本文主要是介绍f2fs nat/sit area存储格式及current_nat_addr,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
f2fs为了保护元数据的有效性及可恢复性,每个无数据区域均包含两个复本,如两个super block, 两个check point segments, 对于nat及sit area,同样也包含两份。
对于nat area的存储方式,一直以来,都以为是先存一份,再存储另一份,类似于这种结构:

所以,对于current_nat_addr函数,一直无法理解代码实现的原理是什么。
今天偶然看了一篇博文,“f2fs系列文章——sit/nat_version_bitmap”,https://blog.csdn.net/WaterWin/article/details/79901440,里面描述了nat及sit area的存储格式,才对nat area的存储格式,及current_nat_addr函数有了一个真正的理解。

实际上,nat area存储方式是按照上图样式的,即每个segment与它的复本并列排列,后成紧跟它的复本,有了这个意识后,就可以比较容易的理解current_nat_addr函数了。
static inline pgoff_t current_nat_addr(struct f2fs_sb_info *sbi, nid_t start)
{struct f2fs_nm_info *nm_i = NM_I(sbi);pgoff_t block_off;pgoff_t block_addr;/** block_off = segment_off * 512 + off_in_segment* OLD = (segment_off * 512) * 2 + off_in_segment* NEW = 2 * (segment_off * 512 + off_in_segment) - off_in_segment*/block_off = NAT_BLOCK_OFFSET(start);block_addr = (pgoff_t)(nm_i->nat_blkaddr +(block_off << 1) -(block_off & (sbi->blocks_per_seg - 1)));if (f2fs_test_bit(block_off, nm_i->nat_bitmap))block_addr += sbi->blocks_per_seg;return block_addr;
}
大致的思路就是,先得到segment_off, segment_off*512得到block_off, block_off*2, 这个block_off*2得到的就是包含复本在内的,实际上是2倍的block_off,最后再加上1个off_in_segment,得到最终的nat block addr。 后面会举一个具体的例子说明。
再看一下sit area的磁盘布局格式:
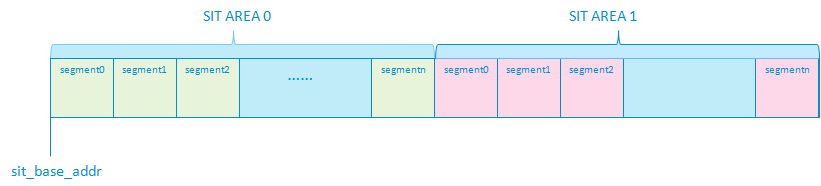
SIT area 与NAT area磁盘格式不同,它的两个区域是并列存储的,了解了这个布局方式后,就能够对sit area的地址操作有很好的理解。
这篇关于f2fs nat/sit area存储格式及current_nat_addr的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




