序的冒泡排序,最终实现了整个序列的有序化。
四、鸡尾酒排序的效率与应用
鸡尾酒排序通过改变冒泡排序的单向性,提高了排序的效率。虽然其时间复杂度仍然是O(n^2),但在某些情况下,鸡尾酒排序的性能优于冒泡排序。特别是在数据已经部分有序或者数据规模适中的情况下,鸡尾酒排序能够更快地完成排序任务。
鸡尾酒排序在实际应用中可能不是最优的排序算法,但其独特的排序方式和简洁的实现代码使得它成为学习排序算法和算法设计思想的一个好例子。通过学习和实践鸡尾酒排序,我们可以更好地理解排序算法的原理和实现方法,为后续学习和应用更复杂的排序算法打下基础。
五、总结
鸡尾酒排序以其独特的排序方式和简洁的实现代码吸引了众多算法爱好者的关注。通过学习和实践鸡尾酒排序,我们可以更加深入地理解排序算法的原理和设计思想。同时,我们也可以从中体会到算法设计的巧妙之处和计算机科学的魅力所在。无论是作为学习排序算法的入门之选,还是作为探索算法设计的有趣案例,鸡尾酒排序都值得我们深入研究和探讨。
这篇关于鸡尾酒排序解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







