本文主要是介绍python-itheima,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
字面量
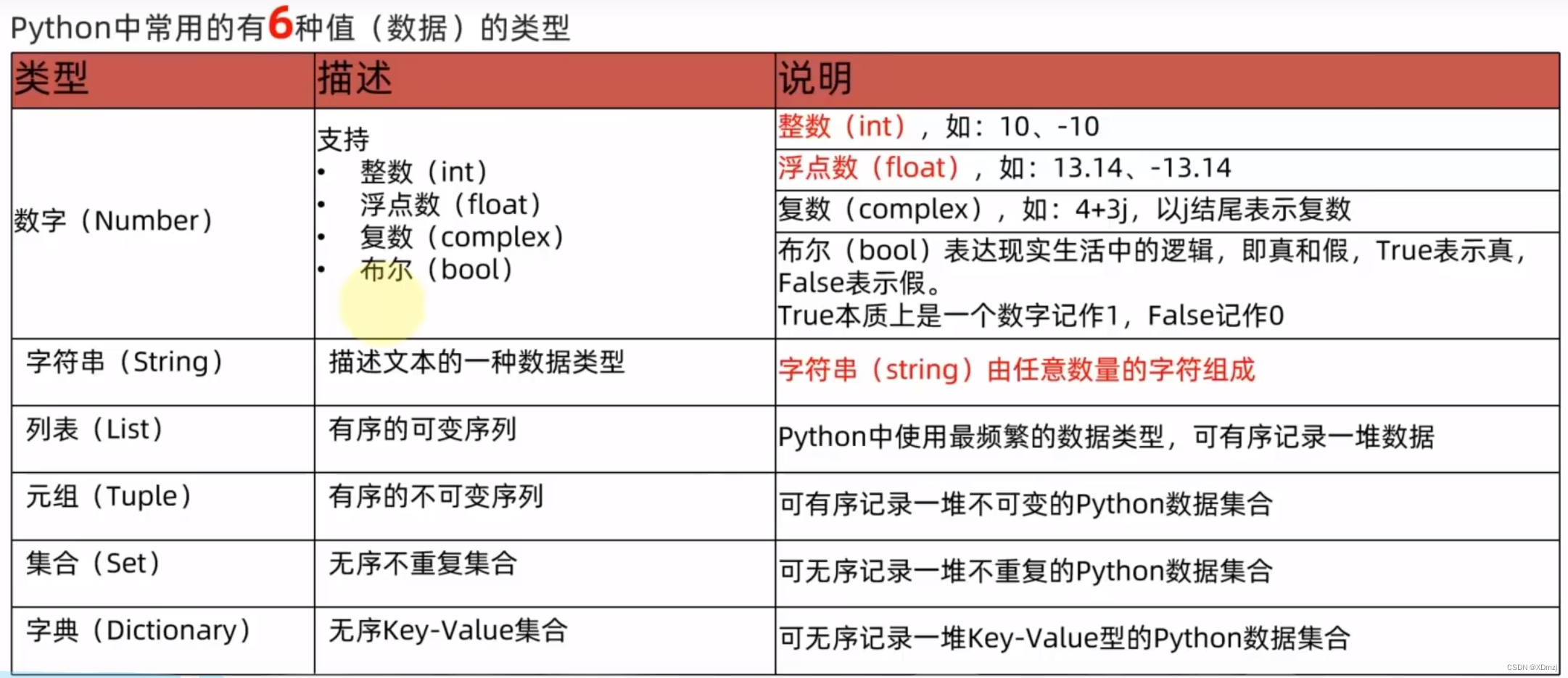
先介绍数字与字符串,剩余四种数据类型容后再议
- print用法
- print(数字)
- print(“字符串”)
- print(x,y,z,“abcdefg”)
数据类型查看
type函数
数据类型转换

标识符相关

字符串定义方式
方式
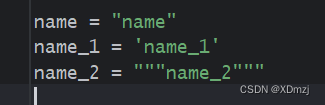
嵌套引号

name = " \"两边是引号\" "
字符串的拼接
法一
“字符串” + “字符串” + str(只能是字符串类型变量)
法二(格式化)
“字符串 %s” % 变量(可以是任意类型)
“字符串 %s %s” % (变量1,变量2)
格式化的精度控制
格式:% + m.n + 类型
Num = 11.4514
print("数字长度为8,保留两位小数:%8.2d" % Num)
结果:数字长度为8,保留两位小数: 11.45
m表示总长度,如果比数字本身短则不生效
n表示保留小数点后位数
格式化的优雅方式
print(f"语句 {变量} 语句 {变量}")
f的意思是fomat(格式化)
name = "name"
name_1 = 114.514
name_2 = """name_2"""
print(f"哈哈{name}哈哈哈{name_1}哈哈哈{name_2}哈哈哈")
格式化表达式
目的是:不需要将每个表达式的结果都用变量存起来然后格式化以简化代码
print("1 + 1 = %d" % (1+1))
print(f"1 + 1 = %d" {1+1})
print("字符串的类型是 %s" % type('字符串')) #可以直接将函数的结果打印,不用变量接受
例题

代码
name = "周姝妤智商有限公司"
stock_price = 6.66
stock_code = 114514
stock_price_daily_growth_factor = 2.33
growth_days = 10
print(f"公司:{name},股票代码:{stock_code},当前股价:{stock_price}")
print("每日增长系数是:%f,经过%d天的增长以后,股价达到了:%f" % (stock_price_daily_growth_factor, growth_days,stock_price*(stock_price_daily_growth_factor**growth_days)))
结果

数据输入(input函数)
input返回类型是字符串
password = input("你的原神uid是:")
print(type(password))
password = int(password)
print(type(password))
结果

布尔类型
bool:赋值为TRUE FALSE
本质上是一位的0和1
布尔类型的值可以通过比较运算来得到
- 如:result = 7>2 中result为TRUE
print(f"10 > 9 的结果是:{10>9}")

