本文主要是介绍反应式编程(一)什么是反应式编程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、背景
- 二、反应式编程简介
- 2.1 定义
- 2.2 反应式编程的优势
- 2.3 命令式编程 & 反应式编程
- 三、Reactor 入门
- 3.1 Reactor 的核心类
- 3.2 Reactor 中主要的方法
- 1)创建型方法
- 2)转化型方法
- 3)其他类型方法
- 4)举个例子
- 四、Reactor 的工作原型
- 4.1 申明阶段
- 1)Flux.just()
- 2)map()
- 3)filter()
- 4)申明总结
- 4.2 订阅阶段
- 1)subscribe()、onSubscribe()
- 2)request()
- 3)订阅总结
- 4.3 Reactor 的工作原理总结
- 五、补充
- 5.1 Spring Gateway、WebFlux、Reactor、Netty的依赖关系
一、背景
反应式编程的概念在20世纪90年代开始形成,并在近年来随着云计算、物联网、大数据、移动互联网等技术的发展以及对 高性能、高并发、实时响应和事件驱动系统 需求的增强而逐渐流行起来。
背景和原因主要包括:
- 并发挑战: 传统的同步编程模型在处理高并发场景时可能会遇到 线程上下文切换带来的性能损失和资源浪费问题。反应式编程通过异步和非阻塞的方式来处理并发,提高了系统的吞吐量和响应能力。
- 数据流处理: 现代应用程序需要处理的数据量越来越大,而且经常涉及到数据流的实时处理和更新。反应式编程通过定义数据流和变换规则,让程序可以自动响应数据流的变化,简化了数据流处理的复杂度。
- 事件驱动架构: 在许多应用场景中,如用户交互、消息队列、传感器数据收集等,事件驱动成为主流。反应式编程特别适合处理这类事件驱动的场景,通过订阅和发布机制,程序可以根据事件的发生自动调整行为。
- 云原生和微服务: 云环境下的服务间通信常常是非同步的,微服务架构也需要高效的事件响应和错误处理机制。反应时变成理念帮助开发者构建弹性的、响应快速的分布式系统。
- 框架和技术支持: 随着 RxJava、Reactor、Akka Streams、Vert.x 等反应式编程库和框架的成熟,开发者有了更好的工具来实现反应式编程模型。
二、反应式编程简介
2.1 定义
反应式编程(Reactive Programming,Rx) 是一种基于 数据流(data stream)和 变化传递(propagation of change)的 声明式(declaractive)的编程范式。
反应式编程是一种编程思想、编程方式,是为了简化并发编程而出现的。与传统的处理方式相比,它能够基于数据流中的事件进行反应处理。例如:a+b=c 的场景:
- 在传统编程方式下,如果 a、b 发生变化,那么我们需要重新计算 a+b 来得到 c 的新值。
- 而在反应式编程中,我们不需要重新计算,a、b 的变化事件会触发 c 的值自动更新。这种方式类似于我们在消息中间件中常见的
发布/订阅模式。由流发布事件,而我们的代码逻辑作为订阅方基于事件进行处理,并且是异步处理的。
反应式编程中,最基本的处理单元是事件流中的事件(事件流是不可变的,对流进行操作只会返回新的流)。流中的事件包括:
- 正常事件: 对象代表的数据、数据流结束标识。
- 异常事件: 异常对象,例如:Exception。
同时,只有当订阅者订阅发布者后,发布者发布的事件流才会被消费,后续的订阅者只能从订阅点开始消费,但是我们可以通过 背压、流控 等方式控制消费。
2.2 反应式编程的优势
反应式编程的核心是基于 事件流、无阻塞、异步的,使用反应式编程不需要编写底层的并发、并发代码。并且由于其声明式编写代码的方式,是的异步代码易读且易维护。反应式编程主要优点有:
- 整体采用了观察者模式,异步解耦,提高服务器的吞吐量。
- 内部提出了
背压(Backpressure)概念,可以控制消费的速度。 - 书写方式与迭代器,stream 类似,方便使用者理解。
2.3 命令式编程 & 反应式编程
命令式编程:
- 我们普通的编程方法几乎都是命令式编程,按顺序执行一批代码,下一个任务的执行依赖于上一个任务的成功执行,最后等到所有代码执行完毕,我们才能拿到最终的输出结果,这就好像我订阅了一年的报纸,必须是等一年后才能拿到最近这一年的所有报纸。
反应式编程:
