本文主要是介绍【读书笔记】关于栈帧结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0、问题的引出
要理解格式化字符串漏洞的原理与利用,必须对栈帧结构有比较清晰的了解。复习了下汇编,同时发现《软件安全测试艺术》一书中图12-1的描述竟然有误。
1、栈的特点
栈(Stack)是由操作系统管理的一段连续的内存区域,从栈底到栈顶。在X86架构中,栈是向下生长的地址是不断减小的,每次减少4个字节,也就是32位。
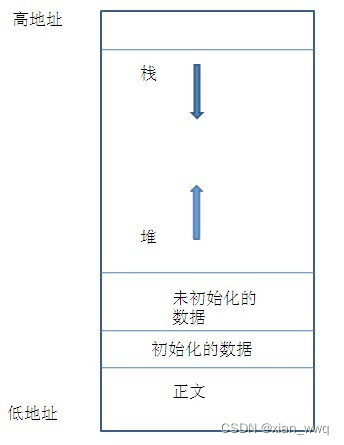
栈用于存储函数调用和返回的过程中的临时数据。在函数调用时,程序会将函数的参数和返回地址压入栈中,然后跳转到函数的入口地址执行函数代码。在函数返回时,程序会从栈中弹出返回地址和临时数据,然后跳转到返回地址执行函数调用后的代码。
在汇编编程中,涉及到函数调用时,会用到EBP和ESP这两个特殊的寄存器。
EBP:基址指针寄存器(extended base pointer),其内存放着一个指针(帧指针),该指针永远指向系统栈最上面一个栈帧的底部。所以ebp指向的是栈的栈底的数据。
ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针(栈指针),该指针永远指向系统栈最上面一个栈帧的栈顶。所以esp指向的是栈的栈顶的数据。
小结下栈的特性:
1、先进后出。
2、在内存中表现为从高地址往低地址增长。
3、栈底:栈的最下方(高地址区),寄存器ebp指向当前的栈帧的底部(高地址)
4、栈顶:栈的最上方(低地址区),寄存器esp指向当前的栈帧的顶部(低址地)
2、栈帧空间的内部顺序