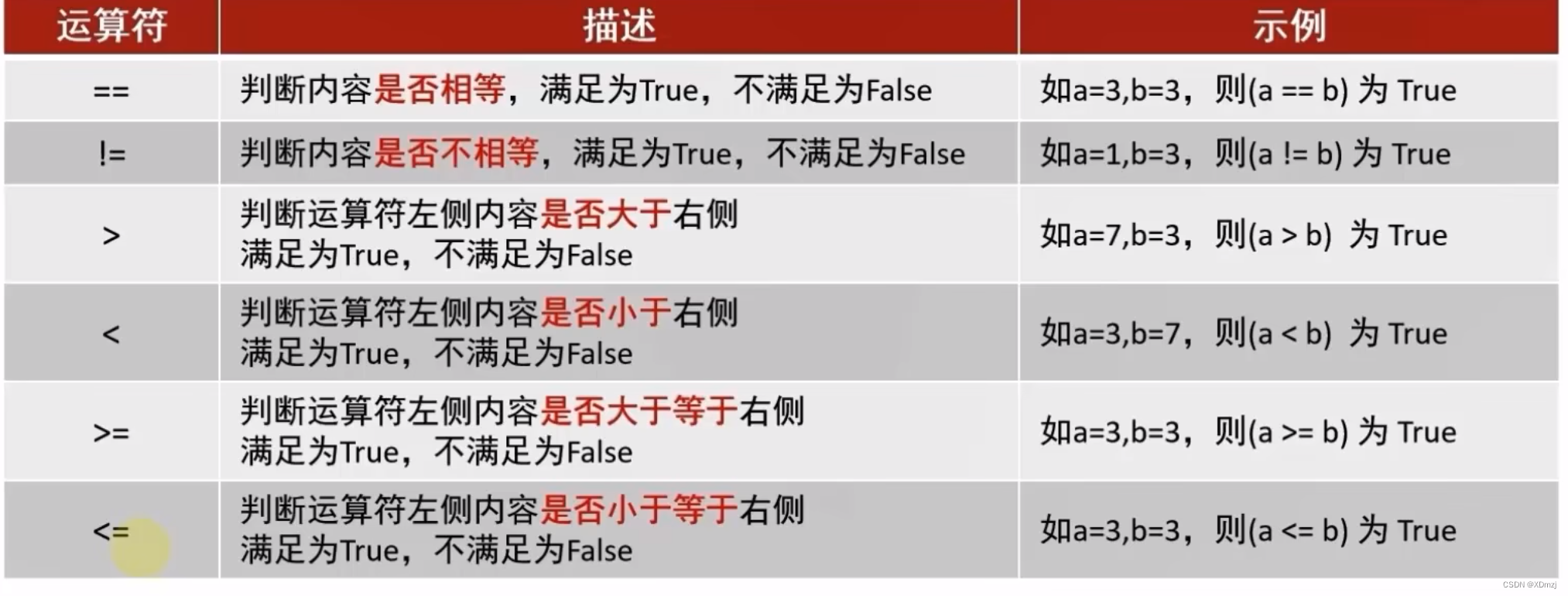
比较运算符
分支语句
if else
语法
1.if
year = input("你的出生年份是:")
year = int(year)
age = 2024 - year
if age >= 18:print("你可以玩夏日狂想曲")
2.else
age = input(“你的年龄是")
if age >=18:print("老登爆金币")
else:print("小B崽子进去吧")
3.elif
num = 10
if int(input("第一次猜数字")) == num:print("1")
elif int(input("第二次猜数字")) == num:print("2")
else:print("wrong")
嵌套
python是以缩进来表示层次关系
if a==1:if b==2:if c==3:
循环语句
while
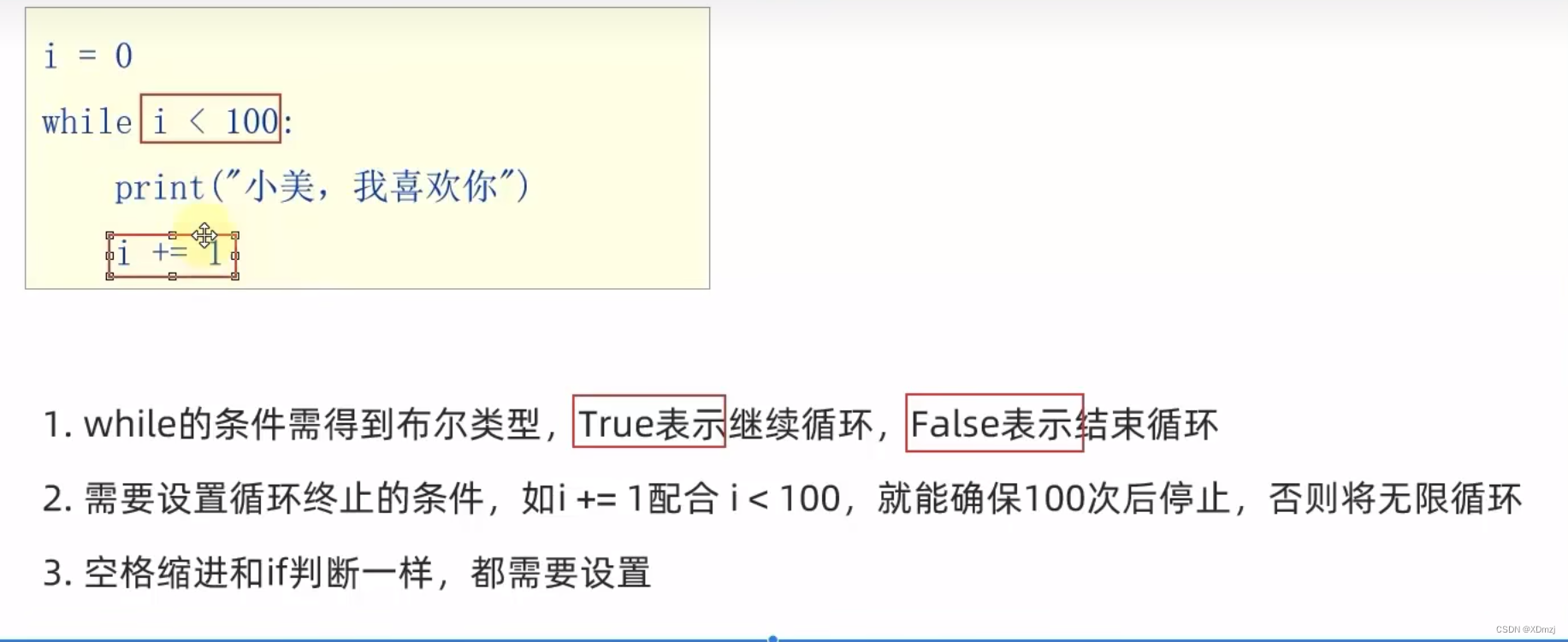
i = 1
a = 0
while i<= 100:a += ii += 1
print(a)
猜数字
import random
num = random.randint(1,100)
flag = True
while flag:num_1 = int(input("your answer:"))if num_1 == num:flag = Falseprint(f"猜对了,就是{num}")elif num_1 < num:print("猜得小了")elif num_1 > num:print("猜的大了")
九九乘法表
知识
- print输出不换行的方法:括号内尾端加end=‘’
- print输出对齐的方法:空格替换成 \t
code
i = 1
while i < 10:j = 1while j <= i:print(f"{i} x {j} = {i*j}\t", end='')j += 1print("")i+=1
for循环,与c中的for有很大区别
语法


实例
password = "18335091109"
for x in password:print(x,end='')
结果:

range语法
这里只介绍基础部分的语法,不深入
range(num)
# 得到一个从0到num-1的序列
range(num1 ,num2)
# 得到一个从num1 到num2的序列,不包含num2
range(num1, num2, num3)
# 得到一个从num1到num2,并以num3为步长的序列,不包含num2
# 如range(1,10,2) = {1,3,5,7,9}
函数
语法
def 函数名(参数名):函数体return
python中函数的思想继承于c,本质相差不大。
但是python中的类型声明不明确,省了不少麻烦,注意格式与冒号即可
python中不写返回值,默认是None
例
def add(x, y, c):ret = x+y+creturn ret
not
not相当于c中的非,就是:!
说明文档
python中的函数中可以写说明文档,对每个变量、返回值进行注释。
注释内容要包括在多行注释**“”“ ”“”**中
def add(x,y,v,c,b)""":param x: 原神:param y: 王者:param v: 第五:param c: 粥:param b: 火影:return: 三国杀"""ret = x+y+v+c+breturn ret
global
局部变量
函数内创建的变量,函数外不能调用。
想要调用,就要用关键字global
示例:
def add():num = 1
print(num) 报错def add():global numnum = 1
print(num) 成功
全局变量
函数外定义的变量就是全局变量
函数内可以随意读取全局变量
但是不能修改
如:
c=1
def add():print(c) 可c+=1 错# 想要修改,需要加global关键字
def add():global cc+=1 可
多返回值
直接用,隔开即可,注意接收返回值时要一一对应

多方法传参
位置传参
C语言的传参方法
关键字传参
形参 = 实参
一一对应,不用管顺序
def add(x,y,z):return x+y+z
add(x=1,z=101,y=123)
缺省传参
定义函数时给形参一个默认值,如果在函数的使用中没有传参,则使用默认值。
注意:定义默认值时必须从后往前定义
def user(name, tele, gender = 'man'):print(name , tele , gender)
不定长传参
例:
def add(*args):print()
def add1(**kargs):print()add(1,2,3,4,5,6,"原神")
add1(a:1 , b:2 , c:3)
- 不定长的意思就是可以穿任意长度,任意个数的参数。
- 一个*,意思是传入的参数按照元组的形式来储存
- 两个**,意味着传参时必须用键值对(字典)的形式来传,传进去以后也是按照字典的形式来使用这个参数
函数作为参数传参
定义:
将函数作为参数传递到另一个函数中去使用
本质上是逻辑的传递