- 类似于生活中真实的订阅报纸。虽然我订阅的是一年的报纸,但是我每天都能收到新的报纸。我们不需要等到所有代码都执行完毕才能取到数据,任务可以是并行处理的,我们可以得到中间的数据,每个任务处理一部分数据,最后进行汇总。
与迭代器对比:
| 事件 | Iterable | Observable |
|---|---|---|
| 迭代 | next() | onNext() |
| 异常 | throws Exception | onError() |
| 完成 | !hasNext() | onComplete() |
-
Observable列表示观察者接收到的相关事件时触发的动作。
-
如果迭代器看作是 “拉模式”,那观测者模式便是 “推模式”。
-
被观察者(Subscriber)主动的推送数据给订阅者(Subscriber),触发 onNext() 方法。
出现异常时触发 onError() 方法。
完成后触发 onCompleted() 方法。
与stream对比:
| 事件 | stream | Observable |
|---|---|---|
| 映射 | map() | map() |
| 过滤 | filter() | filter() |
- 与 stream 对比可以看出,Reactive Programming 也是通过类似的数据流方式来处理订阅的数据。
- 不同点在于 stream 无法控制消息发送速度,而反应式编程中如果 Publisher 发布消息太快,超过了 Subscriber 的处理速度,反应式编程提供了
背压机制来控制 Publisher 的速度。
三、Reactor 入门
3.1 Reactor 的核心类
-
Mono<T>: 实现了 org.reactivestreams.Publisher 接口,代表 0~1 个元素的发布者。
-
Flux<T>: 同样实现了 org.reactivestreams.Publisher 接口,代表 0~N 个元素的发布者。
Mono<T> 和 Flux<T> 可以相互转换。多个 Mono 可以合并成一个 Flux<T>,一个 Flux<T> 也可以转化成 Mono<T>。
-
Subscriber: 观察者,用来观察 Publisher 相关动作。
-
Subscription: 解耦 Subscriber 和 Publisher。
3.2 Reactor 中主要的方法
1)创建型方法
- just(): 根据参数创建数据流。
- never(): 创建一个不会发出任何数据的无限运行的数据流。
- empty(): 创建一个不包含任何数据的数据流,不会无限运行。
- error(): 创建一个订阅后立即返回异常的数据流。
- concat(): 从多个 Mono<T> 创建 Flux<T>。
- generate(): 同步、逐一的创建复杂流。重载方法支持生成状态。在方法内部的 Lambda 中通过调用 next() 和 complete()、error() 来指定当前循环返回的流中的元素(并不是return)。
- create(): 支持同步、异步、批量的生成流中的元素。
- zip(): 将多个流合并为一个流,流中的元素一一对应。
- delay(): Mono<T>方法,用于指定流中的第一个元素产生的延迟时间。
- interval(): Flux<T>方法,用于指定流中各个元素产生时间的间隔(包括第一个元素产生时间的延迟),从 0 开始的 Long 对象组成的流。
- justOrEmpty(): Mono<T>方法,用于指定当初始化时的值为null时,返回空的流。
- defaultEmpty(): Mono<T>方法,用于指定当流中元素为空时产生的默认值。
- range(): 生成一个范围的 Integer 队列。
2)转化型方法
- map(): 将流中的数据按照逻辑逐个映射为一个新的数据,当流是通过 zip() 创建时,有一个元组入参,元组内元素代表 zip() 前的各个流中的元素。
- flatMap(): 将流中的数据按照逻辑逐个映射一个新的六,新的流之间是异步的。
- take(): 从流中获取 N 个元素,有多个扩展方法。
- zipMap(): 将当前流和另一个流合并为一个流,两个流中的的元素一一对应。
- mergeWith(): 将当前流和另一个流合并为一个流,两个流中的元素按照生成顺序合成,无对应关系。
- join(): 将当前流和另一个流合并为一个流,流中的元素不是一一对应的关系,而是根据产生时间进行合并。