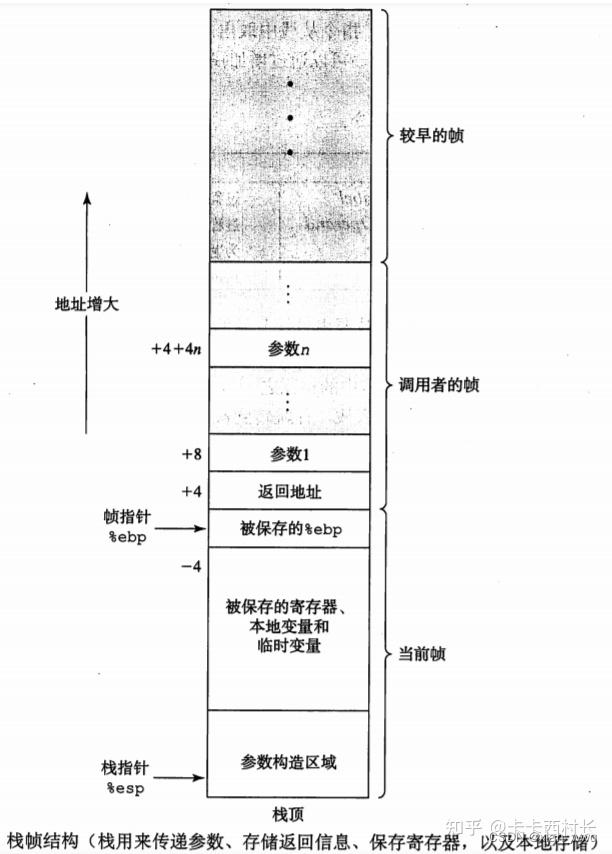
函数的栈变量通常按照以下顺序存储:
1)函数参数:函数参数按照从右到左的顺序入栈,即最后一个参数先入栈,第一个参数最后入栈。
2)返回地址:返回地址会被存储在栈中,以便函数执行完毕后能够返回到调用该函数的地址。简单理解就是函数调用处的下一条语句(图中的L)。

3)局部变量:局部变量在函数调用时会按照它们在函数中定义的顺序依次入栈。
4)其他上下文信息:在一些情况下,还会保存一些其他上下文信息,如函数调用前后的寄存器状态等。
看示例代码:
#include <stdio.h>int main()
{int a = 10;printf("The value of a is %d\n", a);return 0;
}在main()中调用printf(“The value of a is %d\n”,10)函数时,栈帧是这样的:
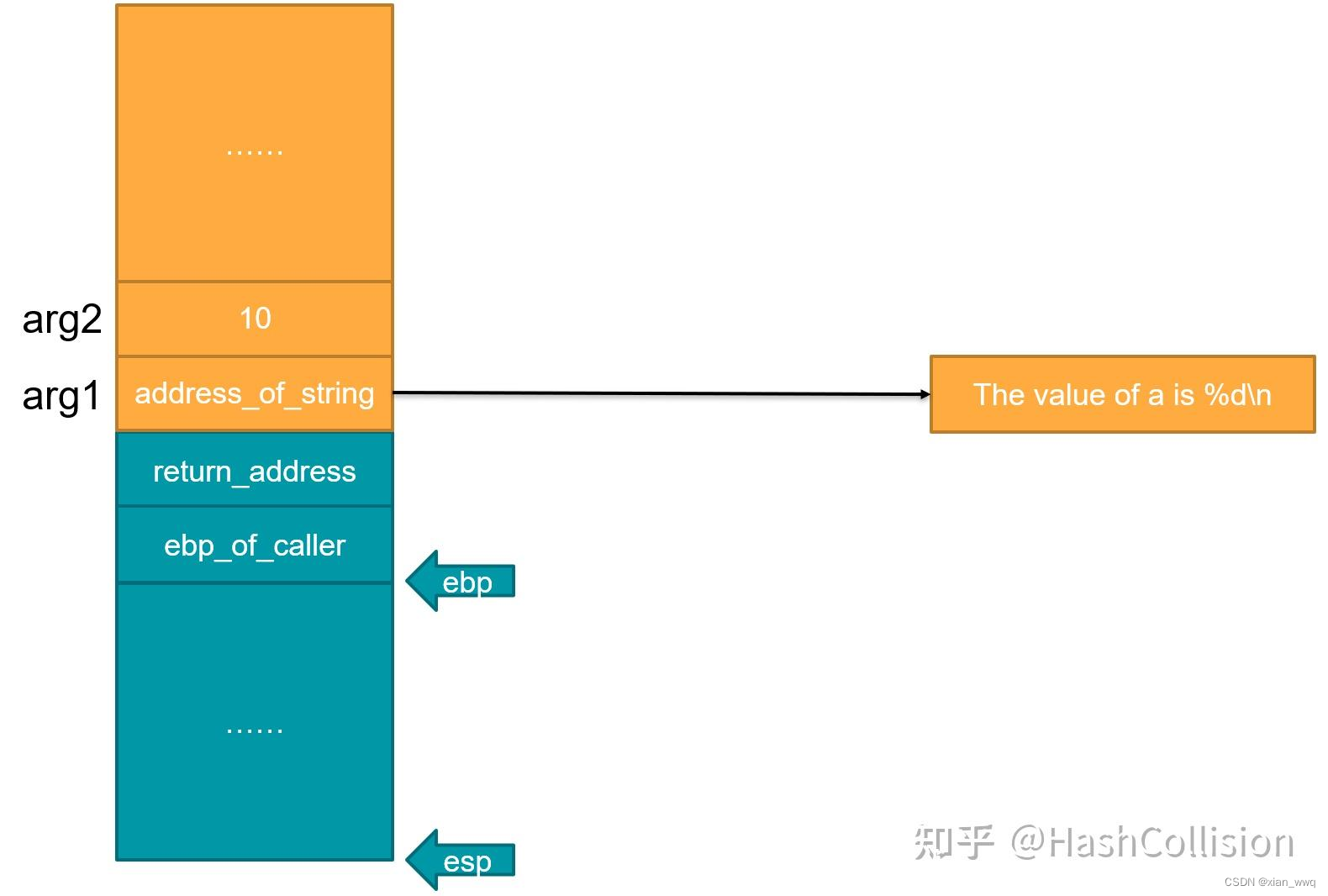
如上图所示,当printf希望访问实参时,按照C语言函数调用栈的规则,父函数会将实参倒序压入栈中,并且第一个参数与子函数的return_address相邻。
因此printf知道第一个实参(此处第一个实参为字符串"The value of a is %d\n"的地址)位于:ebp + 2 * sizeof(word);同理,第二个实参(此处第二个实参为整数10)位于:ebp + 3 * sizeof(word)。
将printf("The value of a is %d\n", a)改为printf("The value of a is %d\n")会发生什么呢?
