本文主要是介绍Redis类型 Stream Bitfield,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Stream 类型
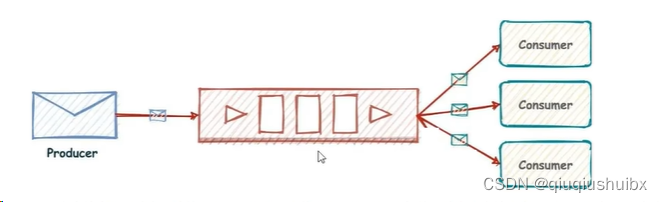
Stream类型就是Redis里的mq,是redis为了占领市场份额的产物
今天我们就来介绍一下Stream
Redis的消息队列一般是两个方案
第一个是Lpush Rpop 队列的异步队列方案(一对一)
第二个方案就是pubsub(发布订阅)模式 (一对多)
注:这里如果没有消费者了,队列中的数据就直接被丢弃了,没有持久化
Redis Stream是在Redis5引入的,支持消息持久化,全局自动生成唯一id,支持消息ack等等
底层数据结构
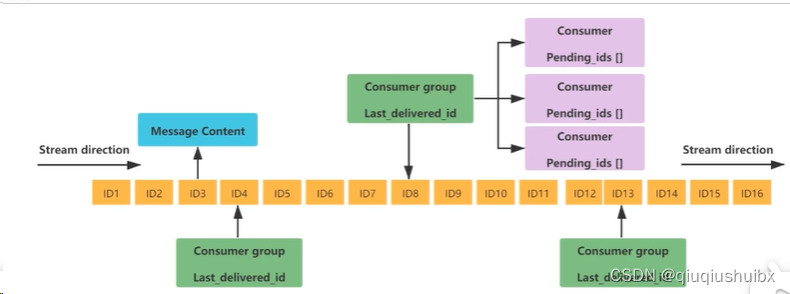
首先消息队列的底层是一个链表结构
解释一下这里的参数
Message Content 消息内容
Consumer group 消费组 含有多个消费者
Last_delieved_id 游标 可以理解为读完一个就向后走一个,消费完成 表示哪些是新的消息,哪些是消费过的消息
消费者读完确认了就是ack 类似于TCP中的ack
这里记录的就是读过了但是没有签收的消息id 如果客户端没有ack 这里面的消息就会越来越多 如果客户段发送ack就开始减少 主要用来确保消息至少被消费了一次,而不是在网络传输中被丢失
有关Redis指令
xadd mystream * k1 v1
这里*表示自动生成消息ID
这里的返回值就是毫秒时间戳和该毫秒产生的第一条消息
注:同一时间产生的消息不允许相同,但是可以产生不同的消息
type mystream
我们还可以查看一下类型如上文所见
xrange 查看消息列表
xrange mystream - +
注:这里使用count来分页 和mysql中的limit一样
xrevrange mystream + -
就是将原来的输出掉个个儿
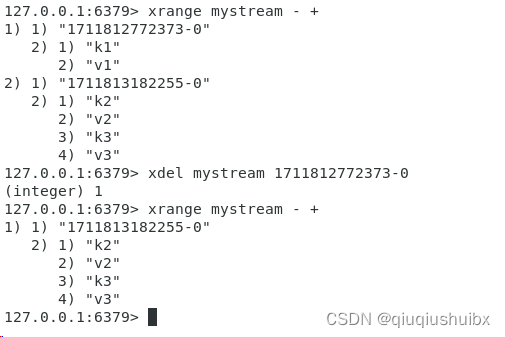
xdel mtstream 主键
注意这里是按照主键删除,也就是按照时间戳+第一条信息的id删除
注:这里如果出现以下错误,我们只需要将配置文件修改即可(推荐使用yes保证数据快照的时效性)
xlen key
查看长度
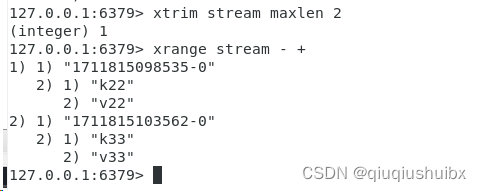
xtrim截取操作
可以按照时间截取也可以按照最大长度获取
我们首先加点数据
我们执行操作就可以看到数据只剩两个了
同样的我们可以规定截取在某时间戳之后产生的消息