- concatWith(): 将当前流和另一个流按声明顺序(不是元素的生成时间)链接在一起,保证第一个流消费完再消费第二流。
- zipWith(): 将当前流和另一个流合并为一个新的流,这个流可以通过 Lambda 表达式设定合并逻辑,并且流中元素一一对应。
- first(): 对于 Mono<T> 返回多个流中,第一个产生元素的 Mono<T>。对于 Flux<T>,返回多个 Flux<T> 流中第一个产生元素的 Flux<T>。
- block(): Mono<T> 和 Flux<T> 中类似的方法,用于阻塞当前线程直到流中生成元素。
- tolterable(): Flux<T> 方法,将 Flux<T> 生成的元素返回一个迭代器。
- defer(): Flux<T> 方法,用于从一个 Lambda 表达式获取结果来生成 Flux<T> ,这个 Lambda 一般是线程阻塞的 buffer 相关方法,用于将流中的元素按照时间、逻辑规则分组为多个元素集合,并且这些元素集合组成一个元素类型为集合新流。
- window(): 与 buffer() 类似,但是 window() 返回的流中元素类型还是流,而不是 buffer 的集合。
- filter(): 顾名思义,返回负责规则的元素组成的新流。
- reduce(): 用于将流中的各个元素与初始值(可以设置)逐一累积,最终得到一个 Mono<T>。
3)其他类型方法
- duOnXXXX(): 当流发生 XXX 时的回调方法,可以有多个,类似于监听。XXX 包括 Subscribe、Next、Complete、Error 等。
- onErrorResume(): 设置流发生异常时返回的发布者,此方法的 Lambda 时异常对象。
- onErrorReturn(): 设置流发生异常时返回的元素,无法捕获异常。
- then(): 返回 Mono<T>,跳过整个流的消费。
- ignoreElements(): 忽略整个流中的元素。
- subscribeOn(): 配合 Scheduler 使用,订阅时的线程模型。
- publisherOn(): 配合 Scheduler 使用,发布时的线程模型。
- retry(): 订阅者重试次数。
4)举个例子
场景: 假设有个名单列表,要根据 名单 获取对应名字的邮箱,并且过滤掉邮箱长度小于 10 的邮箱,最后再将符合条件的邮箱打印出来。
使用 stream 编程如下所示:
Stream.of("Tom", "Bob", "zhangsan", "lisi").map(s -> s.concat("@qq.com")).filter(s -> s.length() > 10).forEach(System.out::println);
使用 Reactive 编程如下所示:
Flux.just("Tom", "Bob", "zhangsan", "lisi").map(s -> s.concat("@hq.com")).filter(s -> s.length() > 10).subscribe(System.out::println);
通过上述例子可以看出,stream 和 Reactive 在形式上有相似之处,都是先创建数据源,然后经过中间过程处理转换,最后再消费中间处理结果。接下来我们逐行进行下解析:
-
Flux.just(“Tome”, “Bob”, “zhangsan”, “lisi”)
Flux.just() 创建一个 Flux 的发布者。除了使用 just() 方法外,还有 fromCallable(),fromIterable() 等其他方式用来从不同场景中创建 publisher。
-
map(s -> s.concat(“@qq.com”))
map 的含义就是映射,在该步骤中将每个序列元素进行转换,在每个名称后面加上邮箱后缀。
-
filter(s -> s.length() > 10)
过滤步骤,剔除掉长度不大于 10 的元素。
-
subscribe(System.out::println)
该步骤是最终的订阅节点,之前创建的都是被观察者,该步骤是创建一个观察者 Subscriber。其中 Subscriber 的具体行为就是 System.out::println 打印出之前处理过的元素。
至此,一个订阅发布的过程就结束了。
四、Reactor 的工作原型
其实 反应式编程的核心就是一个观察者模式。

