本文主要是介绍RabbitMQ3.13.x之十_流过滤的内部结构设计与实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RabbitMQ3.13.x之十_流过滤的内部结构设计与实现
文章目录
- RabbitMQ3.13.x之十_流过滤的内部结构设计与实现
- 1. 概念
- 1. 消息发布
- 2. 消息消费
- 2. 流的结构
- 1. 在代理端进行过滤
- 2. 客户端筛选
- 3. JavaAPI示例
- 4. 流过滤配置
- 5. AMQP上的流过滤
- 6. 总结
- 3. 相关链接
1. 概念
流过滤的思想是在代理端提供第一级的高效过滤,而无需代理解释消息。 这样,只需要流子集的使用者就不需要自己获取所有数据并处理所有过滤。 这可以大大减少传输给消费者的数据。
通过筛选,可以将筛选器值与每条消息相关联。 它可以是地理信息,例如每条消息来自的世界区域,如下图所示:

因此,我们的流有 1 条(绿色)消息、1 条(深蓝色)消息、2 条(紫色)消息,然后是 2 条消息。AMER``APAC``EMEA``AMER
1. 消息发布
发布者可以将每封出站邮件与其筛选器值相关联:
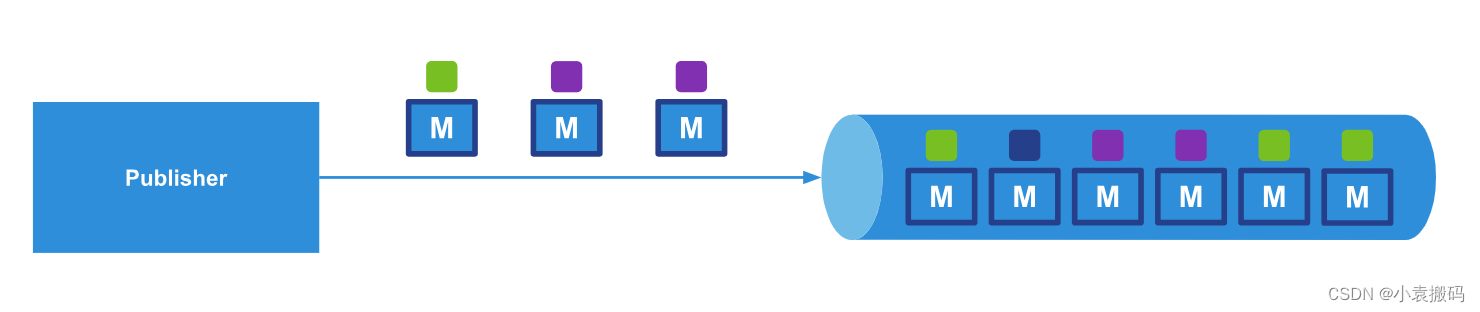
在上图中,发布者发布了 1 条(绿色)消息和 2 条(紫色)消息,这些消息将添加到流中。AMER``EMEA
2. 消息消费
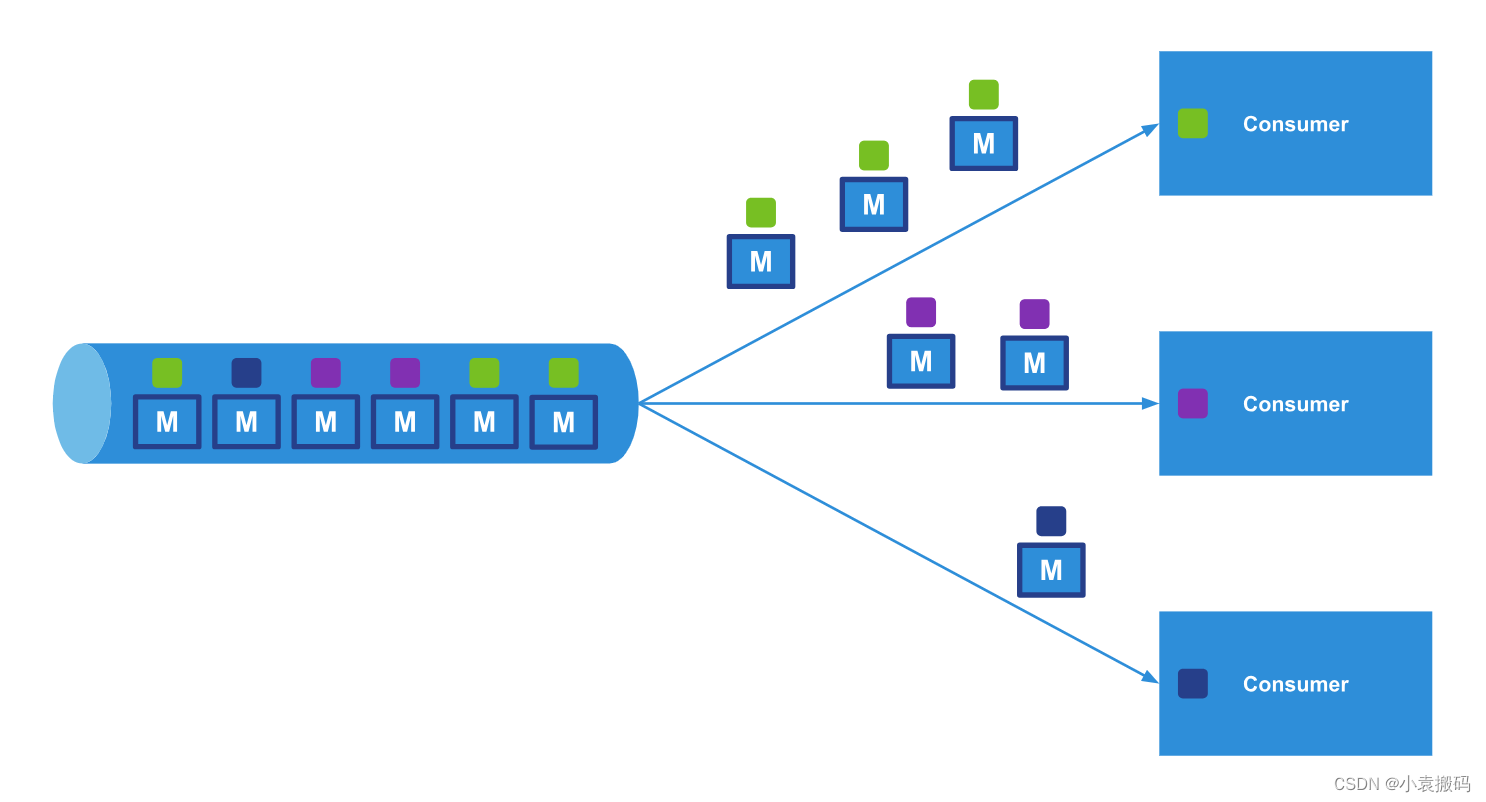
