本文主要是介绍【Java核心能力】饿了么一面:Redis 面试连环炮,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
饿了么一面:Redis 面试连环炮
Redis用过吗,和本地缓存有啥区别?
Redis 是 分布式缓存 ,本地缓存是 单机缓存 ,那么在分布式系统中,如果将数据放在本地缓存中,其他节点肯定是无法进行访问了
其次就是 本地缓存相对于 Redis 缓存来说会更快 ,因为去 Redis 中查询数据虽然 Redis 基于内存操作比较快,但是应用还需要和 Redis 发起网络 IO ,而使用本地缓存就不需要网络 IO 了,因此本地缓存更快
Redis 的数据结构
Redis 有 5 种 基本数据结构 :String、List、Hash、Set(无序集合、值唯一)、Zset(有序集合)
我们都知道 Redis 速度是比较快的,因为他是基于 内存 操作,并且利用 IO 多路复用 来提升处理客户端连接上请求的速度,使用 单线程 处理客户端请求,速度很快
其次呢,Redis 对基本数据结构也做了许多优化 :
- String 底层的 SDS 数据结构优化
字符串底层封装了 SDS 数据结构来实现,没有使用 C 语言默认的字符数组来实现,SDS 内部直接 存储了字符串的长度 len ,因此获取长度的时间复杂度为 O(1),而 C 语言字符串获取长度需要遍历字符串,时间复杂度为 O(N),并且 C 语言以 \0 表示字符串结尾,因此无法存储二进制数据,SDS 中记录字符串长度就不需要结尾标识符了,因此 可以存储二进制数据
SDS 中还采用了 空间预分配策略 ,在 SDS 进行空间扩展时,会同时分配 所需空间 和 额外的未使用空间 ,以减少内存再分配次数
- listPack 优化
Redis 7.0 之后,zipList 被废弃,转而使用 listPack 来代替,因为 zipList 中存在 级联更新 的问题:
假如 zipList 中每一个 entry 都是很接近但又不到 254B,此时每个 entry 的 prevlength 使用 1 个字节就可以保存上个节点的长度,但是此时如果向 zipList 中间插入一个新的节点,长度大于 254B,那么新插入节点后边的节点需要把 prevlength 扩展为 5B 来存储新插入节点的长度,那么扩展后该节点长度又大于 254B,因此后边节点需要再次扩展 prevlength 来存储该节点的长度,导致了插入节点后边的所有节点都需要更新 prevlength 的值,这属于是极端情况下才会发生
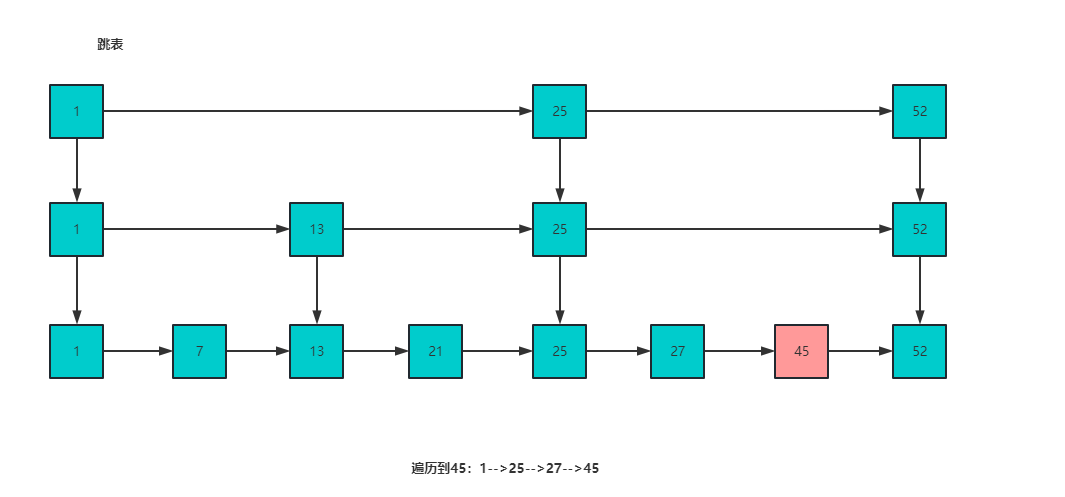
- 跳表优化
并且使用 跳表 来优化 Zset 的性能,Zset 底层是通过 压缩列表 + 跳表 来实现的,跳表可以支持平均时间复杂度为 O(logN) 的查询操作
Redis的持久化机制
Redis 持久化机制有 AOF、RDB 和 混合持久化三种方式,这就是常规八股文了
要知道这三种持久化方式的区别:
使用 RDB 会进行全量备份,RDB 持久化文件时压缩后的二进制文件,因此加载 RDB 文件的速度是远超 AOF 的,不过缺点就是持久化不及时,可能丢失数据
RDB 持久化有两种方式 save 和 bgsave,save 会导致 Redis 阻塞,bgsave 会利用子进程对数据进行持久化,利用到了 写时复制技术 ,写时复制的优点就是利用单独子进程持久化,不会阻塞
AOF 会进行实时备份,AOF 文件中存储的是 RESP 协议数据格式,会存储 Redis 执行的每一条命令,因此实时性比较强,缺点就是速度比较慢(因为需要将命令刷入磁盘中),AOF 肯定不会对每一条命令都写入到磁盘中,而是会先写入到内存中,再统一刷入到磁盘中,刷盘策略分为三种:always(每条命令都立即刷入磁盘)、everysec( 默认 ,每秒同步一次)、no(Redis 不调用文件同步,而是交给操作系统自己判断同步时机)