Flux<T> 和 Mono<T> 相当于观察者模式中的 subject,当 Flux<T> 或 Mono<T> 调用 subscribe() 方法时,相当于 subject 发出了一个 Event,从而让订阅次事件的观察者进行消费。
那 Flux 框架具体是如何实现这套机制呢,还是上文中的例子,我们下面跟踪下它是如何工作的。
Flux.just("Tom", "Bob", "zhangsan", "lisi").map(s -> s.concat("@qq.com")).filter(s -> s.length() > 10).subscribe(System.out::println);
reactor-core版本: 3.1.9.RELEASE
4.1 申明阶段
1)Flux.just()
进入 just() 方法,经过若干跳转后,进入如下方法:
public static <T> Flux<T> fromArray(T[] array) {if (array.length == 0) {return empty();}if (array.length == 1) {return just(array[0]);}return onAssembly(new FluxArray<>(array));
}
onAssembly 是一个钩子方法,暂时忽略。最终就是 new FluxArray<>(array) 一个对象创建出一个 FluxArray。点击 FluxArray 的构造函数中,可以看到,只是把 array 赋值给了对象内部的 array。
final T[] array;@SafeVarargs
pubilc FluxArray(T... array) {this.array = Objects.requireNonNull(array, "array");
}
2)map()
Flux.just() 方法只是创建了一个 FluxArray 对象,回到最开始定义的地方,下一步执行的是 map 方法。定义如下所示:
public final <V> Flux<V> map(Function<? super T, ? extends V> mapper) {if (this instanceof Fuseable) {return onAssembly(new FluxMapFuseable<>(this, mapper));}return onAssembly(new FluxMap<>(this, mapper));
}
上一步创建的 FluxArray 是一个 Fuseable,所以执行 if 条件里的逻辑,创建一个 FluxMapFuseable 对象,FluxMapFuseable 的构建函数中有两个参数,this 和 mapper。
- this 就是上一步创建出来的 FluxArray;
- mapper 就是我们自定义的 Lambda 表达式,即:s -> s.concat(“@qq.com”)。
再点击进入 FluxMapFuseable 的构造函数中。
FluxMapFuseable(Flux<? extends source, Function<? super T, ? extends R> mapper) {super(source);this.mapper = Objects.requireNonNull(mapper, "mapper");
}
从这个构造函数可以看出,source 是上一步骤 just() 得到的 FluxArray,mapper 是对应 map 的 Lambda 表达式,所以当执行 map 操作的时候,其实是又将 FluxArray 进行封装,得到了一个新的 FluxMapFuseable 对象。
3)filter()
再次回到开始的申明地方,在执行完 map() 操作后,接着执行 filter() 方法。同理,点击 filter() 方法,可以看到如下代码。
public final Flux<T> filter(Predicate<? super T> p) {if (this instanceof Fuseable) {return onAssembly(new FluxFilterFuseable<>(this, p));}return onAssembly(new FluxFilter<>(this, p));
}