数据容器
定义:

列表list
语法
定义

嵌套
列表里可以再嵌套列表
li = [ [1,2,3,4], [5,6,7,8,9] ]
下标索引
像数组一样,可以根据下标获取数据元素
正向索引

反向索引
新科技,很神奇吧
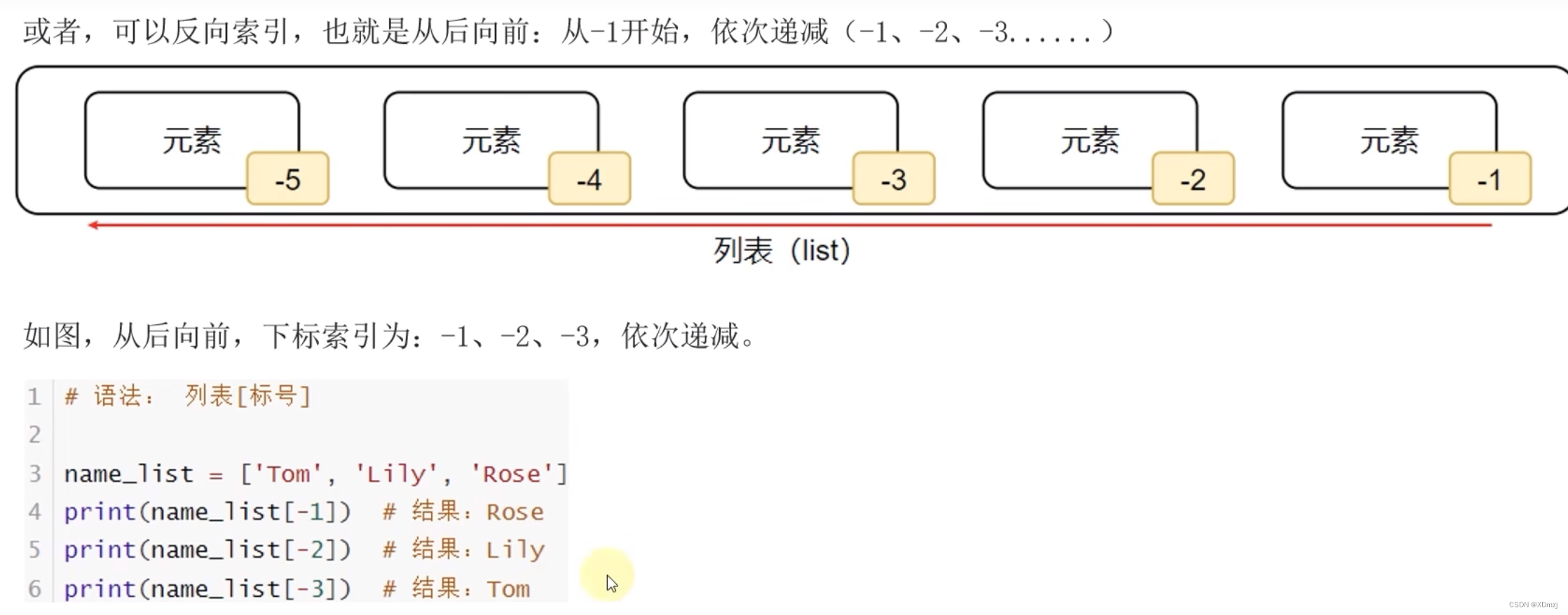
常见方法(功能函数)
代码
key = ["原神", "王者", "方舟"]
# 1.插入
key.insert(3,"火影")# 2.删除
del key[0]
# 或者key.pop(0)
# pop是一个函数,返回值是被删除的元素# 3.追加
key.append("鬼泣")
sex = ["夏日","冬日", "千恋"]
key.extend(sex)# 4.指定元素删除
key.remove("夏日")
# remove只会删除遇到的第一个符合条件的元素# 5.计数,统计列表中的某一个元素有几个
key.count("冬日")# 6.查找元素下标
key.index("方舟")# 7.计算列表元素总个数
len(key)
print(key)
遍历
while和c中遍历数组没区别
for循环
name = ["dante", "naro", "vergil", "kryie", "nico", "radi", "eva", "tris"]
for element in name:print(element)
元组(tuple)
不可修改的列表
定义:
t1 = (1,2,3)
t2 = ()
t3 = tuple()
t1 = (1, )
# 以上都是元组
# 注意t1 = (1)不是元组,是整数 t1 = (1,)才是元组
操作

t1 = (1,2,3,4)
len(t1)
t1.count(2)
t1.index(3)
特例
更改元组内容
lis = [1,2,3,4]
t1 = ( lis , 5,6 )
lis[2] = 1
#此时t1也会发生变化
字符串 str
定义
str = "汉字 word 123"
方法
字符串是不可以修改的,replace等方法知识得到一个新数组,不能对原数组进行修改

replace
str = "i love you"
new_str = str.replace("you","her")
split
分割字符串,得到新列表
str = "原神0王者0火影"
new_str = str.split("0")
得到:

strip
去除首尾的指定数组(默认为空格或换行符)
str_1 = " 123 "
new_str_1 = str_1.strip()str_2 = "123原神启动!321"
new_str_2 = str_2.strip("123")
得

注意: strip中如果输入了多个字符,则将字符串首尾所有相同条件的字符都删除,不论顺序
集合 set
定义
my_set = {1,2,3,4,6}
my_set = set()
特点:
- 可修改内容
- 不支持重复内容
- 不支持下标访问
- 集合是无序的
空集合不能用{}来定义,用{}的意思是定义字典
操作
添加:
集合的添加函数没有返回值,直接修改原集合
my_set = {1,2,3,4,5,6,7,8,9}
my_set.add("元素")

随机取出一个元素:
my_set = {123,321,213,312,231,132}
i = my_set.pop()
#### 清空:
my_set = {1,2,3,4,5}
my_set.clear()
取差集:

my_game = {"饥荒","DMC","泰拉","求生之路"}
her_game = {"饥荒","求生之路","火山"}
game = my_game.difference(her_game)
取合集:

set1 = {1,2,3}
set2 = {3,4,5}
set3 = set1.union(set2)
# set3 = {1,2,3,4,5} 注意集合的元素不重复
字典dict
定义

name = {1:"Yuanshen", 2:"wangzhe", 3:"huoying"}
注意,字典键值对的key不允许重复,后来者优先
操作
获取

name = {1:"Yuanshen", 2:"wangzhe", 3:"huoying"}
print(name[2])
嵌套
my_dict ={"列表":[1,2,3,], "字符串":"123", "元组":(1,2,3), "集合":{1,2,3} , "字典":{1:1, 2:2, 3:3}}
print(my_dict["字典"][1])
注意事项:

