本文主要是介绍GIt的原理和使用(三):分支的相关操作与分支管理策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
合并分支
删除分支
合并冲突
分支管理策略
分支策略
bug分支
删除临时分支
小结
合并分支
目的:为了在master主分支上能看到新的提交,需要将副分支合并到master分支上
指令:git merage 副分支名
功能:合并指定分支到当前分支
注意事项:
1、合并前要先让HEAD指向当前分支
2、合并完后当前分支可以看到另一个参与合并分支的内容
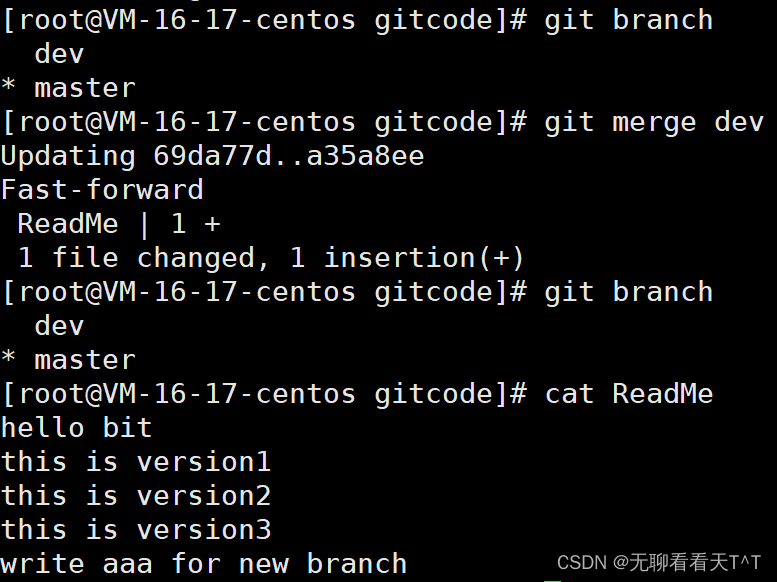

Fast-forward表示”快进模式“,即直接把master指向dev的当前的提交,合并速度很快,但不是每次合并都能Fast-forward......
删除分支