AOF 文件过大的话,会进行 重写(Rewrite) 压缩体积,使用重写之后,就会将最新数据记录到 AOF 文件中,比如之前对于 name 属性设置了好多次,AOF 文件中记录了 set name n1,set name n2 …,那么在 重写 之后,AOF 文件中就直接记录了 set name nn,nn 就是 name 的最新值,通过这样来减小 AOF 文件体积是
混合持久化 (Redis4.0 提出)的话,结合了 RDB 和 AOF,既保证了 Redis 性能,又降低了数据丢失的风险,缺点就是 AOF 文件中包含了 RDB 格式的数据,可读性较差
Redis的内存如果满了,会发生什么?
Redis 的内存如果达到阈值,就会触发 内存淘汰机制 来选择一些数据进行淘汰,如果淘汰之后还没有内存的话,就会返回写操作 error 提示(Redis 内存阈值通过 redis.conf 的 maxmemory 参数来设置)
Redis 中提供了 8 种内存淘汰策略:
-
noeviction (默认策略):不删除键,返回错误 OOM ,只能读取不能写入
-
volatile-lru :针对设置了过期时间的 key,使用 LRU 算法进行淘汰
-
allkeys-lru :针对所有 key 使用 LRU 算法进行淘汰
-
volatile-lfu :针对设置了过期时间的 key,使用 LFU 算法进行淘汰
-
allkeys-lfu :针对所有 key 使用LFU 算法进行淘汰
-
volatile-random :从设置了过期时间的 key 中随机删除
-
allkeys-random : 从所有 key 中随机删除
-
volatile-ttl :删除生存时间最近的一个键
Redis如何实现事务?
Redis 自身提供了 事务功能 ,但是并没有 回滚机制 ,Redis 的事务可以顺序执行队列中的命令,保证其他客户端提交的命令不会插入到事务执行的命令序列中
Redis 提供了 MULTI、EXEC、DISCARD 和 WATCH 这些命令来支持事务
Redis 事务的缺点:
- 不保证原子性: 事务执行过程中,如果所有命令入队时未报错,但是在事务提交之后,在执行的时候报错了,此时正确的命令仍然可以正常执行,因此 Redis 事务在该情况下不保证原子性
- 事务中的每个命令都需要与 Redis 进行网络通信
因此 Redis 自身的事务使用的比较少,而是更多的使用 Lua 脚本 来保证命令执行原子性,使用 Lua 脚本的 好处 :
- 减少网络开销: 多个请求以脚本的形式通过一次网络 IO 即可发送到 Redis
- 原子操作: Redis 会原子性执行整个 Lua 脚本
- 复用: 客户端的 Lua 脚本会永久存在Redis,之后可以复用
这里 Redis Lua 脚本的原子性指的是保证在执行 Lua 脚本的时候,不会被其他操作打断,从而保证了原子性,但是在 Lua 脚本中如果发生了异常,异常前的命令还是会被正常执行,并且无法进行回滚, 因此要注意 Lua 中保证的原子性是指在 Lua 脚本执行过程中不会被其他操作打断
Lua 脚本在执行过程中不会被打断,因此注意不要在 Lua 脚本中执行比较耗时的操作,导致 Redis 阻塞时间过长!
接下来还问了有 Redis 如何实现滑动窗口限流、常见的限流算法、漏桶和令牌桶限流有什么区别、如何进行选择,这一块限流的内容放在下一篇文章说明!
这篇关于【Java核心能力】饿了么一面:Redis 面试连环炮的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





