本文主要是介绍mysql公用表表达式CTE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
公用表达式是MySQL8.0的新特性,它是一个命名的临时结果集,作用范围是当前语句。
可以理解成为当前sql语句定义了一个视图,sql语句的任何地方都可以使用这个视图,如果被多次使用就体现出了公用表达式的特点公用。
依据语法结构和执行方式不同,公用表达式可以分为普通公用表达式和递归公用表达式。
#公共表表达式定义语法
WITH [RECURSIVE]cte_name [(col_name [, col_name] ...)] AS (subquery)[, cte_name [(col_name [, col_name] ...)] AS (subquery)] ...
非递归公用表达式案例
提取公共表达式
select u.* from a u join b o on u.USER_ID_=o.USER_ID_ and o.XXXXX='1001'
where u.SEX_='male'
UNION
select u.* from a u join b o on u.USER_ID_=o.USER_ID_ and o.XXXXX='1001'
where u.SEX_='female'#提取公用部分组成一个公用表达式
# select u.* from a u join b o on u.USER_ID_=o.USER_ID_ and o.XXXXX='1001'with m as (##将公共查询部分提取出来作为一个临时表,后面的查询直接使用临时表即可select u.* from a u join b o on u.USER_ID_=o.USER_ID_ and o.XXXXX='1001'
)
select * from m
where SEX_='female'
UNION
select * from m
where SEX_='male'
其中为构建的公用表起名为 m。写法的优势:
1、便于我们阅读sql语句。
2、也有提升sql性能
递归公用表达式讲解
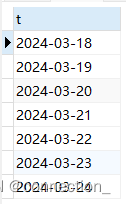
生成一周的日期,从周一到周日
with RECURSIVE m as (
select DATE('2024-03-18') t #初始数据我们很容易通过代码给出
UNION all
select DATE_ADD(t, INTERVAL 1 DAY) from m limit 7 #获取指定日期及其后面的日期,总数为7条
)
select * from m
运行结果为:
递归公用表表达式通用模板:
WITH RECURSIVE cte (n) AS
(
SELECT ... -- 通过第一条select的到初始数据集,第一个执行,且只执行一次。
UNION [ALL]
SELECT ... -- 递归select语句,不断的通过递归数据集得到递归结果集。在将此轮得到的递归结果集作为下一轮递归数据集。并且将此轮的递归结果集加入到最终的数据集中。这里将会因为union后面有没有all为导致不同。
)
SELECT * FROM cte;#比如:WITH RECURSIVE cte (n) AS
(SELECT 1UNION ALLSELECT n + 1 FROM cte WHERE n < 5
)
SELECT * FROM cte;
图解递归运行原理
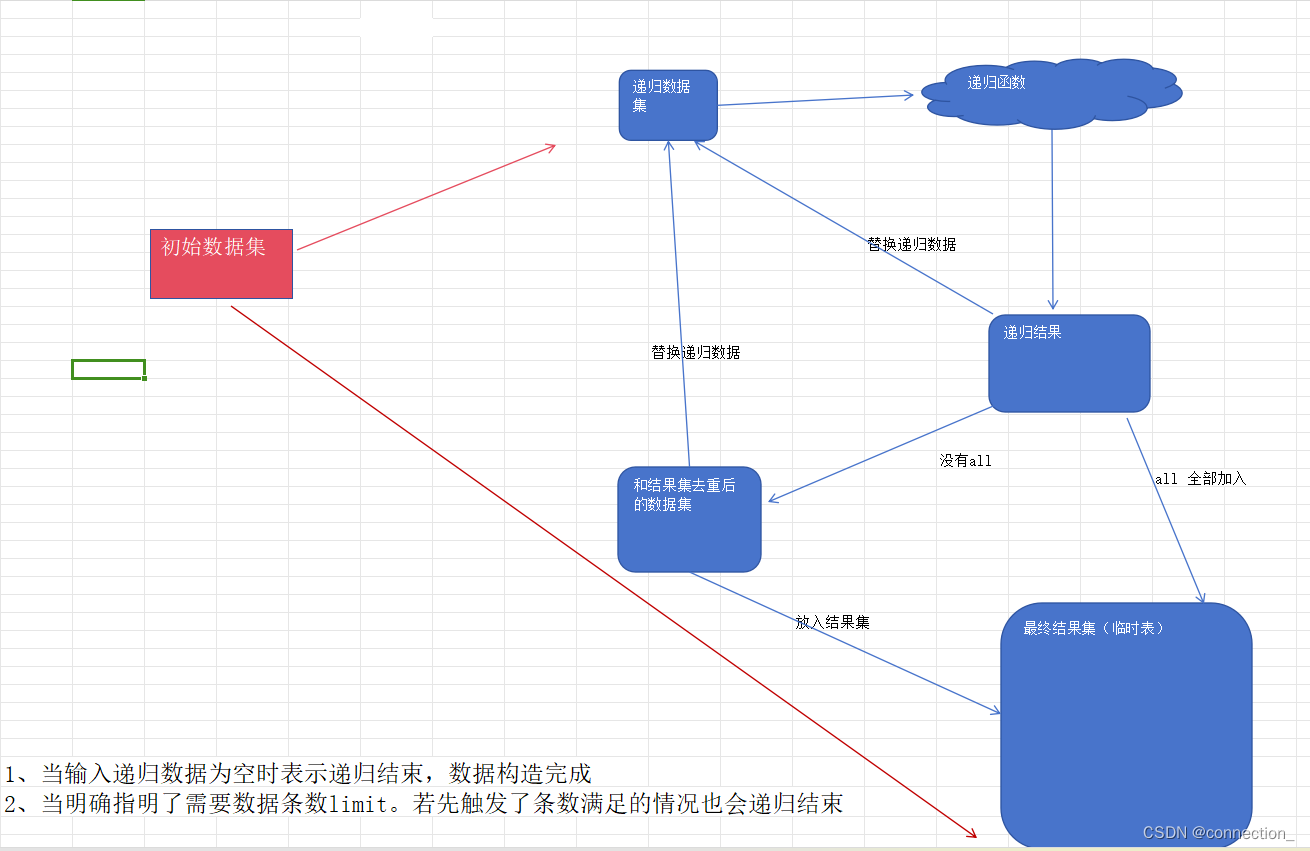