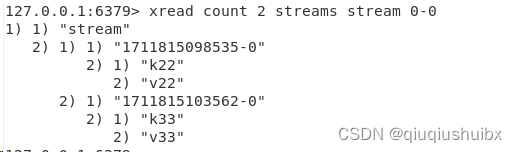
xread count n (block) streams key 符号
这里streams是一个关键字
这条指令用于获取消息,以阻塞或者非阻塞的方式或者比某个时间点大的n条消息
这里符号如果填写$就是表示目前队列中的最新消息的下一个消息
如果能获取到,返回,获取不到返回nil
0-0就是从最小的消息开始读取返回,没有限制就是类似于遍历整个队列
block 0 就是无限阻塞
我们这里举个例子就是获取最新的下一条信息 $ 然后我们重新开一个客户端来进行修改看能不能返回
新的客户端
旧的客户端
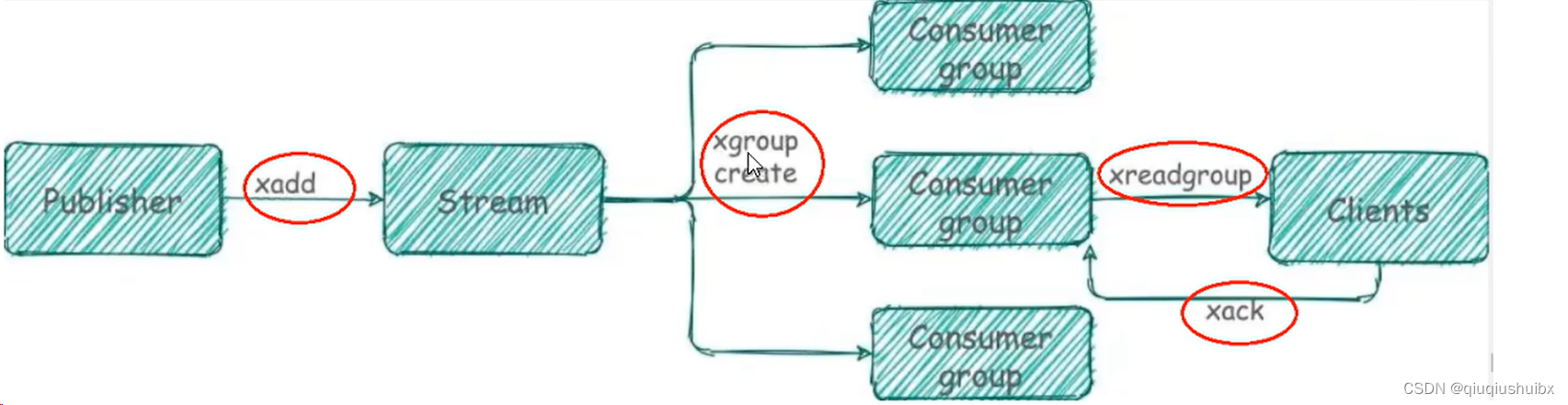
消费组指令
队列里面也有消息了,那如何来消费呢?
下面我们就开始讲解消费组
创建消费组
例:xgroup create mystream groupX $ 从尾部开始消费
xgroup create mystream groupA 0 从首部开始消费
注:此时2号消费者就读不到了,因为一旦被本组任意消费者消费了,指针就走到头了,本组其他消费者就不能再读取了
消费组的目的:
每个消费者读取一部分数据 这样就能达成负载均衡的效果
消息的ack机制
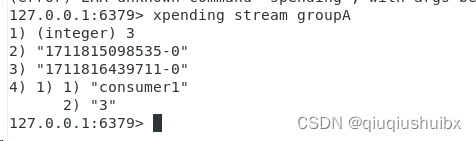
xpending key group
查看xpending队列中的消费组消费情况
这里就是groupA中的consumer1消费了三条数据
一旦消息被ack了之后,这里的消息队列中的数据就可以删除了
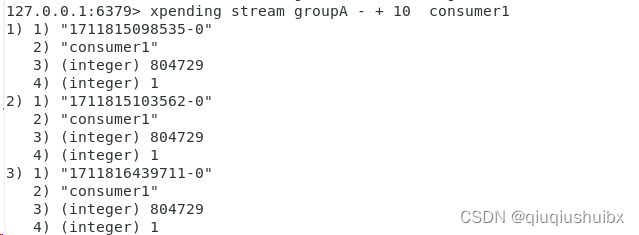
我们这里查看一下groupA的xpending数据
xpending stream groupA - + 10 consumer1
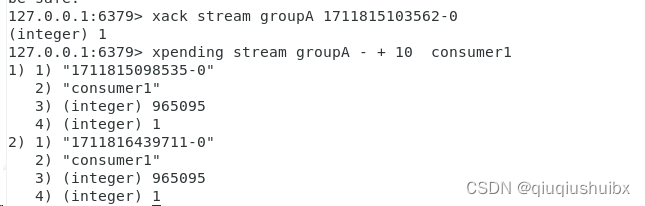
我们发现签收完了悬而未决的list中就删除了
注:这里队列中不会删除
xinfo 用于打印消费者分组的情况
xinfo stream mystream
使用建议
Stream不能100%代替kafka.....建议慎用










Bitfieid
这个数据类型,了解即可
基本命令
主要是做一个溢出控制
可以设置溢出之后是使用比如8位有符号整数
存储128之后就是-128 4位无符号存储15加一就会归零等等
几乎没有使用机会

这篇关于Redis类型 Stream Bitfield的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