在看过 map 的操作后,这一步骤其实就相当熟悉了,filter 步骤将上一步 map 操作得到的 FluxMapFuseable 方法又一次封装成了 FluxFilterFuseable 对象。
4)申明总结
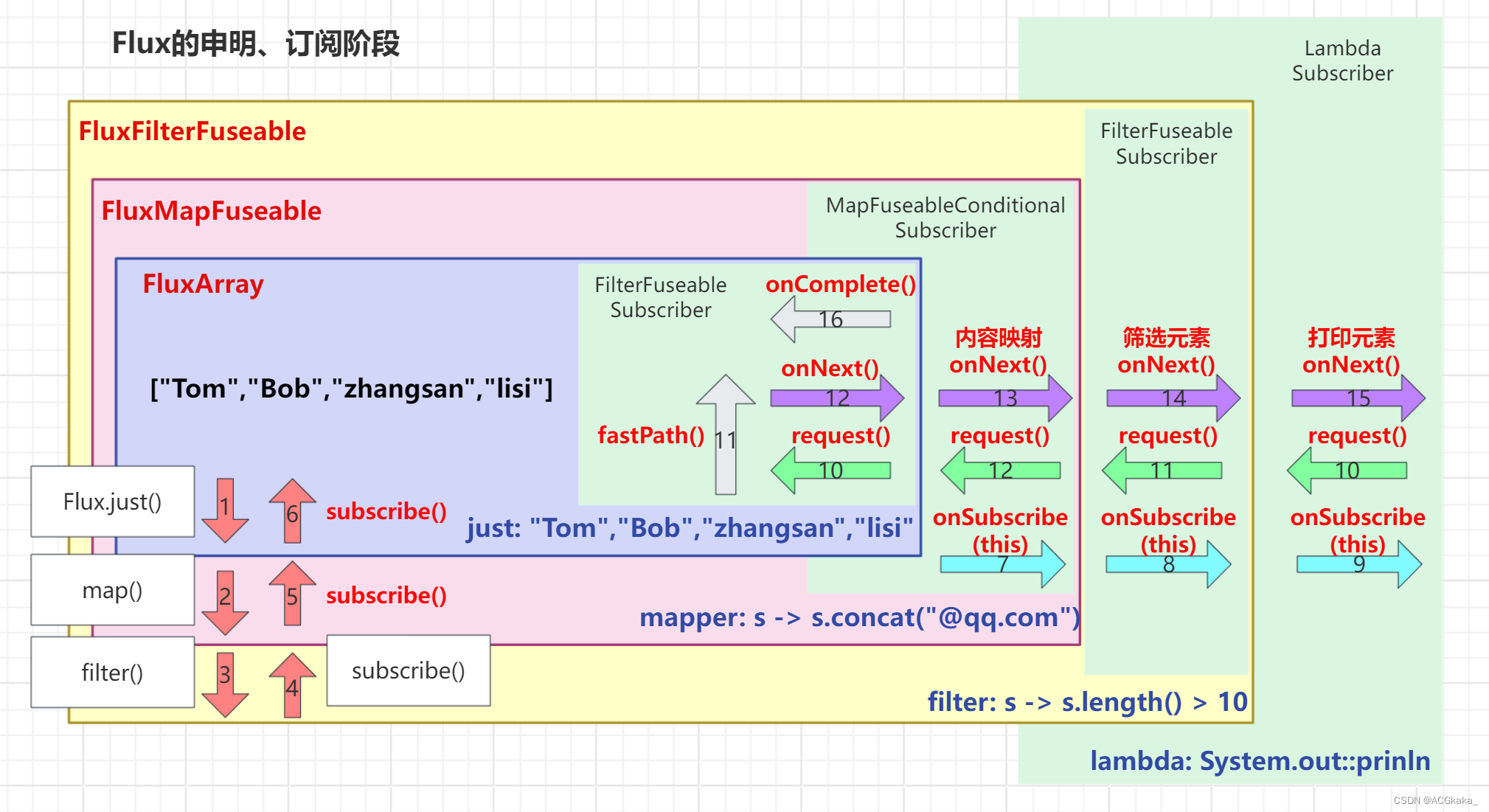
从上面的定义看看出,申明阶段就是一层一层的创建各种 Flux 对象,并没有实际执行任何操作。通过 just()、map()、filter() 等操作,将发布者一层一层的封装,从最开始的 FluxArray 对象,到 FluxMapFuseable 对象以及最后的 FluxFilterFuseable 对象。如下图所示:

4.2 订阅阶段
注意:
Subscriber类实际上对应的是 Reactive Stream 规范中的订阅者接口,它负责订阅并消费发布者发布的数据流。Subscriber 一词可以翻译成 “订阅者”,也可以翻译成 “观察者”,为方便理解,这里统一使用 “订阅者”。
1)subscribe()、onSubscribe()
上述例子中,just()、map()、filter() 只是创建了一个个的对象。并没有实际执行相关逻辑。当调用被观察者的 subscribe() 方法时,会为被观察者添加相应的观察者,同时触发观察者相关方法,从而整个观察者模式得以进行下去。接着看下 Flux 的 subscribe() 方法。经过一系列的 jump 后,最终会调用 Flux 的 subscribe() 方法。如下所示:
public abstract void subscribe(CoreSubscriber<? super T> actual);
该方法是一个抽象方法,需要看下子类是如何实现的。还记得上面申明阶段中 filter() 后产生的对象吗?FluxFilterFuseable 是 Flux 的一个具体实现,当调用 subscribe 后,会跳转到 FluxFilterFuseable 的 subscribe() 方法,代码如下:
/*** FluxFilterFuseable 的 subscribe()*/
public viod subscribe(CoreSubscriber<? super T> actual) {// actual 是 System.out::println,封装成了 LambdaSubscriber 订阅者if (actual instanceof ConditionalSubscriber) {source.subscribe(new FilterFuseableConditionalSubscriber<>((ConditionalSubscriber<? super T>) actual, predicate)); // 第1处return;}// 走到这里,将 System.out::println 和 s->s.length>10 封装为一个新的订阅者。source.subscribe(new FilterFuseableSubscriber<>(actual, predicate)); // 第2处
}
-
传进来的
actual是 System.out::println,也就是我们最终执行的表达式,它被封装成了一个 LambdaSubscriber订阅者。 -
predicate为 filter 指定的表达式 s -> s.length() > 10。 -
source为上一步骤中生成的 FluxMapFuseable 对象。根据对象情况,代码会走到第2处,第2处的逻辑就是将 actual 和 predicate 封装成一个 订阅者 去订阅 source 也就是 FluxMapFuseable 对象。
接着代码会去调用 source 的 subscribe() 方法,也就是 FluxMapFuseable 对应的 subscribe() 方法:
/*** FluxMapFuseable 的 subscribe()*/
public void subscribe(CoreSubscriber<? super R> actual) {// actual 是上一步新封装的 FilterFuseableSubscriber 订阅者if (actual instanceof ConditionalSubscriber) { // 第1处ConditionalSubscriber<? super R> cs = (ConditionSubscriber<? super R>) actual;source.subscribe(new MapFuseableConditionalSubscriber<>(cs, mapper));return;}// 走到这里,将 FilterFuseableSubscriber 和 s->s.concat("@qq.cmcc") 封装成新的订阅者source.subscribe(new MapFuseableSubscriber<>(actual, mapper)); // 第2处