目的:合并完后的副分支就没用了(功力全被别人吸走了)可以被删除
指令:git branch -d 分支名
注意事项:
1、不能在当前分支下删除当前分支(HEAD指向谁不能删除谁)
2、可以在当前分支下删除指定分支(可以删除HEAD不指向的分支)

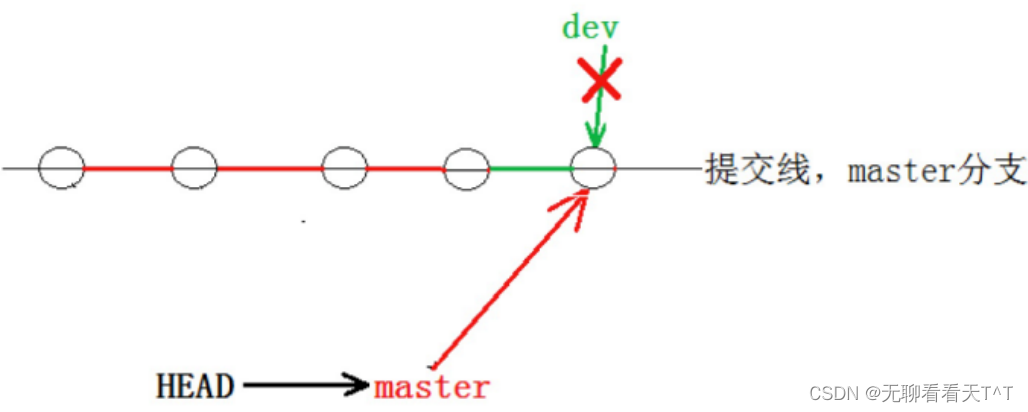
创建、合并和删除分支非常快,所以Git支持使用分支完成某个任务,合并后再删除掉分支,这和直接在master分支上工作效果是一样的,但是会更安全
合并冲突
问题:合并分支时不是想合并就能合并成功的,有时可能会遇到代码冲突问题4
指令:git checkout -b 分支名
功能:创建该分支并令HEAD指向该分支
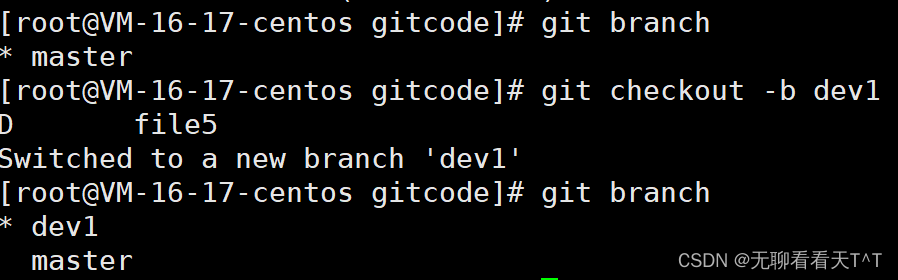
在dev1分支下修改R并提交ReadMe文件:

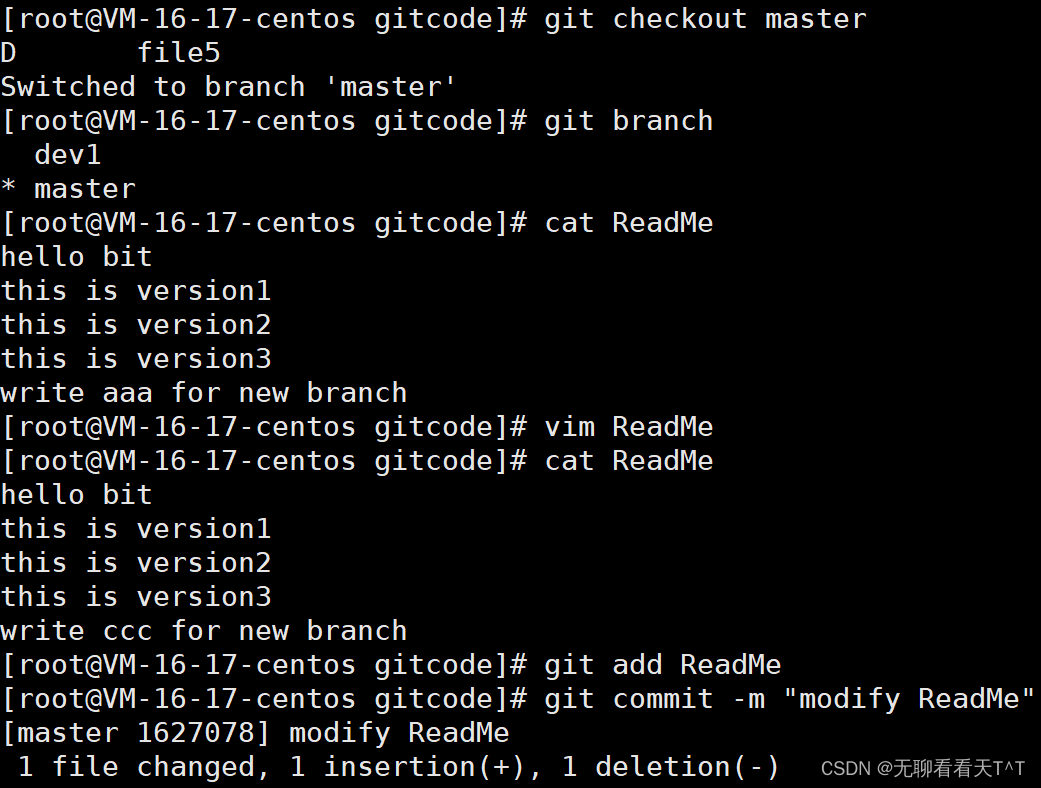
切换回master,在master中修改并提交ReadMe文件:
尝试将dev1分支与当前工作分支合并,系统会提示文件合并冲突(网易有道云翻译~):
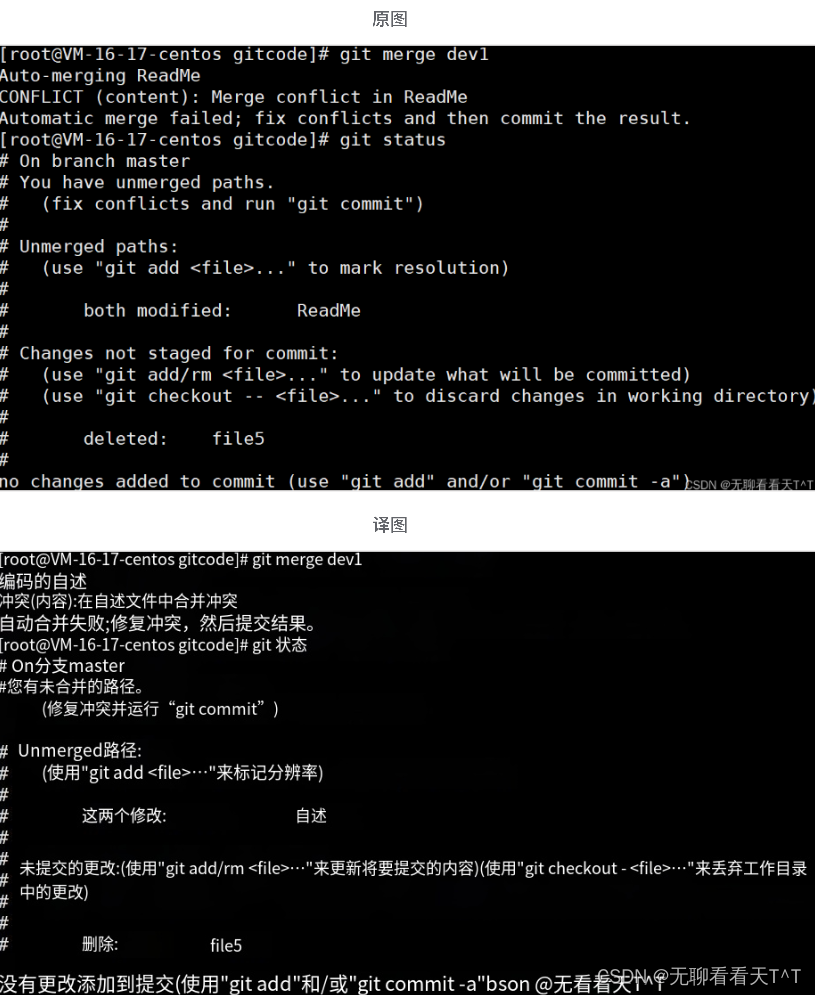
发现ReadMe文件有冲突后,可以直接查看文件内容,Git会使用<<<<<<<,=======,>>>>>>>来标记出不同分支的冲突内容:

此时需要我们手动调整冲突代码,并再次提交修正后的结果:

此时的状态就变成了:
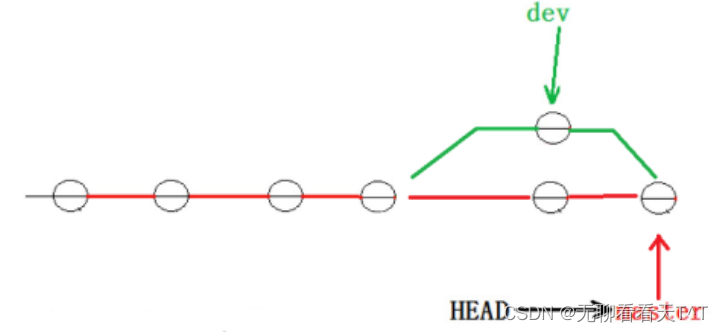
使用带参数的git log也可以查看代码演示的分支的合并情况:

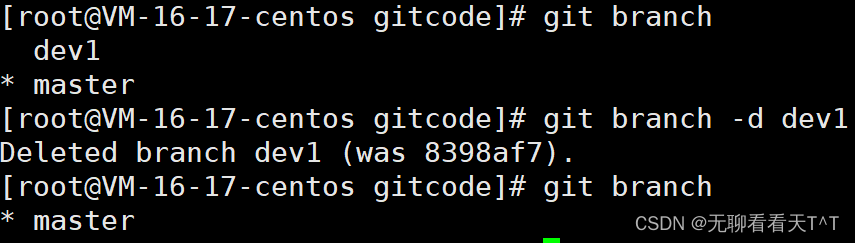
合并后记得删除dev1分支:
分支管理策略
问题:通常合并时Git会采用Fast forword模式,但是该模式合并后会导致在删除分支后丢掉相关的分支信息(看不出来最新提交的是merge得到的还是主分支提交的)

但在解决合并冲突问题中,我们通过修改文件并再次提交的方式使得原来的分支信息得以保留(即使最后也删除了分支):
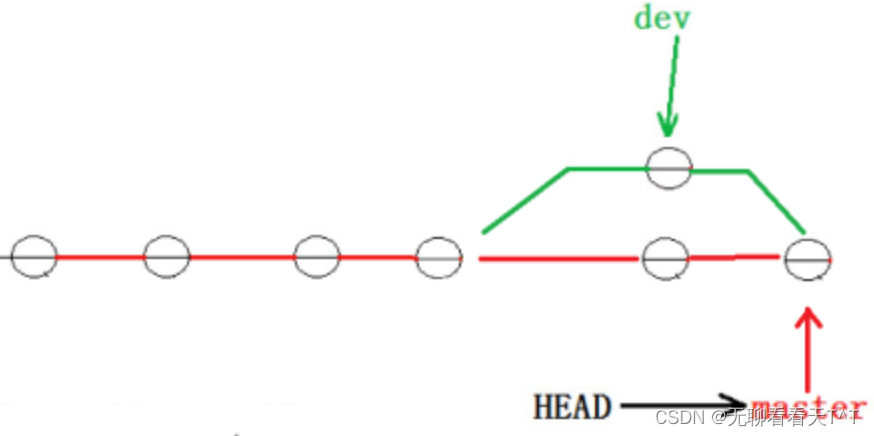
但这就不是Fast forward模式了, 这样的好处是从分支历史上就可以看出分支信息,例如我们在删除了在合并冲突部分创建的dev1分支,但依然能看到master其实是由其它分支合并得到的:
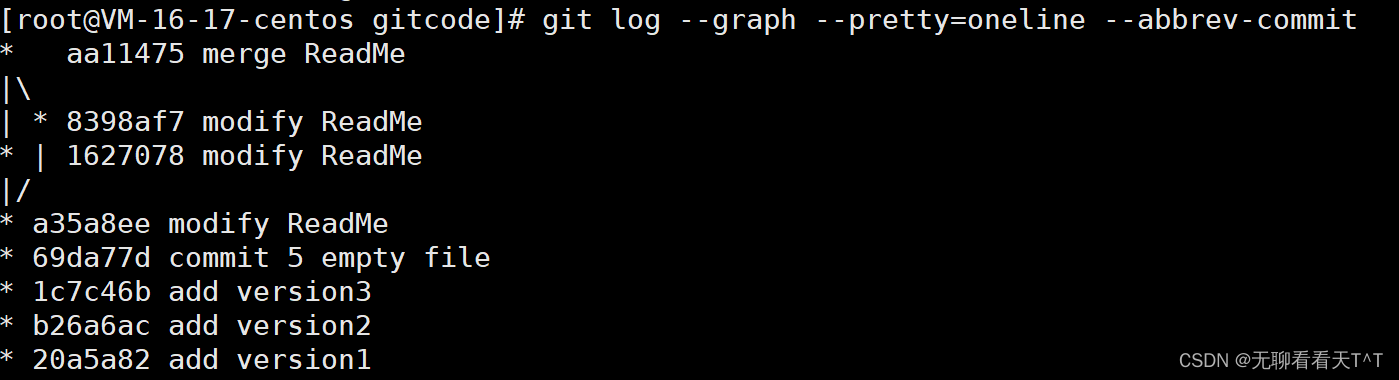
Git支持我们强制禁用Fast forward模式,那么就会在merge时生成一个新的commit,这样从历史分支上就可以看出分支信息:
禁用Fast forward模式指令:--no-ff
1、创建并切换至新分支dev2,同时修改并提交ReadMe文件:

2、切换回master分支并合并:
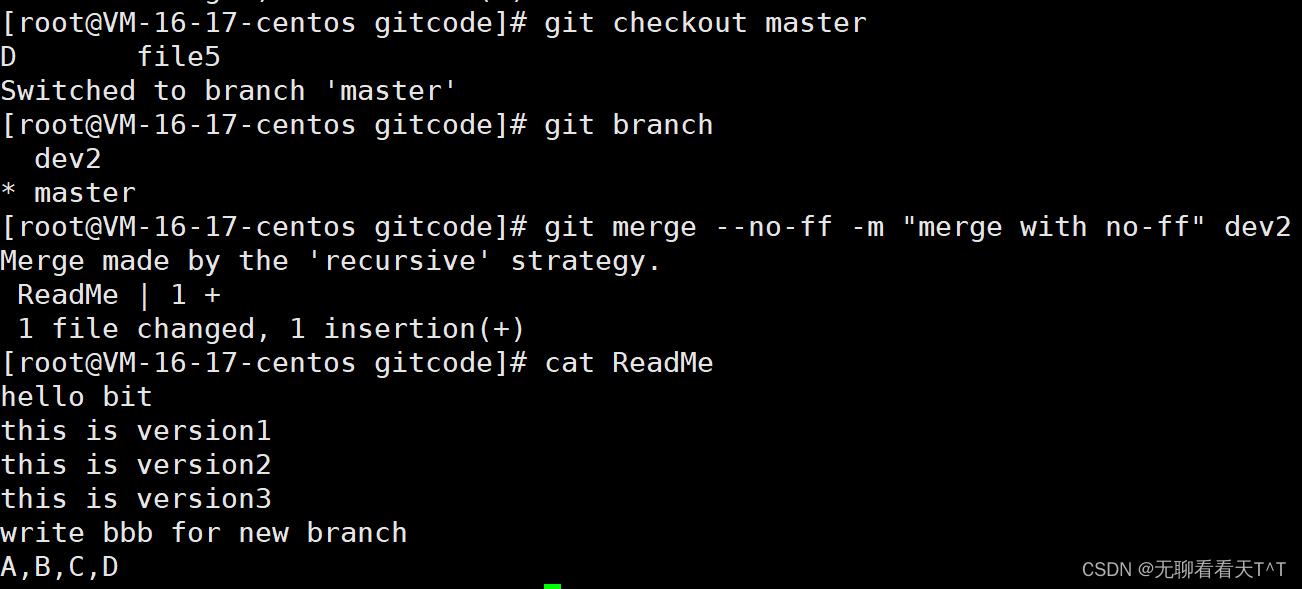
3、--no-ff参数表示禁用Fast forward模式,在禁用该模式后合并会创建一个新的commit,所以要加上-m参数与相关描述,合并后查看分支历史:
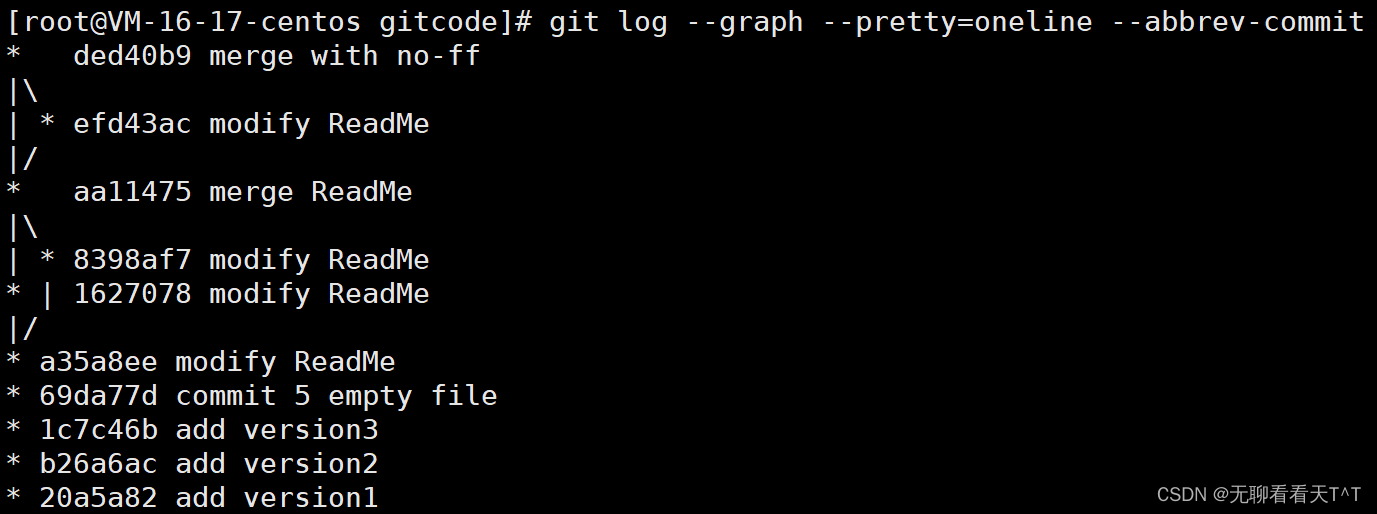
4、可以看到不使用Fast forward模式merge后就会变成这样:
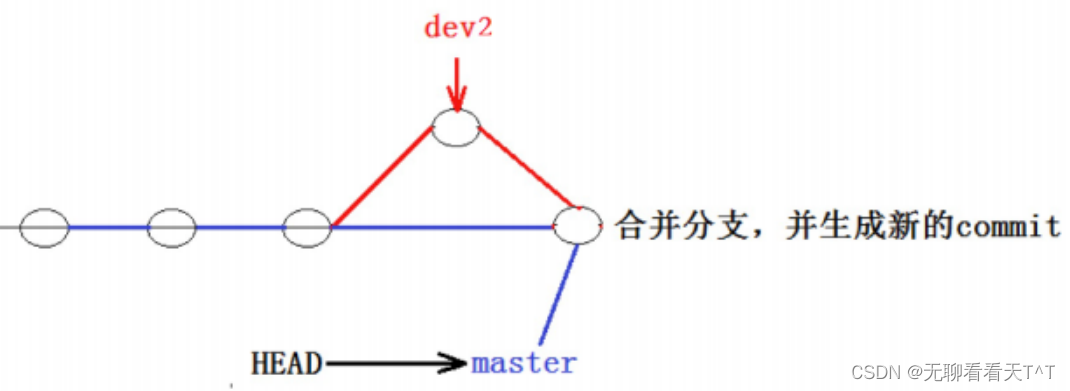
结论:在合并分支时叫上--no-ff参数就可以用普通模式合并,合并后的历史有分支,能看出来曾经做过合并,而Fast forward模式就看不出来曾经做过合并