数据容器对比
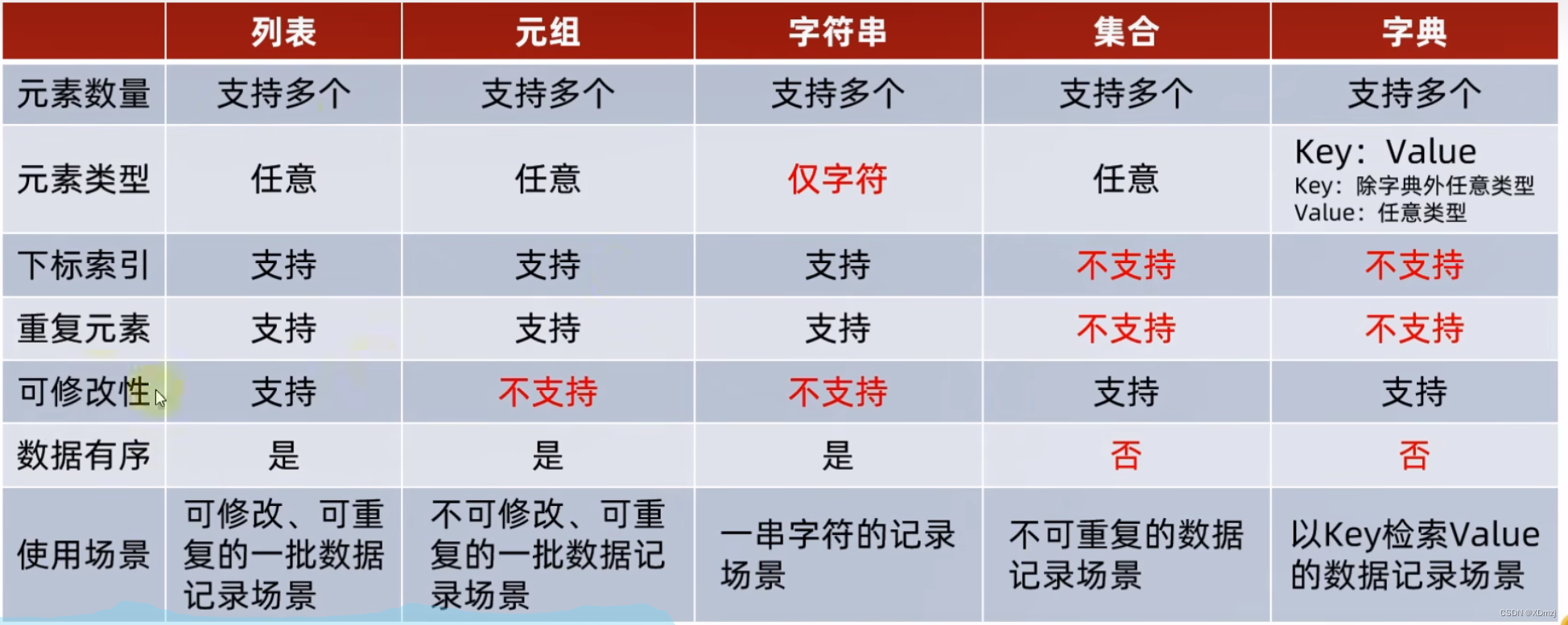
通用操作
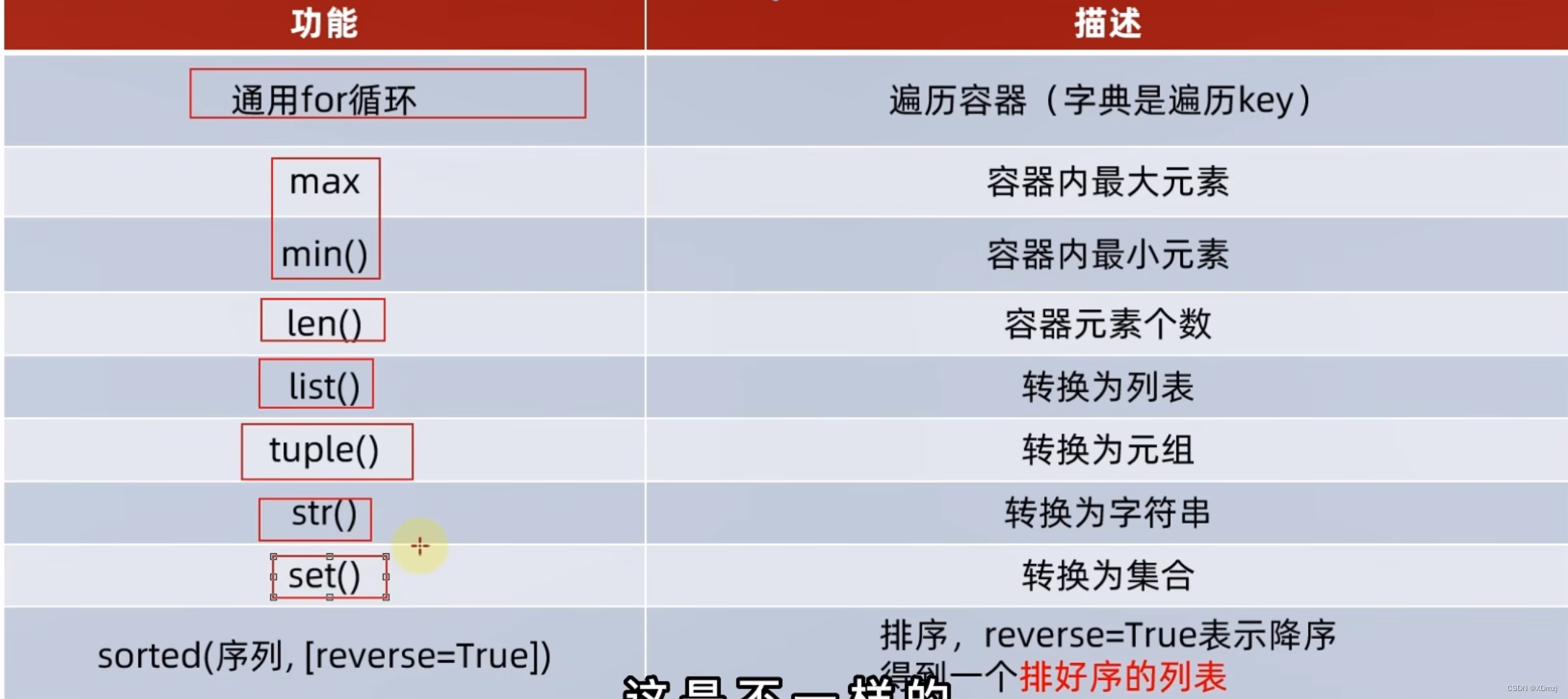
sorted
举例:
jing = (1,2,3,4,5,6,7)
jing = sorted(jing , reverse = True)
序列
定义

操作
切片
语法:

**注意: ** 切片不改变原来的序列,只返回一个新序列
game = [1,2,3,4,5,6,7,8,9,10]
game_1 = game[::2]
print(game_1)
倒着取
game = [1,2,3,4,5,6,7,8,9,10]
game_1 = game[9:3:-1]
print(game_1)
文件基础
文件编码
将各种资源转换成二进制数据的协议
如:
文本类-UTF-8
视频类-mp4
文件操作(函数)
打开

读取
read函数
file = open("F:/101.txt","r",encoding="UTF-8")
file.read(10)
# read中的参数表示读取的字节数,不管换不换行,只管够不够10个字节
# 如果read函数不传参数,则认为读取所有元素
readline与readlines函数
file = open("F:/101.txt","r",encoding="UTF-8")
flie.readline()
# readline的功能是读取一行
flie.readlines()
# readlines的功能是读取所有行
注意: read系列的文件操作函数具有继承性,意思就是,对于同一个文件,后执行的read系列函数会接着已经执行的read函数读取的尾部继续读取
for循环读取文件的行
file = open("F:/101.txt","r",encoding="UTF-8")
for line in file:print(line)
关闭文件
为什么要关闭文件呢?
如果不关闭文件,会影响其他操作。如:删除,改写
函数:close
file = open("F:/101.txt","r",encoding="UTF-8")
file.close()
with open() as file语法

with open("F:/101.txt", "r", encoding="UTF-8") as file:print(file.readline())
写入
file = open("F:/102.txt","w",encoding="UTF-8")
file.write("天天就知道启动你那个B原神。启动牛魔")
file.flush() # 刷新缓冲区,将缓冲区中的数据正式写入到硬盘中
file.close
注意: mode="w"时,如果你对文件内容进行了写入,python会将文件中原有的数据全部清除,以新数据覆盖。