第一次递归的递归数据集来自于第一条select语句产生的数据(初始数据集)。后期每一次的递归结果集作为下一轮的递归的递归数据集(也就是只是对增量数据进行递归)。
递归停止的条件如下:
1、当输入递归数据为空时表示递归结束,数据构造完成。
2、当明确指明了需要数据条数limit。若先触发了条数满足的情况也会递归结束。
对于上图的讲解:
1、通过第一条初始select语句得到初始数据集。将初始数据集放入最终结果集中,也将初始数据集作为第一轮递归的递归数据集。
(若初始数据集为空,则触发了递归停止的第一个条件。不进行递归)。
2、递归数据集通过递归select语句(递归函数)得到递归结果集。此时需要判断UNION有没有ALL.2.1、如果没有ALL; 那么将会把此轮的递归结果集去重在和最终数据结果集去重。
比如当前递归结果集为1、1、2、3。而最终结果集为2,5,6,9。那么自身去重以及和最终结果集去重后得到的结果为1、3.那么将1、3作为本轮的递归结果集。2.2、如果有ALL就啥也不做(不需要去重)。
3、如果递归结果集有数据,则将递归结果集的数据放入最终结果集中,此时如果有限制递归数据的条数(limit),
且达到了条数则递归退出,否则将此轮的递归结果集作为下一轮的递归数据集(输入参数)准备进入下一轮的递归。 如果递归结果集为空,则退出递归。最终结果集就是我们要的公用表数据集了。
以下语句展示了有all和没有all的区别。
---以下语句有all,所以递归结果集一定有值,只能通过limit限制条数才能退出递归
with RECURSIVE m(n) as (
select 1
UNION all
select if(n=3,1,3) from m limit 200
)
select * from m ;---以下语句没有all,所以第二次递归产生的1将会被过滤掉,导致第二次递归结果为空值,第二次就导致递归退出
with RECURSIVE m(n) as (
select 1
UNION
select if(n=3,1,3) from m limit 200
)
select * from m ;
公用表表达式注意事项
公用表表达式通过非递归列进行表结构的定义(列的类型定义) 后续递归生成的数据列需要满足非递归列定义的结构
比如
WITH RECURSIVE cte AS
(SELECT 1 AS n, 'abc' AS strUNION ALLSELECT n + 1, CONCAT(str, str) FROM cte WHERE n < 3
)
SELECT * FROM cte;
###如上类似于建立了如下一张临时表:
# create table cte (
# int n ,
# char(3) str
# )
#后续递归不断进行前面的字符串叠加。 abcabc 第一次递归就导致str长度为6. 不满足上面的cte定义
###显示类型转换
WITH RECURSIVE cte AS
(SELECT 1 AS n, CAST('abc' AS char(12) ) as str UNION ALLSELECT n + 1, CONCAT(str, str) FROM cte WHERE n < 3
)
SELECT * FROM cte;
# create table cte (
# int n ,
# char(12) str
# )
这篇关于mysql公用表表达式CTE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




