本文主要是介绍基于 RisingWave 和 ScyllaDB 构建事件驱动应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概览
在构建事件驱动应用时,人们面临着两大挑战:1)低延迟处理大量数据;2)实现流数据的实时摄取和转换。
结合 RisingWave 的流处理功能和 ScyllaDB 的高性能 NoSQL 数据库,可为构建事件驱动应用和数据管道提供有效的解决方案。
RisingWave 是什么?
RisingWave 是一款专为流处理设计且与 PostgreSQL 兼容的数据库。它擅长摄取实时数据流、执行各种转换并实现对结果的即时查询。
ScyllaDB 是什么?
ScyllaDB 是一款高性能分布式 NoSQL 数据库,擅长处理大量数据并为应用程序提供低延迟访问。ScyllaDB 与 Apache Cassandra 数据模型和协议兼容,这意味着在许多情况下,它可以作为 Cassandra 的简单替代品。ScyllaDB 还提供与 Amazon DynamoDB 兼容的 API。
ScyllaDB 具有低延迟和高吞吐量的特性,适合为需要快速数据访问的实时应用提供服务,如在线游戏、实时分析或物联网(IoT)应用。
二者协同
RisingWave 擅长处理流数据,包括对流数据的摄取、连接和转换。而 ScyllaDB 则能以极低的延迟为实时应用提供大量数据。
这两个系统为构建事件驱动应用或管道提供了坚实的基础。RisingWave 可在事件发生时即时处理事件数据,其内置的 ScyllaDB 连接器可实时将处理后的数据导出到 ScyllaDB。这种集成能够确保数据随时可供实时应用或管道查询使用。
如何将 RisingWave 与 ScyllaDB 集成
我们将使用以下示例来演示如何使用 RisingWave 和 ScyllaDB 构建事件驱动应用。设想一下电子商务中的个性化推荐场景,通过连接点击流和产品目录流,我们可以实时分析用户的偏好并提供个性化推荐。
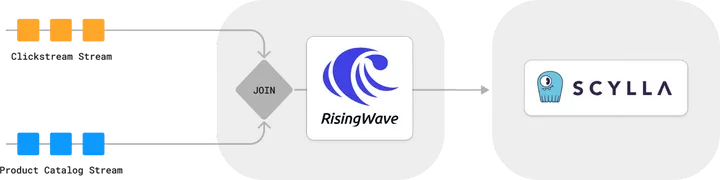
连接点击流和产品目录流
点击流示例如下:
{"user_id": "john_doe","item_id": "12345","timestamp": "2023-03-08T15:30:00Z"
}
产品目录流示例如下:
{"item_id": "12345","category": "electronics","price": 100,"timestamp": "2023-03-08T10:00:00Z"
}
步骤 1:从 RisingWave 摄取 Kafka 的实时数据
假设我们已将这两个流的数据分别打包到两个 Kafka Topic 中。
现在在 RisingWave 中创建两个 Source 来摄取这两个流:
# 为点击流创建一个 Source
CREATE SOURCE clickstream (user_id VARCHAR,item_id VARCHAR,timestamp TIMESTAMPTZ
)
WITH (type = 'kafka',kafka_topic = 'clickstream',kafka_brokers = 'localhost:9092'
);# 为产品目录流创建一个 SourceCREATE SOURCE product_catalog (item_id VARCHAR,category VARCHAR,price NUMERIC,timestamp TIMESTAMPTZ
)
WITH (type = 'kafka',kafka_topic = 'product_catalog',kafka_brokers = 'localhost:9092'
);
步骤 2:在 ScyllaDB 中创建表
由于我们要实时连接数据流并将数据导出到 ScyllaDB,因此需要在 ScyllaDB 中创建一个表来保存连接后的数据流。
CREATE TABLE joined_stream (user_id TEXT,item_id TEXT,timestamp TIMESTAMPTZ,category TEXT,price DECIMAL,PRIMARY KEY (user_id, item_id, timestamp)
);
步骤 3:执行流 Join 并导出到 ScyllaDB
在 RisingWave 中,您可以通过创建 Sink 将数据导出到下游系统。在 CREATE SINK 语句中还可以包含数据转换逻辑。创建 Sink 时与创建 Source 或者实时物化视图类似,本质上都是创建了持续数据处理的任务。在 RisingWave 中,如果要创建的是简单直接的实时数据处理管道,只需两条 SQL 语句即可做到:CREATE SOURCE 和 CREATE SINK。
CREATE SINK joined_stream AS
SELECT c.user_id, c.item_id, c.timestamp, p.category, p.price
FROM clickstream c
JOIN product_catalog p ON c.item_id = p.item_id;
WITH (connector='cassandra',type='append-only',cassandra.url = '<node1>,<node2>,<node3>',cassandra.keyspace = '<keyspace>',cassandra.table = 'joined_stream'
);
有关详细的句法和参数信息,请参阅 从 RisingWave 导出数据到 Cassandra 或 ScyllaDB。
到这一步,ScyllaDB 中的数据已可为应用或下游系统提供查询服务。
总结
只需三个步骤,我们就建立了无缝的连续数据处理管道,自动执行流 Join 并将连接后的数据导出到 ScyllaDB。ScyllaDB 的高性能使得实时应用能够以低延迟查询数据。这一集成的独特之处在于整个工作流程的设置非常简单。
以上是一个简单的用例示范,除此之外,使用 RisingWave,您可以轻松地过滤、连接和转换流数据,轻松表达复杂的转换逻辑。我们鼓励您进一步探索,如有任何疑问或需要支持,请联系我们。
事件驱动应用和数据管道的价值正在不断增长,能够轻松配置技术栈是一大优势。RisingWave 和 ScyllaDB 的集成可简化技术栈,使您能够专注于通过实时数据处理和分析实现价值。
资源
- 有关 RisingWave 和 ScyllaDB 的可运行集成,请查看此演示。
- 使用 RisingWave 和 ScyllaDB 进行经济高效的流处理
- ScyllaDB 文档
- RisingWave 用例
- RisingWave 文档
- 有关 RisingWave 所支持集成的完整列表,请查看此页面。
这篇关于基于 RisingWave 和 ScyllaDB 构建事件驱动应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





