本文主要是介绍torch.fx量化resnet18_cifar10,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
运行环境
11th Gen Intel® Core™ i7-11370H @ 3.30GHz
从HuggingFace上下载训练好的模型 链接
import timm
model = timm.create_model("resnet18_cifar10", pretrained=True)
加载模型
import torch
from torch import nn
from torchvision.models.resnet import resnet18model=resnet18(pretrained=True) #加载pytorch官方提供的预训练模型结构
#手动修改网络层维度,与自定义模型结构相同
model.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
model.maxpool = nn.Identity() # type: ignore
model.fc=nn.Linear(model.fc.in_features,10)
#根据模型结构将模型的state_dict(参数)加载到模型中
#torch.load函数用pickle的反序列化功能将保存的对象文件加载到内存中。这个函数还支持将数据加载到指定的设备上。
#model.load_state_dict函数用于使用反序列化的state_dict加载模型的参数字典。
model.load_state_dict(torch.load("resnet18_cifar10.pth",map_location='cpu'))
model.to(torch.device("cpu"))
model.eval()#设置模型为推理模式
DataLoader加载Cifar10数据集
from torch.utils.data import DataLoader# 设置mean和scale
transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])#下载数据集
train_data = torchvision.datasets.CIFAR10(root='data', train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='data', train=False, transform=transform_test,download=True)# DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)量化校准并量化
# 校准恢复精度
model_to_quantize=copy.deepcopy(model)
prepared_model=prepare_fx(model_to_quantize,qconfig_mapping,example_inputs=torch.randn([1,3,224,224]))
prepared_model.eval()
#量化校准
with torch.inference_mode():for inputs,labels in test_dataloader:prepared_model(inputs)
quantized_recover_model=convert_fx(prepared_model)
print(f"quantized model {quantized_recover_model.graph.print_tabular()}")
保存量化后的模型:
script_module = torch.jit.trace(quantized_recover_model, example_inputs=torch.randn([1, 3, 224, 224]))
torch.jit.save(script_module, "quant_model.pth")
加载序列化的量化模型并测试模型精度:
quantized_recover_model = torch.jit.load("C:\\Users\\tanfengfeng\\PycharmProjects\\pythonProject1\\quant_model.pth")
# quantized_recover_model.load_state_dict(torch.load("C:\\Users\\tanfengfeng\\PycharmProjects\\pythonProject1\\tmp.pt", map_location='cpu'))
with torch.autograd.profiler.profile(enabled=True, use_cuda=False, record_shapes=False, profile_memory=False) as prof:test(quantized_recover_model, test_dataloader, device='cpu')
print(prof.table())
测试模型精度:
def test(model, test_dataloader, device):best_acc = 0model.eval()test_loss = 0correct = 0total = 0test_acc = 0with torch.no_grad():#设置禁止计算梯度for batch_idx, (inputs, targets) in enumerate(test_dataloader):#从DataLoader获取数据inputs, targets = inputs.to(device), targets.to(device)outputs = model(inputs)#前向传播criterion = nn.CrossEntropyLoss()loss = criterion(outputs, targets)#计算交叉熵损失test_loss += loss.item()# item() 获取标量的数值_, predicted = outputs.max(1) # 返回第1个维度上的最大的(元素值,索引) predicted为每个样本预测的分类Idtotal += targets.size(0)correct += predicted.eq(targets).sum().item()test_acc = correct / totalprint('[INFO] Test Accurancy: {:.3f}'.format(test_acc), '\n')
完整代码:
# https://juejin.cn/post/7178317867492835383#heading-7
# https://huggingface.co/edadaltocg/resnet18_cifar10import os
import copy
import timeimport torch
from torch import nnimport torchvision
from torchvision import transforms
from torchvision.models.resnet import resnet18from torch.quantization.quantize_fx import prepare_fx, convert_fx
from torch.ao.quantization import get_default_qconfig_mappingfrom torch.utils.data import DataLoaderdef test(model, test_dataloader, device):best_acc = 0model.eval()test_loss = 0correct = 0total = 0test_acc = 0with torch.no_grad(): # 设置禁止计算梯度for batch_idx, (inputs, targets) in enumerate(test_dataloader): # 从DataLoader获取数据inputs, targets = inputs.to(device), targets.to(device)outputs = model(inputs) # 前向传播criterion = nn.CrossEntropyLoss()loss = criterion(outputs, targets) # 计算交叉熵损失test_loss += loss.item() # item() 获取标量的数值_, predicted = outputs.max(1) # 返回第1个维度上的最大的(元素值,索引) predicted为每个样本预测的分类Idtotal += targets.size(0)correct += predicted.eq(targets).sum().item()test_acc = correct / totalprint('[INFO] Test Accurancy: {:.3f}'.format(test_acc), '\n')def print_size_of_model(model):torch.save(model.state_dict(), "tmp.pt")print(f"The model size:{os.path.getsize('tmp.pt') / 1e6}MB")model = resnet18(pretrained=True)
# 修改模型
model.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
model.maxpool = nn.Identity() # type: ignore
model.fc = nn.Linear(model.fc.in_features, 10)
model.load_state_dict(torch.load("C:\\Users\\tanfengfeng\\.cache\\torch\\hub\\checkpoints\\resnet18_cifar10.pth", map_location='cpu'))
model.to(torch.device("cpu"))
model.eval()# 设置mean和scale
transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='data', train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='data', train=False, transform=transform_test, download=True)print("训练集的长度:{}".format(len(train_data)))
print("测试集的长度:{}".format(len(test_data)))# DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)#量化
torch.backends.quantized.engine = 'fbgemm' # 设置量化后端
qconfig_mapping = get_default_qconfig_mapping("fbgemm")
# 校准量化精度
model_to_quantize = copy.deepcopy(model)
prepared_model = prepare_fx(model_to_quantize, qconfig_mapping, example_inputs=torch.randn([1, 3, 224, 224]))
prepared_model.eval()
with torch.inference_mode():for inputs, labels in test_dataloader:prepared_model(inputs)quantized_recover_model = convert_fx(prepared_model)
# print(f"quantized model {quantized_recover_model.graph.print_tabular()}")
script_module = torch.jit.trace(quantized_recover_model, example_inputs=torch.randn([1, 3, 224, 224]))
torch.jit.save(script_module, "quant_model.pth")
# print_size_of_model(prepared_model)
# print_size_of_model(quantized_recover_model)#测试FP32模型精度和耗时
with torch.autograd.profiler.profile(enabled=True, use_cuda=False, record_shapes=False, profile_memory=False) as prof:test(model, test_dataloader, device='cpu')
print(prof.table())#测试int8模型精度和耗时
quantized_recover_model = torch.jit.load("C:\\Users\\tanfengfeng\\PycharmProjects\\pythonProject1\\quant_model.pth")
with torch.autograd.profiler.profile(enabled=True, use_cuda=False, record_shapes=False, profile_memory=False) as prof:test(quantized_recover_model, test_dataloader, device='cpu')
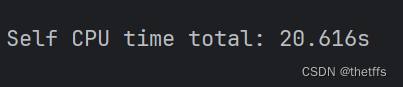
print(prof.table())运行结果截图:
FP32:


量化后:

总结
量化后推理时间快了一倍,并且模型精度几乎没有损耗。
这篇关于torch.fx量化resnet18_cifar10的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!