}
代码还是会走到第2处,
-
这里传入的
actual是上一步骤中封装了 System.out::prinln 和 s -> s.length() > 10 的订阅者, -
mapper为 s -> s.concat(“@qq.com”),从这段代码可以看出,所做的逻辑就是将上一步中的观察者和 mapper 又封装成了新的订阅者,一层一层的套娃。
最后,看下本步骤中的 source,也就是 FluxArray 对象的 subscribe() 方法:
/*** FluxArray 的 subscribe()*/
public static <T> void subscribe(CoreSubscriber<? super T> s, T[] array) {if (array.length == 0) {Operators.complete(s);return;}// s 是上一步新封装的 MapFuseableSubscriber 订阅者if (s instanceof ConditionalSubscriber) { // 第1处s.onSubscribe(new ArrayConditionalSubscription<>((ConditionalSubscriber<? super T>) s, array));} else {// 走到这里,将 MapFuseableSubscriber 和 "Tom","Bob","zhangsan","lisi" 封装成订阅信息// 并且触发 “观察者模式”s.onSubscribe(new ArraySubscription<>(s, array)); // 第2处}
}
FluxArray 是数据的源头,
-
传入的
array为我们定义的 “Tom”,“Bob”,“zhangsan”,“lisi” 名字, -
s为上一步骤中创建的 subscriber订阅者。在数据的源头可以看出作为观察者模式的触发点,该步骤中触发了订阅者的 onSubscribe() 方法。同时为了解耦观察者和被观察者,创建一个 ArraySubscription 对象。FluxArray 的 subscribe() 会执行第2处代码,s.onSubscribe(new ArraySubscription<>(s, array)),这里的 s 是上一步骤中创建的 MapFuseableSubscriber 中的 onSubscribe() 方法,对应代码如下所示:
/*** MapFuseableSubscriber 的 onSubscribe()*/
@Override
public void onSubscribe(Subscription s) {// s 是封装的 ArraySubscription 订阅信息if (Operators.validate(this.s, s)) {this.s = (QueueSubscription<T>) s;// actual 是 FilterFuseableSubscriber 对象actual.onSubscribe(this);}
}
-
actual是 FilterFuseableSubscriber 对象,本质就是赋值后,然后调用 FilterFuseableSubscriber 的 onSubscribe() 方法。
FilterFuseableSubscriber 对应的 onSubscribe() 方法如下所示:
/*** FilterFuseableSubscriber 的 onSubscribe()*/
@Override
public void onSubscribe(Subscription s) {// s 是封装的 ArraySubscription 订阅信息if (Operators.validate(this.s, s)) {this.s = (QueueSubscription<T>) s;// actual 是 LambdaSubscriber 对象actual.onSubscribe(this);}