当使用者订阅时,它可以指定一个或多个过滤器值,并且代理应仅发送具有此或这些过滤器值的消息。 我们很快就会看到这在实践中有点不同,但这足以理解这些概念。
在下图中,顶部的使用者指定它只想要(绿色)消息,而代理只发送这些消息。 中间的消费者和底部的消费者也是如此。AMER``EMEA``APAC
概念就到这里了,现在让我们来了解一下实现细节。
2. 流的结构
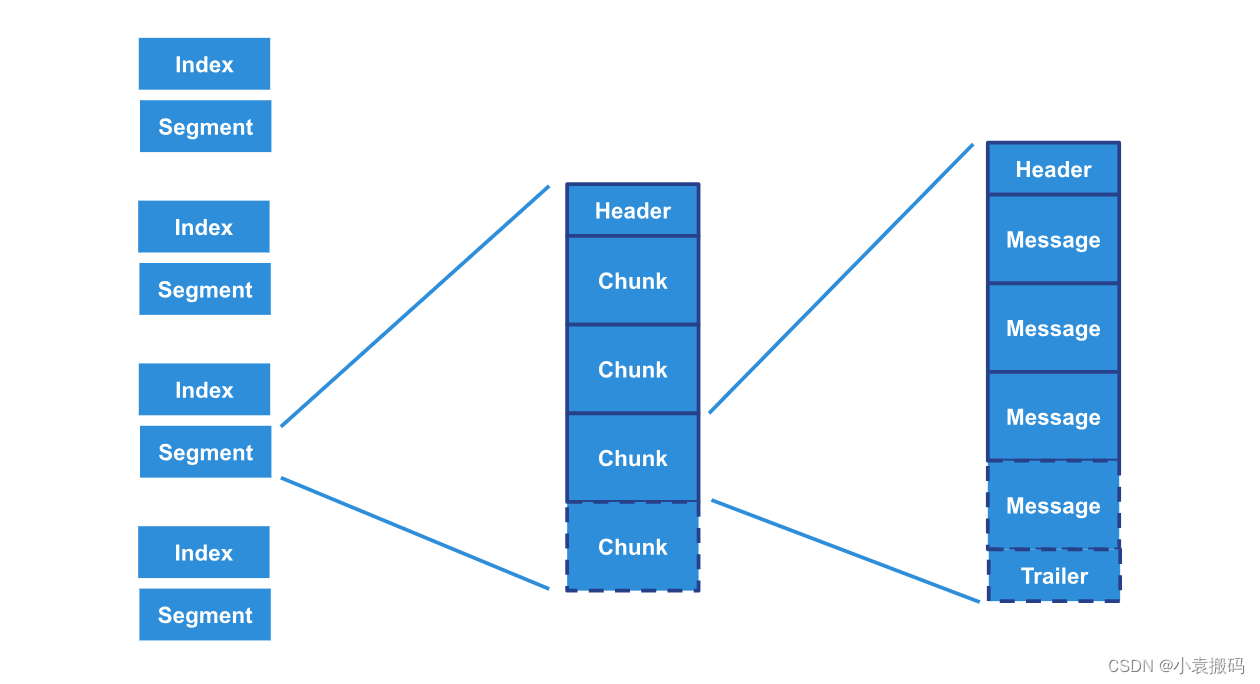
我们需要知道流是如何构建的,以便了解流过滤的内部结构。 流是包含段文件的目录。 每个区段文件都有一个关联的索引文件(用于了解在区段文件中给定偏移量处附加使用者的位置等)。 拥有多个“小”段文件比为整个流拥有一个大的整体文件要好:例如,删除“旧”段文件以截断流比删除大文件的开头更有效、更安全。
区段文件由包含消息的块组成。 区块中的消息数取决于入口速率(高入口速率表示一个块中的消息较多,低入口速率表示块中的消息较少)。 块中的消息数量从几条(甚至 1 条)到几千条不等。
块是怎么回事? 块是流中的工作单元:它们用于复制,更重要的是,对于我们的主题,用于消费者交付。 代理使用 sendfile 系统调用(将整个块从文件系统发送到网络套接字,而不将数据复制到用户空间)向使用者发送块,一次一个。
下图说明了流的结构:
有了这个,让我们看看代理如何知道是否要调度一个区块。
1. 在代理端进行过滤
想象一下,我们有一个只想要(绿色)消息的消费者。 当代理要调度一个区块时,它需要知道该区块是否包含消息。 如果是这样,它可以将块发送给消费者,如果没有,代理可以跳过该块,转到下一个块,然后重新迭代。AMER``AMER