追加
用法

异常
捕获语法

-
将可能出现错误的地方写到try中,用except来捕获异常。
-
逻辑是:python正常执行程序,当执行到try中的语句时,若异常出现,则到except中执行其中语句,并且不停止文件运行。无异常则不执行。
-
另:else与finally语句可写可不写
-
except后可以写具体的异常类型来圈定捕获范围(就是指定捕获那种错误)
file = open("F:/100.txt","w",encoding="UTF-8")
try:file.write("原神")
except:print(0) # 出错则打印0
else:print(1) # 不出错则打印1
异常的传递性

函数嵌套中,某一环节出了错,若它与它的上层函数都没有捕获异常,就会报错,而且报错是从上层一路报到错误点

模块
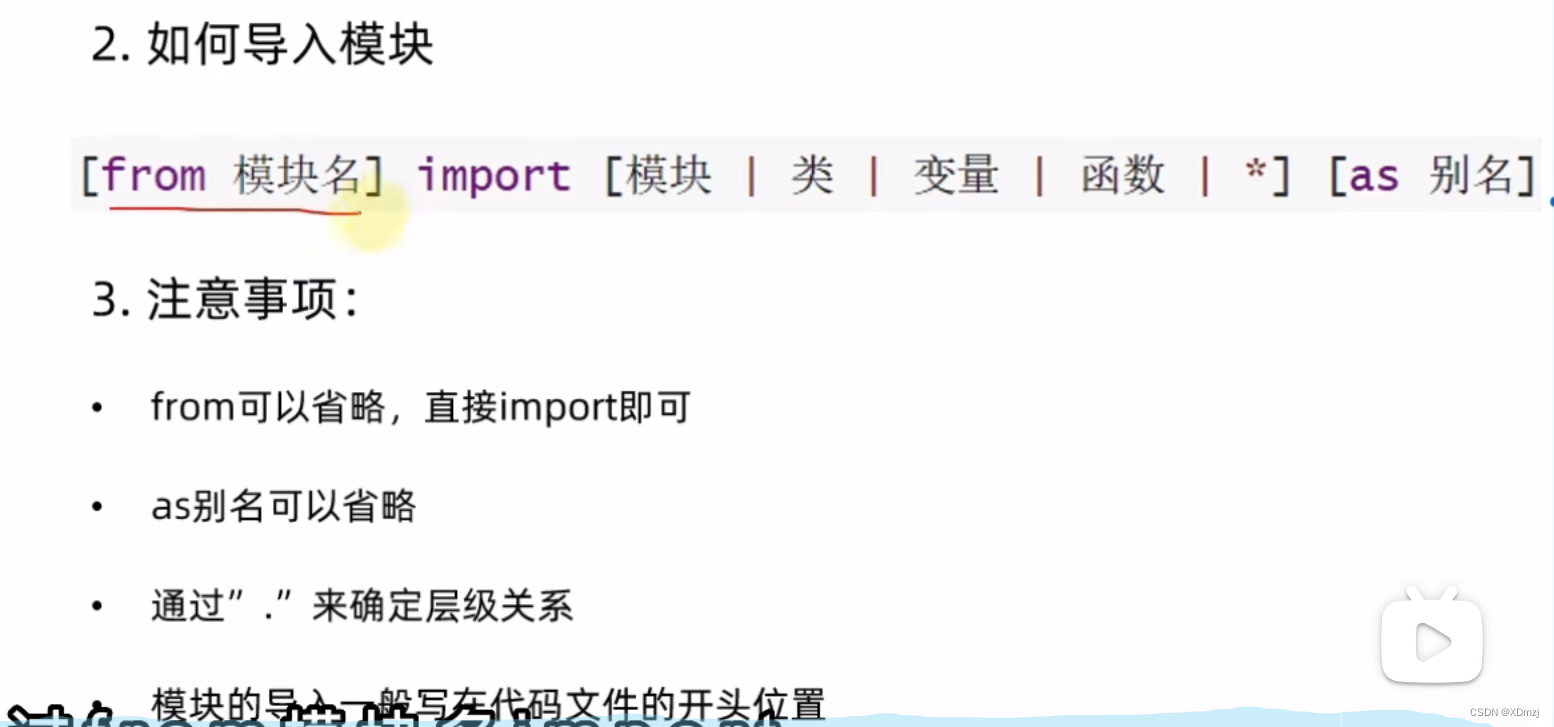
概念:另一个含有函数、类、变量等的python文件,你在其他文件中可以调用这个文件来实行一些功能
就和c语言中的头文件一样
例:
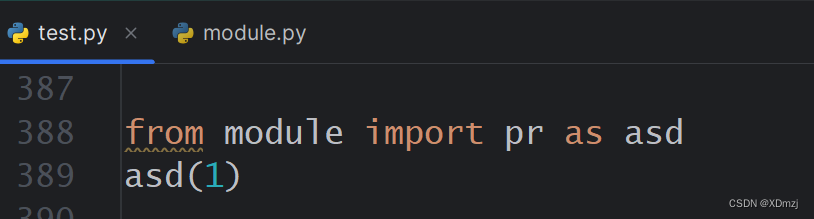
如何导入:
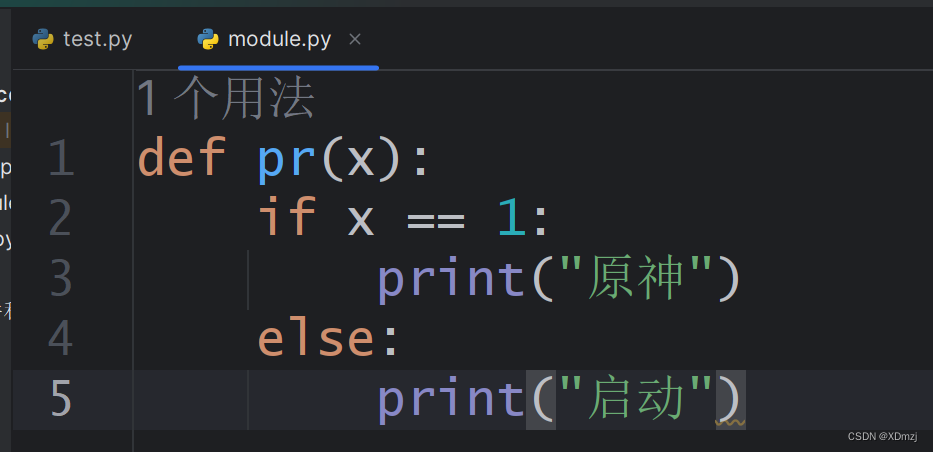
自定义模块
即:import自己写的文件,取用其中的函数、变量、类等

