本文主要是介绍为什么0x100是256个字节、0x400是1KB、0x800是2KB、0x1000是4KB?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 数据单位标准
- 两种标准
- 0x400为什么是1KB大小?
- 回到开始的问题
- 附录1:存储单位之间的换算
- 附录2:常见的16进制地址及其对应容量
前言
在刚开始学习嵌入式时我们就遇到各种进制之间的换算,十六进制、十进制、八进制、二进制等等,一开始会经常在各种进制之间迷失自我;
在深入学习或者做项目或者工作时我们也经常要查看各种芯片的数据手册(datasheet),手册里面一般都是使用十六进制表示各种地址。
这时我们就会遇到类似这样的问题:
- 为什么 0x100 是 256Bytes(字节) 大小?
- 0x400 是 1KB 大小?
- 0x800是 2KB 大小?
下面我们就来解决这个疑惑!
数据单位标准
我们都知道数据单位有:bit、byte、word、KB、MB、GB、TB等等,他们之间的换算很简单,例如:
- 1TB=1024GB- 1GB=1024MB- 1MB=1024KB- 1KB=1024B(Byte)- 1B=8bit
从上面的换算我们可以不难理解下面的两个基本约定:
- bit(比特):bit是数据的最小单位,通常简写为b。在计算机中通常用1和0来表示。
- Byte(字节):数据存储的基本单位,通常简写为B。通常:1Byte=8bit。
但是这些都是谁规定的呢?我们得先要解决这个疑惑。
两种标准
目前,有两种比较流行的单位:一种为SI(International System of Units,国际单位制)制定的标准,采用十进制换算。例如:
1 MB = 106 bytes = 1 000 000 bytes = 1000 kilobyte
1024 MB = 1 gigabyte (GB)
其中kilo、giga等称为十进制前缀,通常简写为KB、GB等。
另一种则为IEC(International Electrotechnical Commission,国际电工委员会)于1998年2月制定的标准(IEC 60027-2),采用二进制换算。例如:
1 MiB = 2^20 bytes = 1 048 576 bytes = 1024 kibibytes
1024 MiB = 1 gibibyte (GiB)
其中kibi、gibi等称为二进制前缀,通常简写为KiB、GiB等。
下图是两种单位标准的wiki截图,摘自wiki:
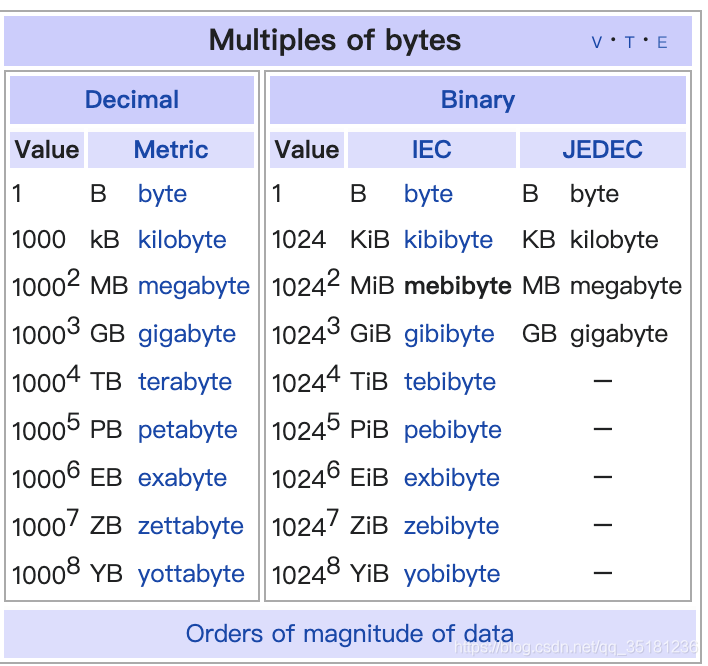
IEC制定的这个标准用于在一些更严格的场景下(希望使用二进制换算的情况)替换SI的标准,目前已为大多数组织所接受,像现在的许多Linux发行版也采用这种单位。
在本文中我们只关注我们常用到的 IEC 制定的标准,所有的讨论均是在 IEC 制定的 IEC 60027-2 标准基础上。
拓展阅读:
- https://en.wikipedia.org/wiki/Byte
- https://simple.wikipedia.org/wiki/Mebibyte
0x400为什么是1KB大小?