每个区块都有一个标头,该标头可以包含一个 Bloom 过滤器,该标头告诉代理该块是否包含具有给定过滤器值的消息。 Bloom 过滤器是一种节省空间的概率数据结构,用于测试元素是否是集合的成员。 在我们的示例中,集合包含 、 和 ,元素是 。AMER``EMEA``APAC``AMER
下图说明了 3 个块的代理端过滤过程:
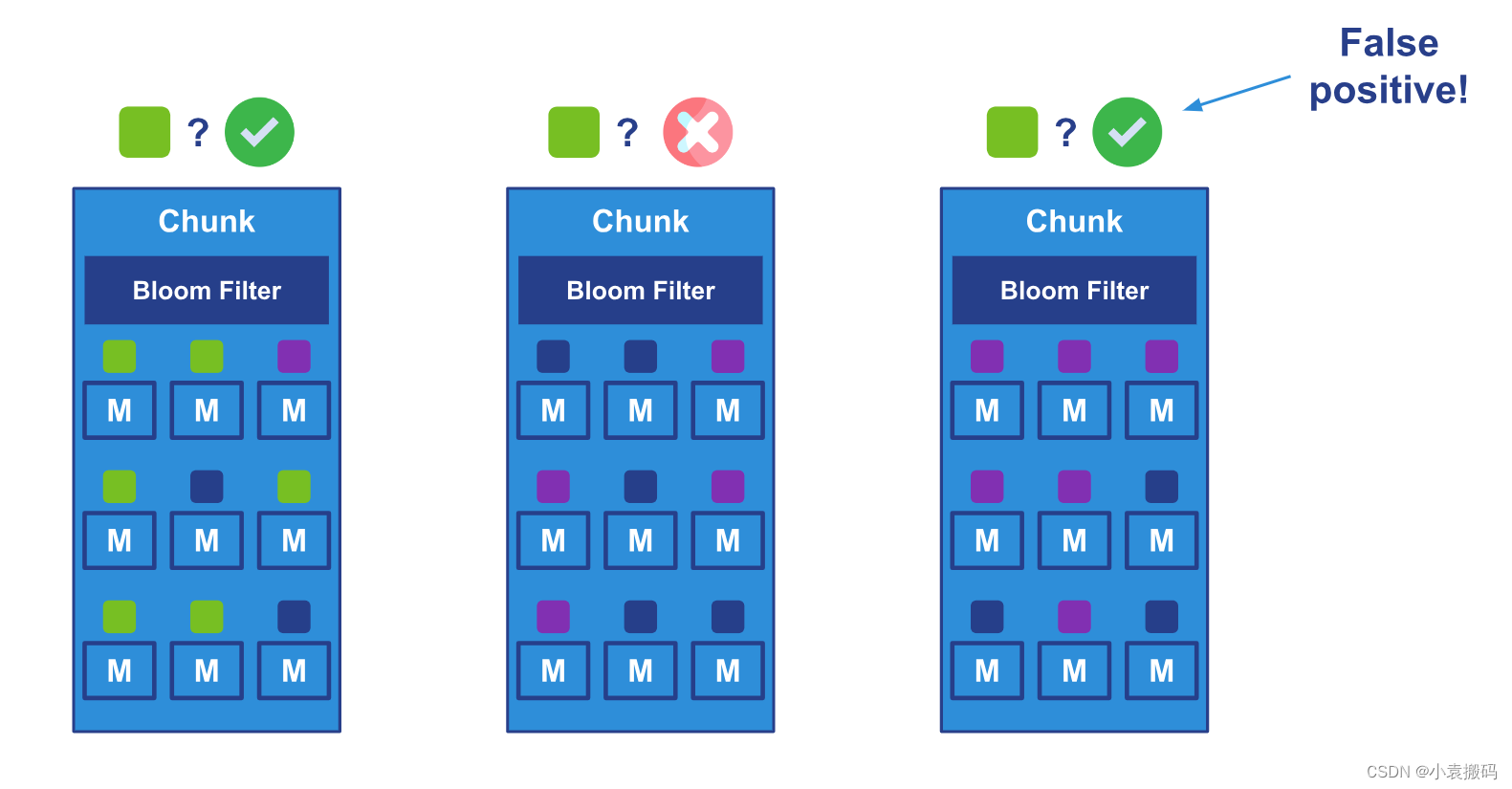
如上图所示,筛选器可能会返回误报,即不包含具有预期筛选器值的消息的块。 这是正常的,因为 Bloom 过滤器是概率性的。 不过,它们不会返回假阴性:如果过滤器显示没有(绿色)消息,我们可以确定它是真的。 我们必须忍受这种不确定性:有时我们可能会无缘无故地调度一些块,但这总比调度所有块要好。AMER
可以肯定的是,消费者可以接收到它不想要的消息:看看我们左边的第一个块,它包含消费者要求的(绿色)消息,但也包含(紫色)和(深蓝色)消息。 这就是为什么客户端也必须进行过滤的原因。AMER``EMEA``APAC
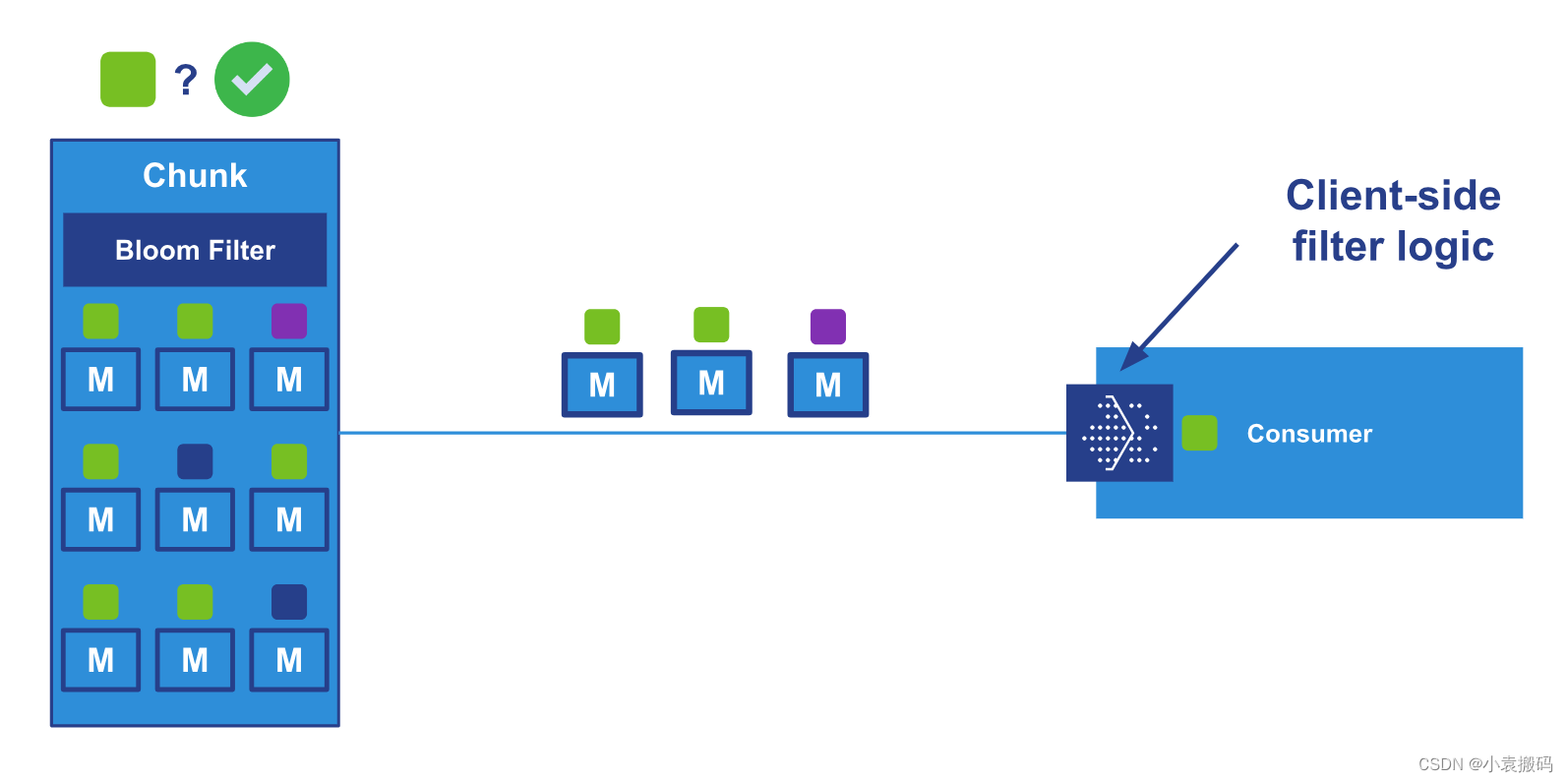
2. 客户端筛选
代理在传递消息时处理第一级过滤,但由于传递单位是块,因此使用者仍然可以接收它不想要的消息。 因此,客户端还必须执行一些筛选,这显然必须与订阅时设置的筛选值一致。
下图说明了一个消费者,它只需要(绿色)消息,并且必须执行最后一步的筛选:AMER
让我们看看这如何转化为应用程序代码。
3. JavaAPI示例
筛选不是侵入性的,可以作为跨领域问题进行处理,从而最大限度地减少对应用程序代码的影响。 以下是在使用流 Java 客户端(方法)声明生产者时设置从消息中提取过滤器值的逻辑:filterValue(Function<Message,String>)