内置变量
- vars()函数可以以字典的形式打印出此文件中所有的内置变量及其值
- name
- file
- time
等等
包
模块较多时,为了便于管理而出现的概念。
本质上还是模块。
(文件夹和文件的关系?)
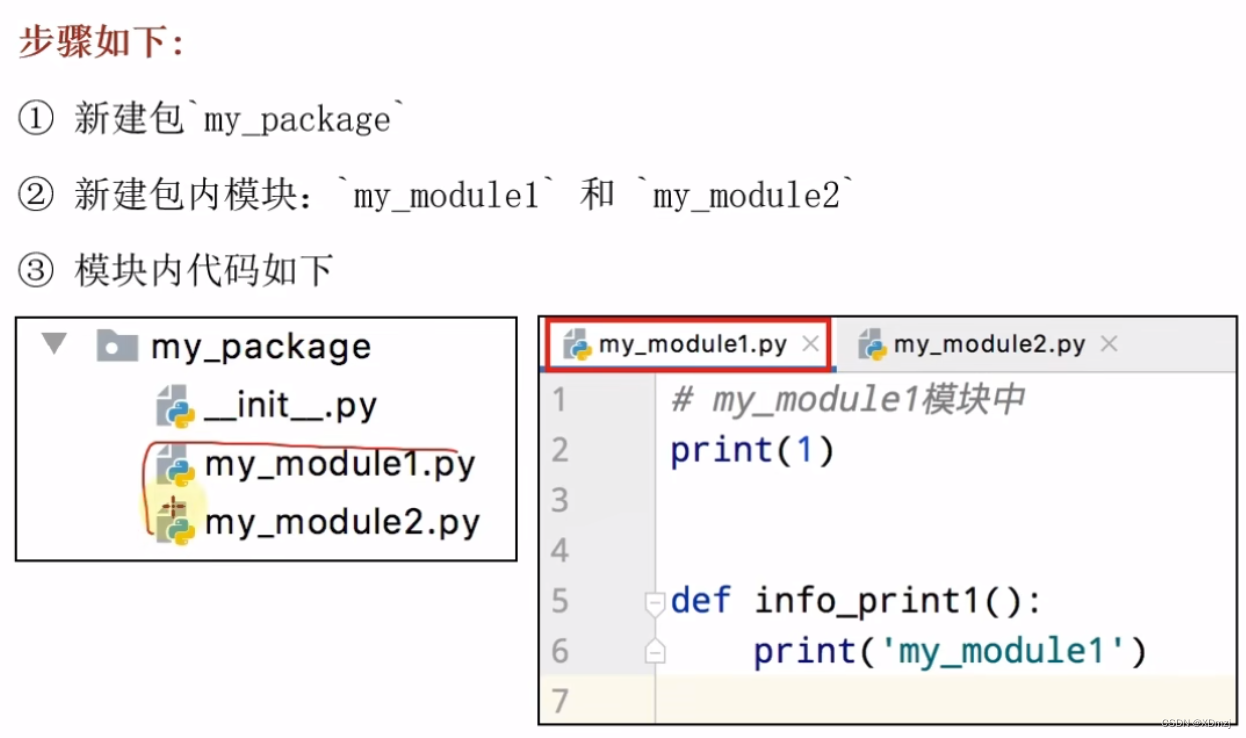
使用
引入



另

第三方包
pip安装
镜像网站安装
就是别人写好的包
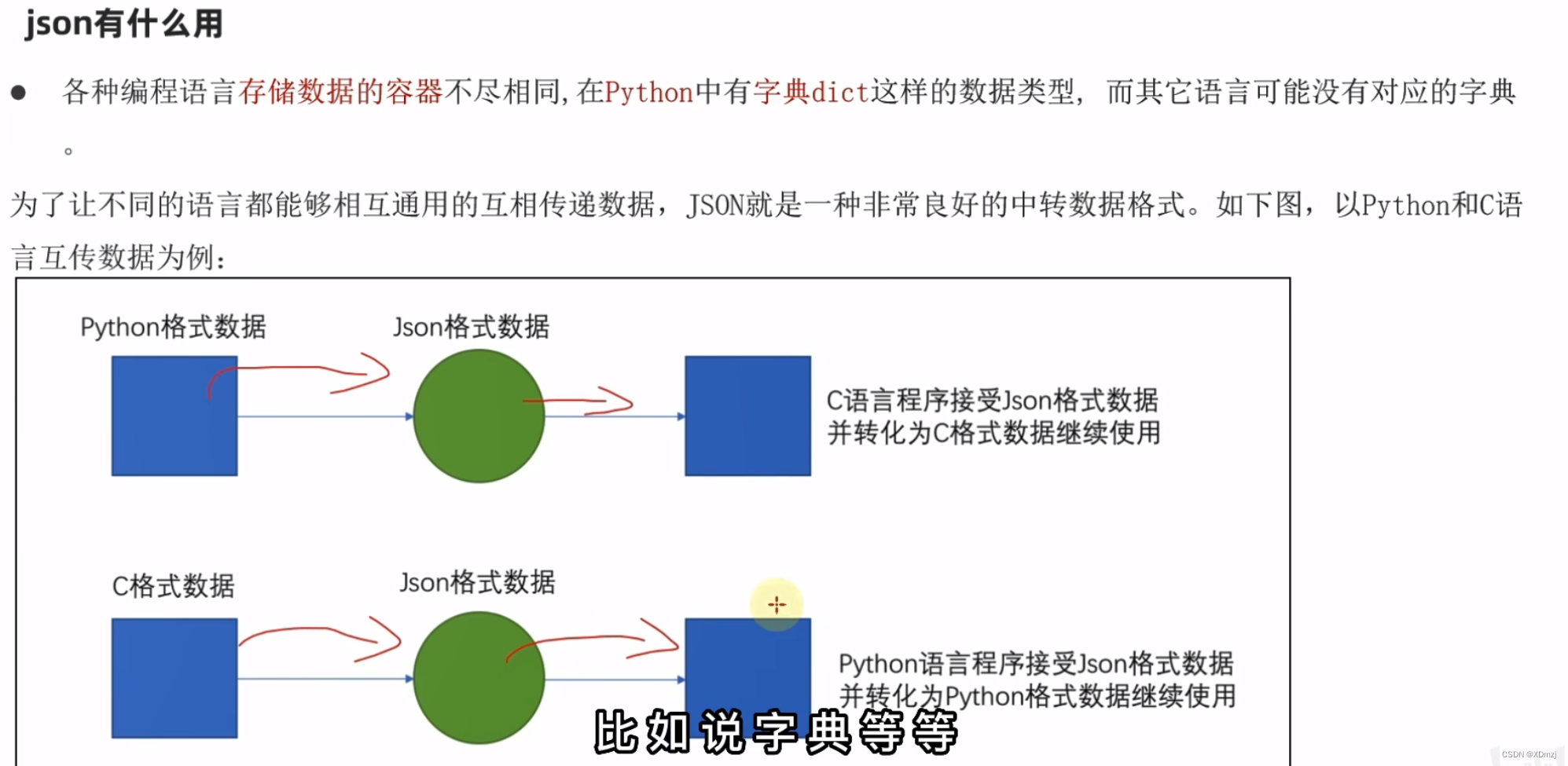
json
概念:

作用:
类
欢迎来到编程的世界
类就是有组织的集合数据。
对象是类的实例化。
(类是工具模板,对象是用模板制作的实际工具)
类的组成
变量与方法
class Student:name = Nonedef add(self): # 类的方法必须加self才能用print("你好")stu_1 = Student() # 对象,类的实例化
stu_1.name = "mzj"
stu_1.add()
使用例子:
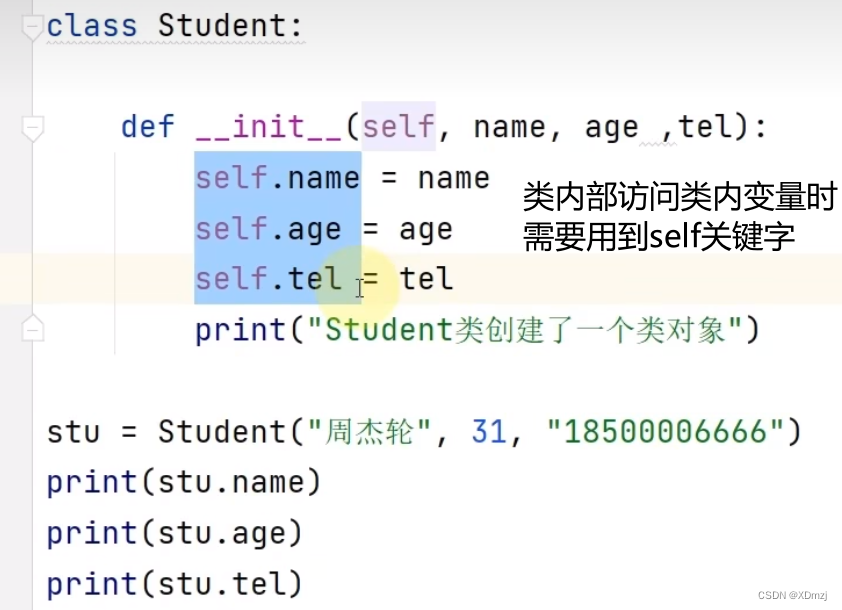
关于self
在python的类的方法中,在方法的括号中加入self才能被其对象调用。如果不加只能通过 类名.方法名() 来调用
class Student():name = "mzj"def prinT():print("11")
Student.prinT() # 能打印
stu = Student()
stu.prinT() # 不能
class Student():name = "mzj"def prinT(self):print("11")
Student.prinT() # 不能用
stu = Student()
stu.prinT() # 能用
魔术方法(类内置方法)
魔术方法就是对类的一些自定义操作
如:
__lt__自定义了怎么比较大小
__init__自定义了怎么初始化对象
__str__自定义了对象作为字符串时被使用该怎么表示
大致可以分为这几类:

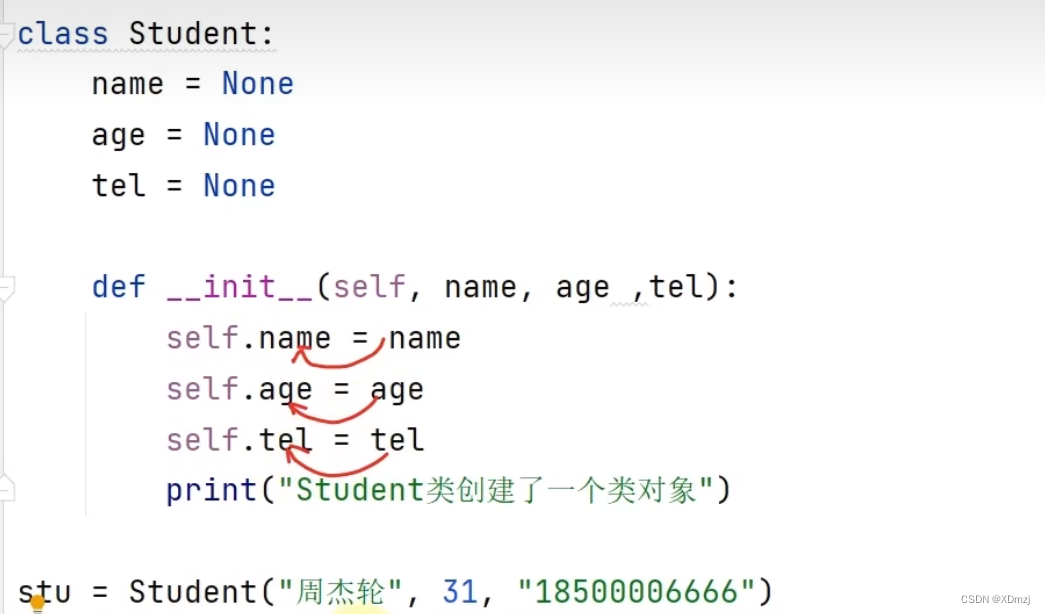
构造方法
__init__
类内部的一个方法,功能是,在创建对象时自动运行,对对象进行初始化。
例:
字符串方法
__str__
用法:
正常情况下,你打印一个对象,得到的是它的地址,但是你可以通过这个内置方法来自定义打印什么
用法:
class Stu:name = "mzj"
stu = Stu()
print(stu)
# 结果为:<__main__.Stu object at 0x000001A7FC819490>
class Stu:name = "mzj"def __str__(self):return (f"学生的名字是{self.name}")
stu = Stu()
print(stu)
封装与私有成员
将现实生活中的事物抽象描述成类即为封装

继承
语法
创建新类的时候在后面加(父类)
单继承:

多继承:
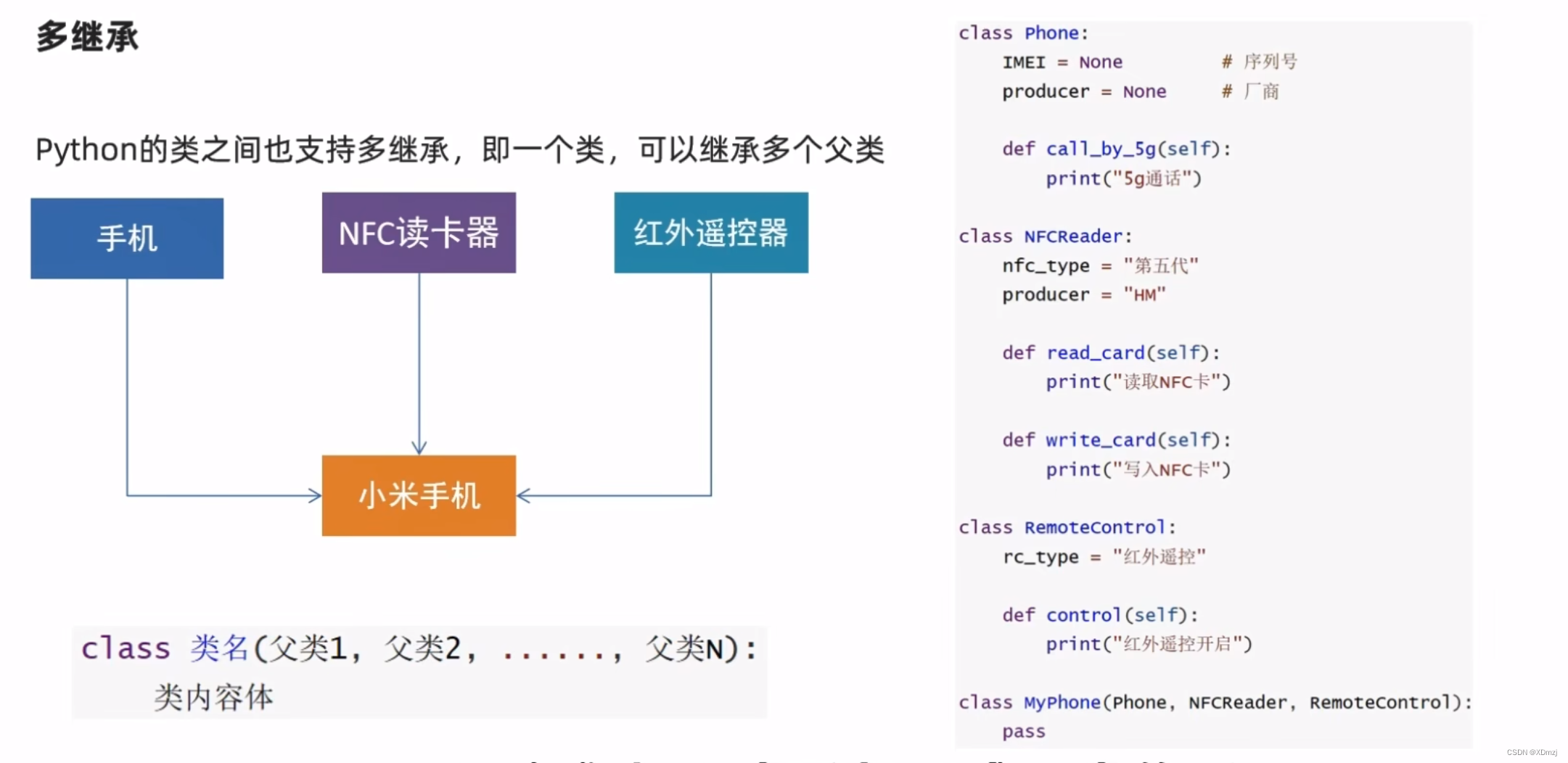
多继承时,多个父类中若有同名变量或方法,按照继承的顺序来确定优先级
class a:z=1
class b:z=2
class c(b,a):pass
c_1 = c()
print(c.z)
复写
基础语法