}
- 和 MapFuseableSubscriber 类似,
actual对应的是 LambdaSubscriber,也就是 System.out::println。
LambdaSubscriber 的 onSubscribe() 如下所示:
/*** LambdaSubscriber 的 onSubscribe()*/
public final void onSubscribe(Subscription s) {// s 是封装的 ArraySubscription 订阅信息if (Operators.validate(subscription, s)) {this.subscription = s;if (subscriptionConsumer != null) {try {subscriptionConsumer.accept(s); // 第1处} catch (Throwable t) {Exceptions.throwIfFatal(t);s.cancel();onError(t);}} else {// 走到这里s.request(Long.MAX_VALUE); // 第2处}}
}
第1处和第2处代码的最终逻辑都一样,都会执行 request 方法。背压的原理就是通过这个 request 来实现的,观察者可以通过 request 来指定一次性订阅多少数据。
总结一下:
- 一个 subscribe() 方法其实是创建了三个订阅者,与创建发布者类似,创建的订阅者也是一层一层嵌套。从最外层的 Subscriber 与上一层的操作结合生成一个新的 Subscriber。再继续向上调用,最终调用到数据源头。然后从数据源头开始一层一层,最后再触发订阅者的 onSubscribe() 方法。
2)request()
由上文可知,在 onSubscribe() 方法调用阶段最终会调用 s 的 request() 方法。s 就是封装的 ArraySubscription 订阅信息,用于解耦订阅者和被订阅者。
ArraySubscription 的 request() 如下所示:
/*** ArraySubscription 的 request()*/
@Override
public void request(long n) {if (Operations.validate(n)) {if (Operators.addCap(REQUESTED, this, n) == 0) {if (n == Long.MAX_VALUE) {// 走到这里fastPath(); // 第1处} else {slowPath(); // 第2处}}}
}void fastPath() {final T[] a = array;final int len = a.length;// s 是之前封装的 MapFuseableSubscriber 订阅者final Subscriber<? super T> s = actual;for (int i = index; i != len; i++) {if (cancelled) {return;}T t = a[i];if (t == null) {s.onError(new NullPointerException("The " + i + "th array element was null"));return;}s.onNext(t);}if (cancelled) {return;}s.onComplete();
}
直接看下 fastPath() 方法,代码都贴在上面了。到这里就真正开始消费了。通过一个 for 循环,调用 Subscriber 订阅者的 onNext() 方法,onNext() 方法执行完毕后,执行 Subscriber 的 onComplete() 方法。
- 这里的 s 是 MapFuseableConditionalSubscriber,看下它的 onNext() 方法:
public void onNext(T t) {if (sourceMode == ASYNC) {actual.onNext(null);} else {if (done) {Operators.onNextDropped(t, actual.currentContext());return;}R v;try {v = Objects.requireNonNull(mapper.apply(t), "The mapper returned a null value."); // 第1处} catch (Throwable e) {onError(Operators.onOperatorError(s, e, t, actual.currentContext()));return;}actual.onNext(v); // 第2处}