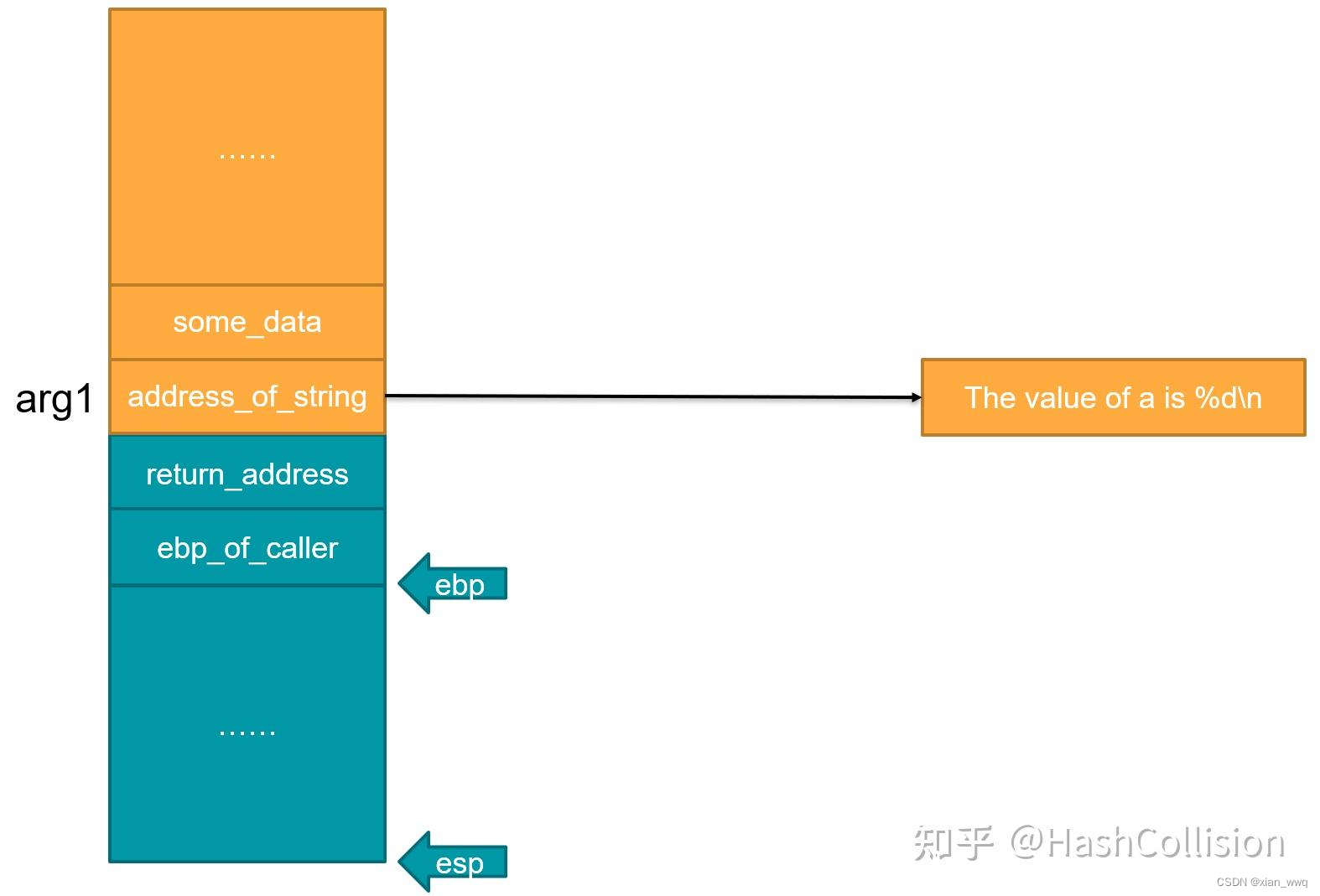
由于没有提供第二个参数a,因此父函数只将第一个参数压入了栈中,而其上方则是其他数据。可printf并不知道这件事,它仍然以为调用它的父函数会按照约定将需要的参数全部压入栈中。因此,当printf希望访问第二个参数时,程序认为首地址为ebp + 3 * sizeof(word)的字是第二个参数。这时,它输出的数据就是栈上的其他数据。
3、相关寄存器变化
EIP存储着下一条指令的地址,每执行一条指令,该寄存器变化一次。
EBP存储着当前函数栈底的地址,栈低通常作为基址,我们可以通过栈底地址和偏移相加减来获取变量地址。
ESP始终指向栈顶,只要ESP指向变了,那么当前栈顶就变了。
一组图例来看下寄存器的变化:
1)初始状态,EBP寄存器中存储的值是0xDFF80,ESP寄存器中存储的值是0xDFF74。这里的两个16进制值,都是指内存中的具体地址,单位是字节(Byte)。
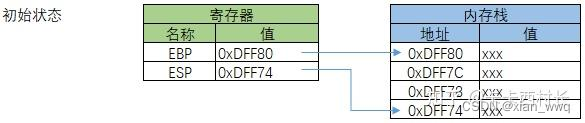
2)第1步,执行指令:PUSH EBP
把当前EBP寄存器中的值(0xDFF80)压入到栈中,同时ESP寄存器的值自动减小4个字节,从0xDFF74变为0xDFF70。地址0xDFF70中保存的值是0xDFF80。
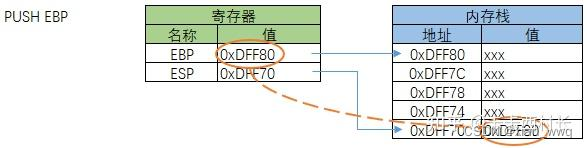
3)第2步,执行指令:MOV EBP, ESP
把ESP寄存器的值复制到EBP寄存器中,此时EBP和ESP的值都是0xDFF70。

接下来,用两个PUSH操作来模拟压入两个参数。
4)第3步,执行指令:PUSH 0x1
把16进制表示的整数1,压入栈中。此时,ESP寄存器的值自动减少4个字节,从0xDFF70变为0xDFF6C。EBP寄存器的值没有任何改变,仍然是0xDFF70。

5)第4步,执行指令:PUSH 0x2
把16进制表示的整数2,压入栈中。此时,ESP寄存器的值再次自动减少4个字节,从0xDFF6C变为0xDFF68。EBP寄存器的值没有任何改变,仍然是0xDFF70。

接下来,通过MOV和POP指令恢复到原来的栈状态。
6)第5步,执行指令:MOV ESP, EBP
把EBP寄存器中的值复制到ESP寄存器中,此时EBP和ESP的值都是0xDFF70。

7)第6步,执行指令:POP EBP
执行该POP之前,EBP寄存器的值是0xDFF70,该地址中存的值是0xDFF80。这里的POP EBP操作就是把0xDFF80这个值从栈中弹出来,写入到EBP寄存器中,同时,ESP寄存器自动增加4个字节,从0xDFF70变为0xDFF74。

