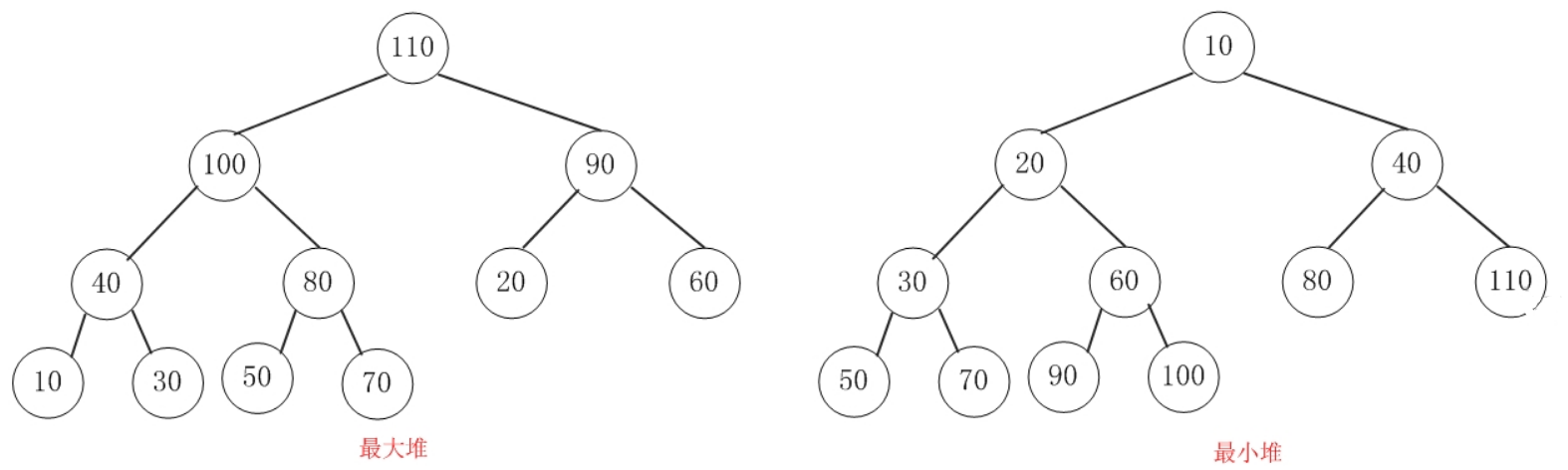
本文主要是介绍Mark :BlockingQueue,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://blog.csdn.net/smuedward/article/details/54574938
(一)BlockingQueue的原理
1. 什么是BlockingQueue?
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
2. BlockingQueue的核心方法:
2.1放入数据:
offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,
则返回true,否则返回false.(本方法不阻塞当前执行方法的线程)
offer(E o, long timeout, TimeUnit unit),可以设定等待的时间,如果在指定的时间内,还不能往队列中
加入BlockingQueue,则返回失败。
put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断
直到BlockingQueue里面有空间再继续.
2.2 获取数据:
poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,
取不到时返回null;
poll(long timeout, TimeUnit unit):从BlockingQueue取出一个队首的对象,如果在指定时间内,
队列一旦有数据可取,则立即返回队列中的数据。否则知道时间超时还没有数据可取,返回失败。
take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到
BlockingQueue有新的数据被加入;
drainTo():一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数),
通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。

1、ArrayBlockingQueue:一个由数组支持的有界阻塞队列,规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小.其所含的对象是以FIFO(先入先出)顺序排序的。
2、LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制,若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定.其所含的对象是以FIFO(先入先出)顺序排序的。
LinkedBlockingQueue 可以指定容量,也可以不指定,不指定的话,默认最大是Integer.MAX_VALUE,其中主要用到put和take方法,put方法在队列满的时候会阻塞直到有队列成员被消费,take方法在队列空的时候会阻塞,直到有队列成员被放进来。
LinkedBlockingQueue和ArrayBlockingQueue区别:
LinkedBlockingQueue和ArrayBlockingQueue比较起来,它们背后所用的数据结构不一样,导致LinkedBlockingQueue的数据吞吐量要大于ArrayBlockingQueue,但在线程数量很大时其性能的可预见性低于ArrayBlockingQueue.
这篇关于Mark :BlockingQueue的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!