Producer producer = environment.producerBuilder().stream("invoices").filterValue(msg -> msg.getApplicationProperties().get("region").toString()) .build();
在消费端,流 Java 客户端提供了设置过滤器值的方法和设置客户端过滤逻辑的方法。 声明使用者时,必须调用这两种方法:filter().values(String... filterValues)``filter().postFilter(Predicate<Message> filter)
Consumer consumer = environment.consumerBuilder().stream("invoices").filter().values("AMER") .postFilter(msg -> "AMER".equals(msg.getApplicationProperties().get("region"))) .builder().messageHandler((ctx, msg) -> {// message processing code}).build();
如您所见,筛选不会更改发布和使用代码,而只是更改生产者和使用者的声明。
现在让我们看看如何以最合适的方式为用例配置流过滤。
4. 流过滤配置
关于流过滤的第一篇文章提供了一些数字(与不过滤相比,过滤节省了大约 80% 的带宽)。 流过滤的好处很大程度上取决于用例:入口速率、基数和过滤器值的分布,以及过滤器大小。 过滤器越大越好(错误率越小)。 可以为块中使用的筛选器大小设置一个介于 16 到 255 字节之间的值,默认值为 16 字节。
流 Java 客户端提供了在创建流时设置过滤器大小的方法(它在内部设置参数):filterSize(int)``stream-filter-size-bytes
environment.streamCreator().stream("invoices").filterSize(32).create()
如何估算过滤器的尺寸? 网上有许多 Bloom 滤镜计算器。 参数包括哈希函数的数量(RabbitMQ 流过滤为 2 个)、预期元素的数量、错误率和大小。 您通常对元素的数量有所了解,因此您需要在错误率和过滤器大小之间找到权衡。
以下是一些示例:
- 10 个值,16 个字节 => 2 % 错误率
- 30 个值,16 个字节 => 14 % 错误率
- 200 个值,128 个字节 => 10 % 的错误率
那么,过滤器越大越好? 不完全是:尽管 Bloom 过滤器在存储方面非常有效,因为它不存储元素,只是元素是否在集合中,过滤器大小是预先分配的。 如果将筛选器大小设置为 255,并且每个块至少包含一条具有筛选器值的消息,则每个块标头中将分配 255 个字节。 如果块包含许多大消息,这很好,因为与块大小相比,筛选器大小可以忽略不计。 但是,对于退化的情况,例如具有 10 字节消息和 10 字节筛选器值的单消息块,您最终会得到一个比实际数据更大的筛选器。