}
- 在第1处执行 mapper 对应的 Lambda 表达式,
- 在第2处执行下一步的 Subscriber 的 onNext() 方法。
下一步是 Filter,再下一步是最终的 System.out::println。最后 onNext() 都执行完成后,执行 s 的 onComplete() 方法,道理也是一样的,都是从最开始 Subscriber 的 onComplete() 方法一层一层执行。至此一个完整的观察者模式的执行情况就完成了。
3)订阅总结
订阅的整体流程图如下所示:
4.3 Reactor 的工作原理总结
- 申明阶段: 支持创建了一个个的被订阅者,把动作包装成对象,其他什么事都没做,直到调用被观察者的 subscribe() 方法,为被订阅者添加订阅者。
- 订阅阶段——subscribe()、onSubscribe(): 添加订阅者后,每一个申明步骤都会创建一个新的订阅者,订阅上个步骤的被订阅者,直到最外层被订阅者触发 onSubscribe() 方法,接着按照刚才添加的订阅者一层层调用对应的 onSubscribe() 方法,最后触发 request 方法。
- 订阅阶段——request(): 当触发到最外层的 request() 后,就执行真正的逻辑,再一层层调用订阅者的 onNext() 方法。最后完成后调用 onComplete() 方法。
五、补充
5.1 Spring Gateway、WebFlux、Reactor、Netty的依赖关系
springboot-webflux是一个引入了 spring-boot-starter-webflux 依赖的 Demo 项目,其中各个组件的依赖关系如下所示:
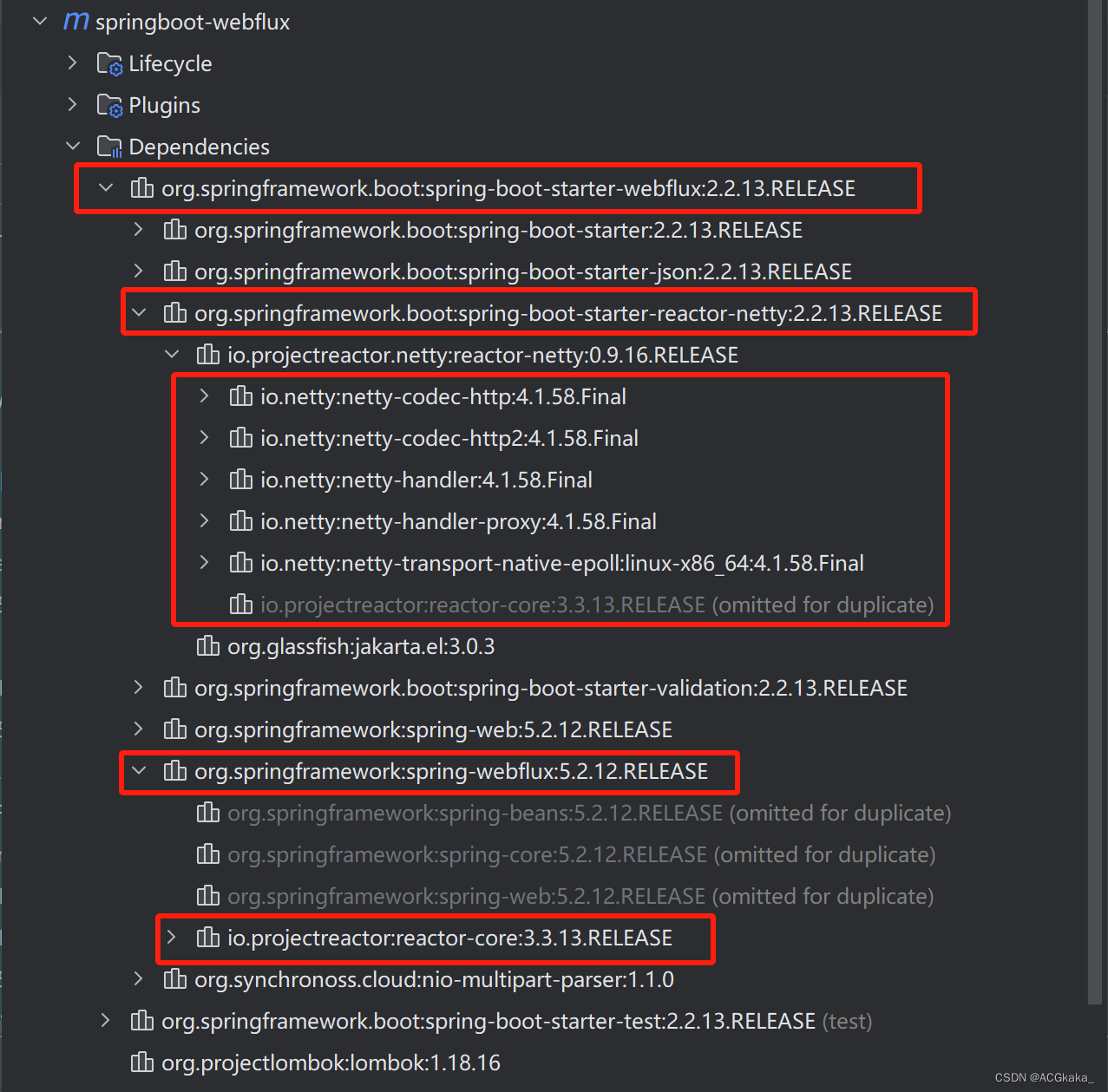
- Spring Cloud Gateway:
- Spring Cloud Gateway 是一个基于 Spring 框架构建的 API 网关,用于微服务架构中的服务路由、过滤和安全控制等功能。
- 为了实现高性能和异步非阻塞的特性,它选择基于 WebFlux 框架来构建。
- WebFlux:
- Spring WebFlux 是 Spring 框架提供的一个完全非阻塞的、反应式编程模型的 Web 框架,适用于构建异步和事件驱动的 Web 应用程序。
- WebFlux 可以运行在多种底层服务器之上,其中一个选项就是 Reactor Netty。
- Reactor:
- Reactor 是一个反应式编程库,它是 Reactive Streams 规范的一个实现,提供了 Publishers、Subscribes、Processors 等组件,便于构建异步和数据流驱动的应用程序。
- 在 Spring WebFlux 中,Reactor 用于构架和处理事件驱动的数据流,如 HTTP 请求和响应。
- Reactor Netty:
- Reactor Netty 是结合了 Netty 和 Reactor 的项目,它将 Netty 的高性能网络能力与 Reactor 的反应式编程模型相结合,形成了一个高度优化的异步 HTTP 服务器和客户端实现。
- Spring WebFlux 使用 Reactor Netty 作为其底层网络通信层,从而使得 WebFlux 能够在 Netty 的基础上高效地处理 HTTP 请求和响应。
整理完毕,完结撒花~🌻
参考地址:
1.什么是反应式编程(超详细说明),反应式编程和命令式编程的区别。如何使用Spring中的Reactor。Reactor中常用的操作。Mono和Flux。https://blog.csdn.net/qq_42799615/article/details/111235576
2.反应式编程入门及原理,https://juejin.cn/post/7034350525197860878
这篇关于反应式编程(一)什么是反应式编程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