为了说这个问题,我们以 2440 的芯片手册为例,下面的图是 NAND闪存映射:
下面图引用自 S3C2440A_UserManual_Rev13.pdf :p222
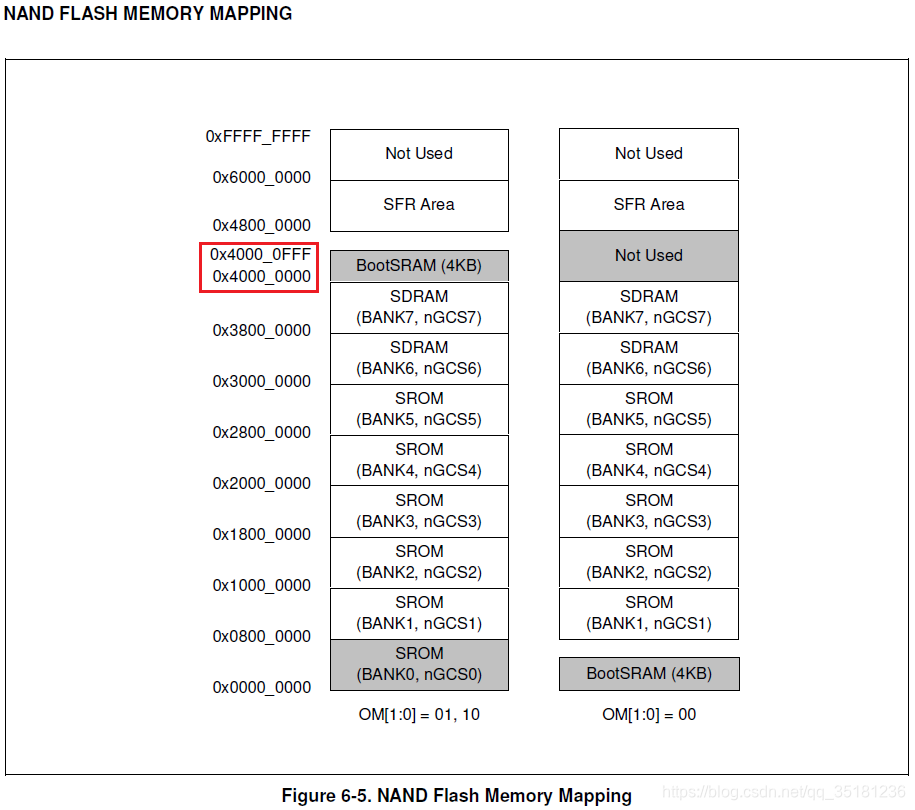
我们重点看 0x4000 0000 - 0x4000 0FFF 这段内存空间。图中说明这个4kb的空间是分配给BootSRAM,这个 4KB 结果的换算过程:
1. 0x4000 0FFF - 0x4000 0000 = 0x0000 0FFF
2. 0x0000 0FFF 的十进制是 4095 (Bytes)
3. (4095+1) / 1024 = 4 (KB)
为什么 0x0000 0FFF 的十进制是 4095 ,而且这就是代表 (4095+1) 个字节(也就是4KB)呢?下面我们一起来解开这个疑惑:
下图是2440的内存布局图 (0x0000 0000 - 0xFFFF FFFF)。
2440的CPU是32bit的,地址总线一共有 32(2^5) 根,可以索引的地址范围是0 - 2^32 (0x0000 0000 - 0xFFFF FFFF) ,也就是 4GB 的空间。
那么这个 4GB 是怎么得来的呢?
下面的图已经给出了很直观的答案了,2440的CPU是 32 位的,所以表示的范围是:
从
0000 0000 0000 0000 0000 0000 0000 0000 (0x0000 0000)
到
1111 1111 1111 1111 1111 1111 1111 1111 (0xFFFF FFFF)
一个字节有8位,从下面的图可知,一共有 0xFFFF FFFF 个字节,也就是 4,294,967,295 个字节( 0xFFFF FFFF 转换后的十进制),所以大小为:4,294,967,295 Bytes = 4,194,305KB = 4095MB
但是这里为什么不是 4096 呢?因为我们计算的范围是 0x0000 0000 - 0xFFFF FFFF ) ,并没有算第1个字节(Byte),所以上面的应该是一共有 0xFFFF FFFF+1 个字节,也就是:4,294,967,296 Bytes = 4,194,306KB = 4096MB = 4GB
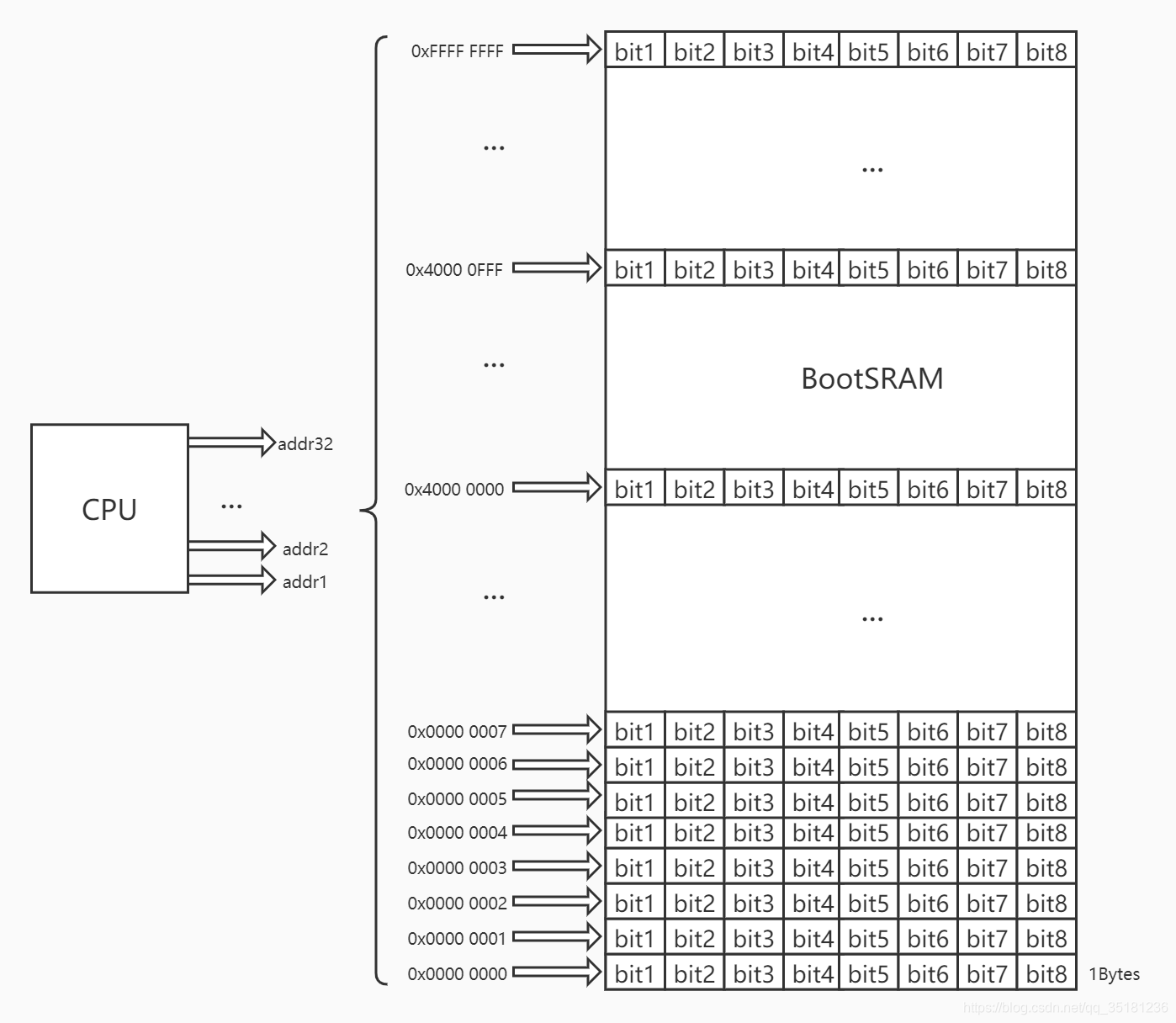
上面的案例基于 2400,其他芯片也是一样的思路分析即可。不管他是8位、16位、32位还是64位,我们只要知道他们的能表示的最大范围即可
回到开始的问题
到这里我们就能理解为什么在 2440的芯片手册中,分配给BootSRAM的 0x4000 0000 - 0x4000 0FFF 是 4KB 大小了 。
