本文主要是介绍C# 操作 Word 全域查找且替换(含图片对象),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
关于全域查找且替换
Word应用样本
SqlServer数据表部分设计样本
范例运行环境
配置Office DCOM
设计实现
组件库引入
实现原理
查找且替换的核心代码
窗格内容
页眉内容
页脚内容
形状内容
小结
关于全域查找且替换
C#全域操作 Word 查找且替换主要包括如下四个对象:
| 序号 | 对象 | 说明 |
| 1 | Word.Appication.Selection | 窗格对象 |
| 2 | Word.Section.Headers[Word.WdHeaderFooterIndex.wdHeaderFooterPrimary].Range | 页眉对象 |
| 3 | Word.Section.Footers[Word.WdHeaderFooterIndex.wdHeaderFooterPrimary].Range | 页脚对象 |
| 4 | Word.Shape.TextFrame.TextRange | 形状对象 |
我们需要创建 Word.Find 对象,对上述相关区域分别进行查找替换操作。
Word应用样本
我们假设设计简历模板的输出,并查找且替换对应的关键字,如下图:

其中对应项目的关键字如 {xm}、{xb} 等则为查找且替换的对象,{grzp} 关键字处我们要处理图片的插入。
SqlServer数据表部分设计样本
设计 PersonInfo 数据表如下:
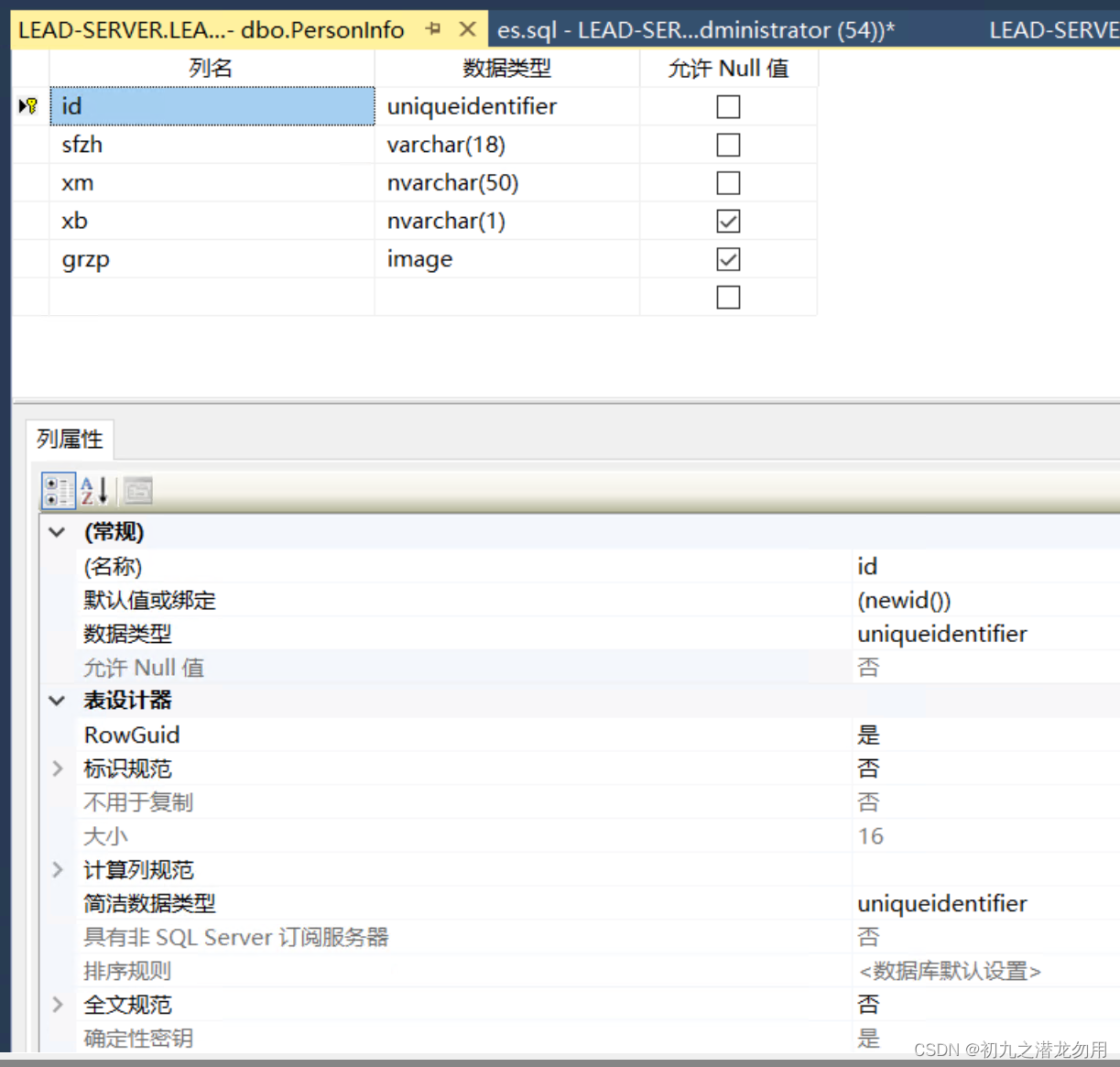
创建脚本如下:
CREATE TABLE [dbo].[PersonInfo]([id] [uniqueidentifier] ROWGUIDCOL NOT NULL,[sfzh] [varchar](18) NOT NULL,[xm] [nvarchar](50) NOT NULL,[xb] [nvarchar](1) NULL,[grzp] [image] NULL,CONSTRAINT [PK_PersonInfo] PRIMARY KEY CLUSTERED
([id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY],CONSTRAINT [IX_PersonInfo] UNIQUE NONCLUSTERED
([sfzh] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOALTER TABLE [dbo].[PersonInfo] ADD CONSTRAINT [DF_PersonInfo_id] DEFAULT (newid()) FOR [id]
GO通过查询 select sfzh,xm,xb,grzp from PersonInfo where id=xxx 得到DataSet,再取 Tables[0]中的数据。
范例运行环境
操作系统: Windows Server 2019 DataCenter
操作系统上安装 Office Excel 2016
数据库:Microsoft SQL Server 2016
.net版本: .netFramework4.7.1 或以上
开发工具:VS2019 C#
配置Office DCOM
配置方法可参照我的文章《C# 读取Word表格到DataSet》进行处理和配置。
设计实现
组件库引入
实现原理
我们假设查询出表数据,存入对应的变量,其中将二进制字段grzp数据写入到d:\test.jpg生成图片,示例代码如下:
DataTable dt=DataSet.Tables[0];string sfzh = dt.Rows[0]["sfzh"].ToString();
object bt = dt.Rows[0]["grzp"];
byte[] bFile2 = (byte[])bt;
System.IO.File.WriteAllBytes("@d:\test.jpg", bFile2);string xm = dt.Rows[0]["xm"].ToString();
string xb = dt.Rows[0]["xb"].ToString();
然后我们将其存到二维字符串数组 _repls 里,如下代码:
string[,] _repls = new string[4, 2];
_repls[0, 0] = "{sfzh}";
_repls[0, 1] = sfzh;
_repls[1, 0] = "{xm}";
_repls[1, 1] = xm;
_repls[2, 0] = "{xb}";
_repls[2, 1] = xb;
_repls[3, 0] = "RepalceFromImageFilename_{grzp}";
_repls[3, 1] = "@d:\test.jpg";其中第一元素存储要查找的关键字,第二元素存储要替换的值。注意:替换图片使用了自定义的RepalceFromImageFilename_ 前缀关键字,则表示值为对应的文件路径。数据准备完毕后,我们将通过遍历数组对 Word 进行查找且替换操作。
查找且替换的核心代码
窗格内容
示例代码如下:
WordApp.Options.ReplaceSelection = true;Word.Find fnd = WordApp.Selection.Find;for(int i=0;i<_repls.GetLength(0);i++){if (_repls[i, 0] == "" || _repls[i, 0] == null){continue;}fnd.ClearFormatting();string ft = _repls[i, 0];string replaceType = "";if (ft.IndexOf("RepalceFromImageFilename_") == 0){ft = ft.Replace("RepalceFromImageFilename_", "");replaceType = "RepalceFromImageFilename";}else if (ft.IndexOf("RepalceFromImageFilenameNoDelete_") == 0){ft = ft.Replace("RepalceFromImageFilenameNoDelete_", "");replaceType = "RepalceFromImageFilenameNoDelete";}Object findText = ft;Object matchCase = false;Object matchWholeWord = Type.Missing;Object matchWildcards = false;Object matchSoundsLike = false;Object matchAllWordForms = false;Object forward = true;Object wrap =Word.WdFindWrap.wdFindContinue;Object format = false;Object replaceWith ="";Object replace =Type.Missing;;Object matchKashida = Type.Missing;Object matchDiacritics = Type.Missing;Object matchAlefHamza = Type.Missing;Object matchControl = Type.Missing;while(fnd.Execute(ref findText, ref matchCase, ref matchWholeWord,ref matchWildcards, ref matchSoundsLike, ref matchAllWordForms, ref forward, ref wrap, ref format, ref replaceWith,ref replace, ref matchKashida, ref matchDiacritics,ref matchAlefHamza, ref matchControl)){string r_f=WordApp.Selection.Font.Name.ToString();if (replaceType == "RepalceFromImageFilename" || replaceType == "RepalceFromImageFilenameNoDelete"){if (File.Exists(_repls[i, 1].ToString())){WordApp.Selection.Range.Select();Word.InlineShape pic = WordApp.Selection.InlineShapes.AddPicture(_repls[i, 1].ToString(), false, true, WordApp.Selection.Range);if (replConfigs != null){string[] cv = replConfigs[ft].Split('|');pic.Width = int.Parse(cv[0]);pic.Height = int.Parse(cv[1]);}if (replaceType == "RepalceFromImageFilename"){File.Delete(_repls[i, 1].ToString());}}}else{WordApp.Selection.Range.Text = _repls[i, 1].ToString();}}}
页眉内容
示例代码如下:
foreach (Word.Section header in WordDoc.Sections){Word.Range headerRange = header.Headers[Word.WdHeaderFooterIndex.wdHeaderFooterPrimary].Range;Word.Find fnd = headerRange.Find;for (int i = 0; i < _repls.GetLength(0); i++){if (_repls[i, 0] == "" || _repls[i, 0] == null){continue;}fnd.ClearFormatting();string ft = _repls[i, 0];string replaceType = "";if (ft.IndexOf("RepalceFromImageFilename_") == 0){ft = ft.Replace("RepalceFromImageFilename_", "");replaceType = "RepalceFromImageFilename";}else if (ft.IndexOf("RepalceFromImageFilenameNoDelete_") == 0){ft = ft.Replace("RepalceFromImageFilenameNoDelete_", "");replaceType = "RepalceFromImageFilenameNoDelete";}Object findText = ft;Object matchCase = false;Object matchWholeWord = Type.Missing;Object matchWildcards = false;Object matchSoundsLike = false;Object matchAllWordForms = false;Object forward = true;Object wrap = Word.WdFindWrap.wdFindContinue;Object format = false;Object replaceWith = "";Object replace = Type.Missing; ;Object matchKashida = Type.Missing;Object matchDiacritics = Type.Missing;Object matchAlefHamza = Type.Missing;Object matchControl = Type.Missing;while (fnd.Execute(ref findText, ref matchCase, ref matchWholeWord, ref matchWildcards, ref matchSoundsLike, ref matchAllWordForms,ref forward, ref wrap, ref format, ref replaceWith, ref replace, ref matchKashida, ref matchDiacritics, ref matchAlefHamza, ref matchControl)){string r_f = WordApp.Selection.Font.Name.ToString();if (replaceType == "RepalceFromImageFilename" || replaceType == "RepalceFromImageFilenameNoDelete"){if (File.Exists(_repls[i, 1].ToString())){WordApp.Selection.Range.Select();Word.InlineShape pic = WordApp.Selection.InlineShapes.AddPicture(_repls[i, 1].ToString(), false, true, headerRange);if (replaceType == "RepalceFromImageFilename"){File.Delete(_repls[i, 1].ToString());}}}else{headerRange.Text = _repls[i, 1].ToString();}}}}
页脚内容
示例代码如下:
foreach (Word.Section footer in WordDoc.Sections){Word.Range footerRange = footer.Footers[Word.WdHeaderFooterIndex.wdHeaderFooterPrimary].Range;Word.Find fnd = footerRange.Find;for (int i = 0; i < _repls.GetLength(0); i++){if (_repls[i, 0] == "" || _repls[i, 0] == null){continue;}fnd.ClearFormatting();string ft = _repls[i, 0];string replaceType = "";if (ft.IndexOf("RepalceFromImageFilename_") == 0){ft = ft.Replace("RepalceFromImageFilename_", "");replaceType = "RepalceFromImageFilename";}else if (ft.IndexOf("RepalceFromImageFilenameNoDelete_") == 0){ft = ft.Replace("RepalceFromImageFilenameNoDelete_", "");replaceType = "RepalceFromImageFilenameNoDelete";}Object findText = ft;Object matchCase = false;Object matchWholeWord = Type.Missing;Object matchWildcards = false;Object matchSoundsLike = false;Object matchAllWordForms = false;Object forward = true;Object wrap = Word.WdFindWrap.wdFindContinue;Object format = false;Object replaceWith = "";Object replace = Type.Missing; ;Object matchKashida = Type.Missing;Object matchDiacritics = Type.Missing;Object matchAlefHamza = Type.Missing;Object matchControl = Type.Missing;while (fnd.Execute(ref findText, ref matchCase, ref matchWholeWord, ref matchWildcards, ref matchSoundsLike, ref matchAllWordForms,ref forward, ref wrap, ref format, ref replaceWith, ref replace, ref matchKashida, ref matchDiacritics, ref matchAlefHamza, ref matchControl)){string r_f = WordApp.Selection.Font.Name.ToString();// WordApp.Selection.Font.Name=r_f;// WordApp.Selection.Range// WordApp.Selection.TypeText(_repls[i,1].ToString());if (replaceType == "RepalceFromImageFilename" || replaceType == "RepalceFromImageFilenameNoDelete"){if (File.Exists(_repls[i, 1].ToString())){WordApp.Selection.Range.Select();Word.InlineShape pic = WordApp.Selection.InlineShapes.AddPicture(_repls[i, 1].ToString(), false, true, footerRange);if (replaceType == "RepalceFromImageFilename"){File.Delete(_repls[i, 1].ToString());}}}else{footerRange.Text = _repls[i, 1].ToString();}}}}