至此,EBP和ESP两个寄存器的值都恢复到了最初的状态,EBP存的是0xDFF80,ESP存的是0xDFF74。
4、函数调用前后的变化
函数调用前后基本EIP、EBP、ESP基本变化流程如下:
1)调用函数中push ebp,将main函数的ebp压栈,然后mov ebp, esp将当前函数的esp赋给ebp,得到当前函数的栈底地址。
2)调用函数结束之前,执行leave指令,其实该指令等于下面两条指令:
mov esp, ebppop ebp此时fun相关数据全部被出栈,ebp将得重新到main函数的栈底地址,注意在执行ret指令时,将获取站内EIP数据,然后栈内的EIP也将出栈。程序跳转到函数下方。esp回到函数栈顶部,函数调用结束。
3)继续执行main函数后续其他指令。
5、格式化字符串漏洞利用
为了方便表述,约定:在printf("%d %d %d", a, b, c)中,a、b、c被称为格式化参数,其中a是第1个格式化参数,b是第2个格式化参数,c是第三个格式化参数;而字符串"%d %d %d"则是printf的第1个参数。
1)获取栈上的数据
获取栈上的数据是格式化字符串漏洞利用最简单的方式。
正如在讲解原理时介绍到的,依据C语言函数调用栈的规则,printf会默认:首地址为ebp + (2 + n) * sizeof(word)的字是第n个格式化参数。
也就是说,遇到字符串中的第n个占位符(如%d、%c、%p等)时,printf获取首地址为ebp + (2 + n) * sizeof(word)的字作为参数。
那如果想获取首地址为ebp + 102 * sizeof(word)的字的值,是否意味着我们需要在字符串中写上100个占位符呢?这当然是不必要的。我们可以使用100$作为标记,告诉printf此处的占位符需要的参数是第100个格式化参数。如%100$d、%100$c、%100$p等。
2)获取任意地址的数据
在说明如何利用格式化字符串漏洞获取任意地址数据前,我们先来看printf("%s", str)是如何工作的。
printf发现字符串中的%s后,会将对应的参数视为目标字符串的地址,并去该地址获取字符串。也就是说,str并非字符串本身,而是字符串的首地址。
如果栈上本身就有目标信息的地址,我们就可以直接利用%s获取该目标信息。可如果栈上没有该目标信息的地址,我们该如何构造呢?