您必须尝试自己的用例,以估计过滤器大小对流大小的影响。 关于流过滤的第一篇文章提供了一个使用 Stream PerfTest 估计流大小的技巧(在不过滤的情况下读取整个流并查阅指标)。rabbitmq_stream_read_bytes_total
5. AMQP上的流过滤
尽管访问流的首选方式是流协议,但支持其他协议,例如 AMQP。 任何 AMQP 客户端库也支持流筛选:
- 声明:将参数设置为 并使用 在声明流时设置筛选器大小。
x-queue-type``stream``x-stream-filter-size-bytes - 发布:使用标头设置出站邮件的筛选器值。
x-stream-filter-value - 使用:使用 consumer 参数设置预期的筛选器值(字符串或字符串数组),并使用 consumer 参数(可选)接收没有任何筛选值的消息(默认值为 )。客户端过滤仍然是必要的!
x-stream-filter``x-stream-match-unfiltered``false
6. 总结
流过滤易于使用并从中受益,但有关内部的一些知识可用于优化其使用,尤其是对于棘手的用例。 请记住,客户端筛选是必需的,并且必须与配置的筛选器值一致。 这通常很容易实现。 还可以为给定的用例以最合适的方式设置过滤器大小。
3. 相关链接
参考:
Stream Filtering Internals | RabbitMQ
这篇关于RabbitMQ3.13.x之十_流过滤的内部结构设计与实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