调用原父类内容
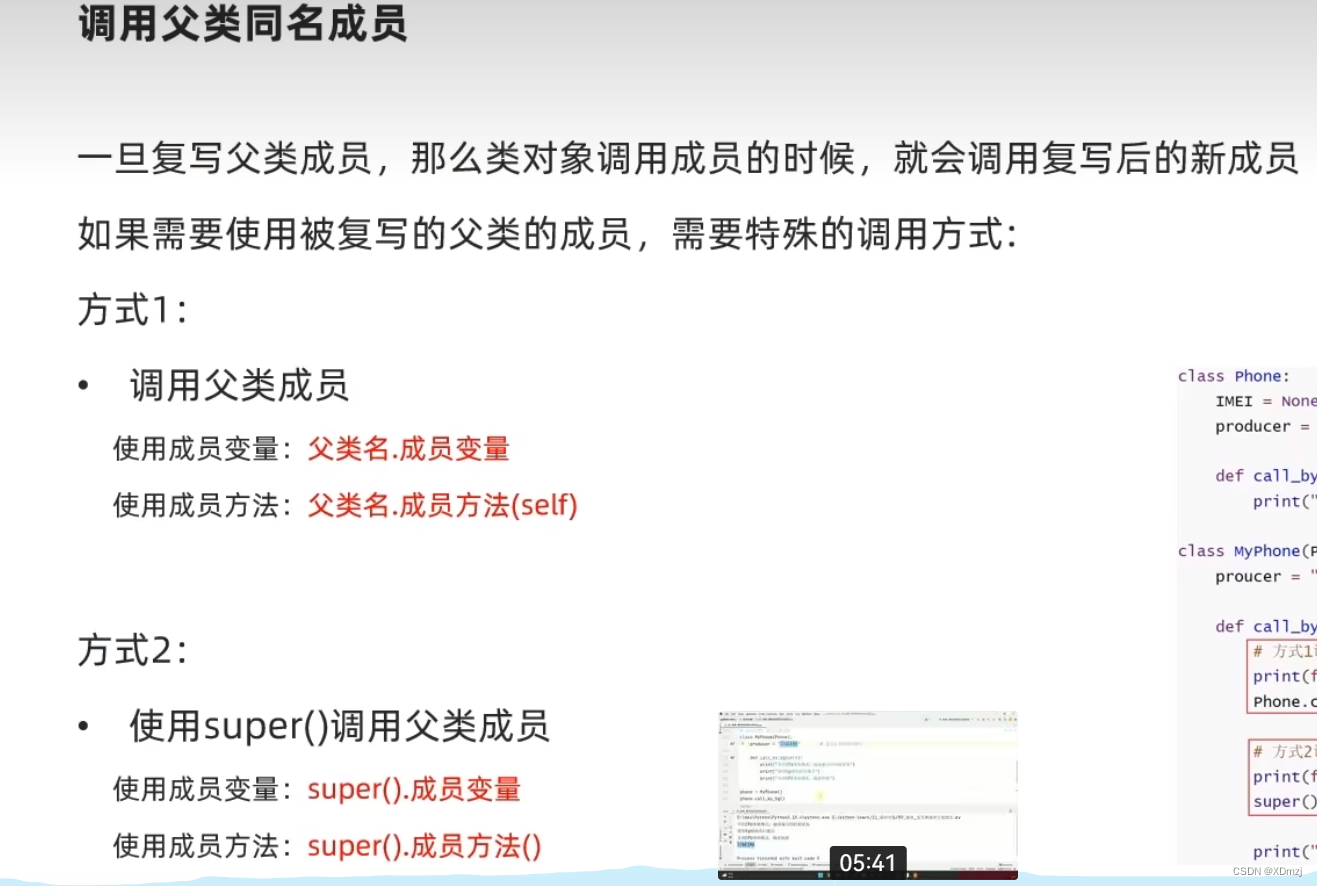
示例:
class yuan:def pr_1(self):print("原神")
class ni(yuan):def pr_1(self):print("我不玩")# 方法1yuan.pr_1(self)# 方法2super().pr_1()passwangge = ni()
wangge.pr_1()
类型·注解
方法与用处:



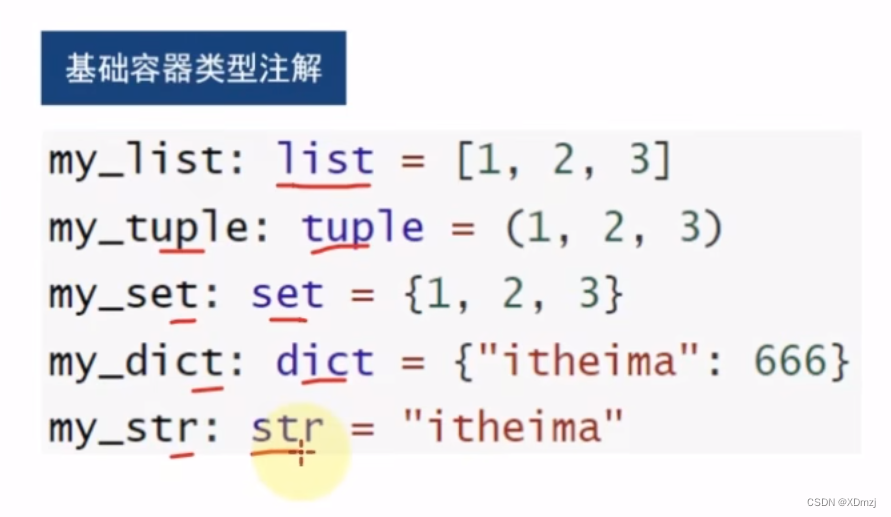

另一种方法

函数注解
形参注解
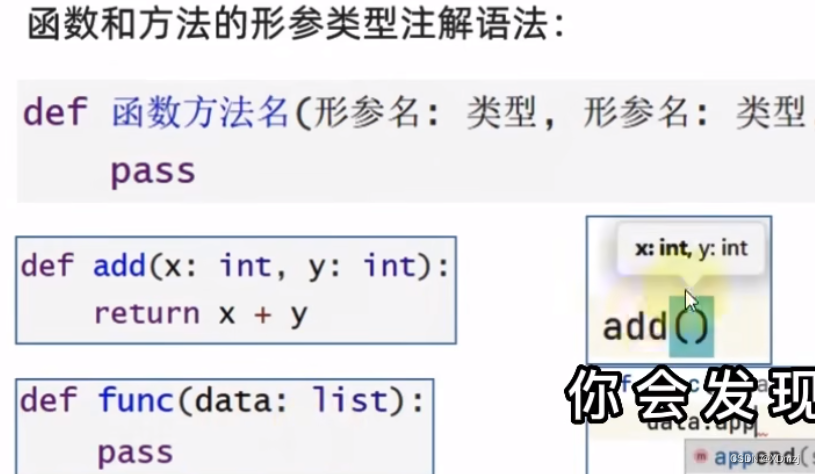
返回值注解

def length(x:str)->int:return len(x)
Union注解
Union在typing包中
用来进行联合类型注释
联合类型是什么意思呢?
lis = [1,2,1.2,"12"] # 这个列表中的元素类型有三种,用之前的方法来注解类型将会 很困难 ,所以开发了这个包,用来进行多类型注解
用法
from typing import Union
lis:Union[int,float,str] = [1,1.2,"123"]
多态
定义:龙生九子,九子不同
继承于同一个父类的不同子类,对父类抽象方法进行复写后使得通过不同子类调用同名方法时所得结果不同
用法
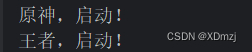
class Game():def chengfen(self):pass
class Genshin(Game):def chengfen(self):print("原神,启动!")class nongyao(Game):def chengfen(self):print("王者,启动!")def chachacf(game:Game):game.chengfen()nong = nongyao()
O = Genshin()
chachacf(O)
chachacf(nong)
结果:
这篇关于python-itheima的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