要想获取任意地址的数据,我们需要先在栈上写入目标地址(有许多方法可以达到这一目的,需要根据题目的条件决定),随后将其作为%s的参数传入。这时,我们就能获取目标地址的数据。
3)向目标地址写入数据
此前我们都是利用漏洞获取程序中的数据,那我们能否向程序中写入数据呢?答案是肯定的。
向目标地址写入数据需要用到一个特殊的占位符%n。%n的功能是:将该占位符之前成功输出的字节数写入目标地址中。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>int main()
{int a;printf("0123456789%n\n", &a);printf("The value of a is %d", a);return 0;
}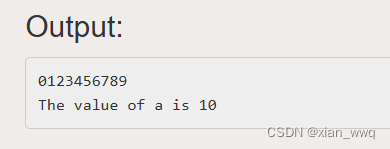
a的值被修改为了10。这是因为printf("0123456789%n\n", &a)中%n前已经成功输出了"0123456789"共计10个字节,因此%n便会将10写入目标地址中。可以看到,%n会将其对应的参数作为地址解析。因此只要我们向栈上写入目标地址,再使用%n即可向目标地址写入数据。
值得注意的是,若将上述代码改为:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>int main()
{int a;char b = 'b';printf("%20c%n", b, &a);printf("The value of a is %d", a);return 0;
}
这时a的值将变为20。这是因为%20c在字符b的左侧填充了19个空格,再加上b本身是一个字节,共计20个字节。也就是说当需要写入数据(假定为k + 1)特别大时,可以使用%kc%n代替。
意外收获,在线IDE,跑个测试代码很方便。
C Online Compiler - GeeksforGeeks
参考文献:
1.栈帧ebp,esp详解_压入ret后,继续压入当前ebp,然后用当前esp代替ebp-CSDN博客
2.函数栈&EIP、EBP、ESP寄存器的作用 | kTWO-个人博客 (k2zone.cn)
3.汇编语言--EBP和ESP - 知乎 (zhihu.com)
4.CTFer成长日记11:格式化字符串漏洞的原理与利用 - 知乎 (zhihu.com)
这篇关于【读书笔记】关于栈帧结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