形状内容
示例代码如下:
foreach (Word.Shape shape in WordDoc.Shapes){if (shape.TextFrame.HasText == 0){continue; }Word.Find fnd = shape.TextFrame.TextRange.Find;//Word.Find fnd = WordDoc.Content.Find;for (int i = 0; i < _repls.GetLength(0); i++){if (_repls[i, 0] == "" || _repls[i, 0] == null){continue;}fnd.ClearFormatting();string ft = _repls[i, 0];string replaceType = "";if (ft.IndexOf("RepalceFromImageFilename_") == 0){ft = ft.Replace("RepalceFromImageFilename_", "");replaceType = "RepalceFromImageFilename";}else if (ft.IndexOf("RepalceFromImageFilenameNoDelete_") == 0){ft = ft.Replace("RepalceFromImageFilenameNoDelete_", "");replaceType = "RepalceFromImageFilenameNoDelete";}Object findText = ft;Object matchCase = false;Object matchWholeWord = Type.Missing;Object matchWildcards = false;Object matchSoundsLike = false;Object matchAllWordForms = false;Object forward = true;Object wrap = Word.WdFindWrap.wdFindContinue;Object format = false;Object replaceWith = "";Object replace = Type.Missing; ;Object matchKashida = Type.Missing;Object matchDiacritics = Type.Missing;Object matchAlefHamza = Type.Missing;Object matchControl = Type.Missing;while (fnd.Execute(ref findText, ref matchCase, ref matchWholeWord, ref matchWildcards, ref matchSoundsLike, ref matchAllWordForms,ref forward, ref wrap, ref format, ref replaceWith, ref replace, ref matchKashida, ref matchDiacritics, ref matchAlefHamza, ref matchControl)){string r_f = WordApp.Selection.Font.Name.ToString();if (replaceType == "RepalceFromImageFilename" || replaceType == "RepalceFromImageFilenameNoDelete"){if (File.Exists(_repls[i, 1].ToString())){Word.InlineShape pic = WordApp.Selection.InlineShapes.AddPicture(_repls[i, 1].ToString(), false, true, shape.TextFrame.TextRange);if (replaceType == "RepalceFromImageFilename"){File.Delete(_repls[i, 1].ToString());}}}else{shape.TextFrame.TextRange.Text = _repls[i, 1].ToString();}}}}
小结
1、示例代码是冗余的写法,在实际应用中我们需要进行优化。
2、添加图片后,代码默认是使用完毕后,删除图片文件以释放空间,我们自定义了 RepalceFromImageFilenameNoDelete_ 前缀关键字,表示使用完毕后不进行文件删除。
3、示例代码中 Word 表示 using Word=Microsoft.Office.Interop.Word; 的引用。
4、示例代码 WordDoc 表示对 Word.Document 的引用。
示例代码我们提供了操作的关键方法,这里仅作参考,其它代码不再做展示,欢迎大家评论指教!
这篇关于C# 操作 Word 全域查找且替换(含图片对象)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