那么我们来解决一开始提出的问题: 为什么0x400是1KB大小?
0x400转换的十进制为:1024,也就是有 1024 个字节(Byte),
1KB的换算过程:1024(Byte)/1024=1kb。
用这种思路我们就可以理解为什么, 0x100 是 256 个字节(Bytes)、0x800是 4096 个字节(Bytes)也就是 4KB。
附录1:存储单位之间的换算
| 1 Byte(B) | 8 bit |
| 1 Kilo Byte(KB) | 1024B |
| 1 Mega Byte(MB) | 1024 KB |
| 1 Giga Byte (GB) | 1024 MB |
| 1 Tera Byte(TB) | 1024 GB |
| 1 Peta Byte(PB) | 1024 TB |
| 1 Exa Byte(EB) | 1024 PB |
| 1 Zetta Byte(ZB) | 1024 EB |
| 1Yotta Byte(YB) | 1024 ZB |
| 1 Bronto Byte(BB) | 1024 YB |
| 1Nona Byte(NB) | 1024 BB |
| 1 Dogga Byte(DB) | 1024 NB |
| 1 Corydon Byte(CB) | 1024DB |
| 1 Xero Byte (XB) | 1024CB |
附录2:常见的16进制地址及其对应容量
| 十六进制 | 大小 |
|---|---|
| 0x100 | 256B |
| 0x200 | 512B |
| 0x400 | 1KB |
| 0x800 | 2KB |
| 0xC00 | 3KB |
| 0x1000 | 4KB |
| 0x2000 | 8KB |
| 0xF000 | 60KB |
| 0x1 0000 | 64KB |
| 0x2 0000 | 128KB |
| 0xF 0000 | 960KB |
| 0x10 0000 | 1MB |
| 0x20 0000 | 2MB |
| 0xF0 0000 | 15MB |
| 0x0100 0000 | 16MB |
| 0x0200 0000 | 32MB |
| 0x0F00 0000 | 240MB |
| 0x1000 0000 | 256MB |
这篇关于为什么0x100是256个字节、0x400是1KB、0x800是2KB、0x1000是4KB?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