分支策略
在实际开发中,我们应该按照几个基本原则进行分支管理:
- master分支应该是十分稳定的,即仅用来发布新版本,不能在上面干活
- 干活都在dev分支上,即dev分支是不稳定的,到某个版本时,再把dev分支合并到master上,在master分支发布1.0版本
在实际开发中每个程序员都在dev分支上干活,且每个人都有自己的分支,时不时将自己的内容向dev分支上合并即可:
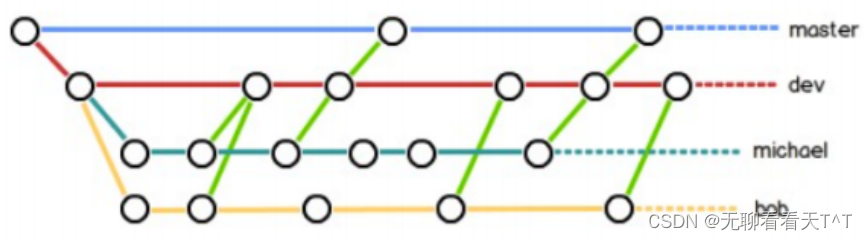
bug分支
问题1:加入我们在dev2分支上进行开发,开发到一半发现master分支上面有bug需要解决
解决办法:在Git中,每个bug都可以通过一个新的临时分支来修复,修复后合并分支,最后将临时分支删除
问题2:可现在dev2的代码在工作区中开发了一半,还无法提交,怎么办?
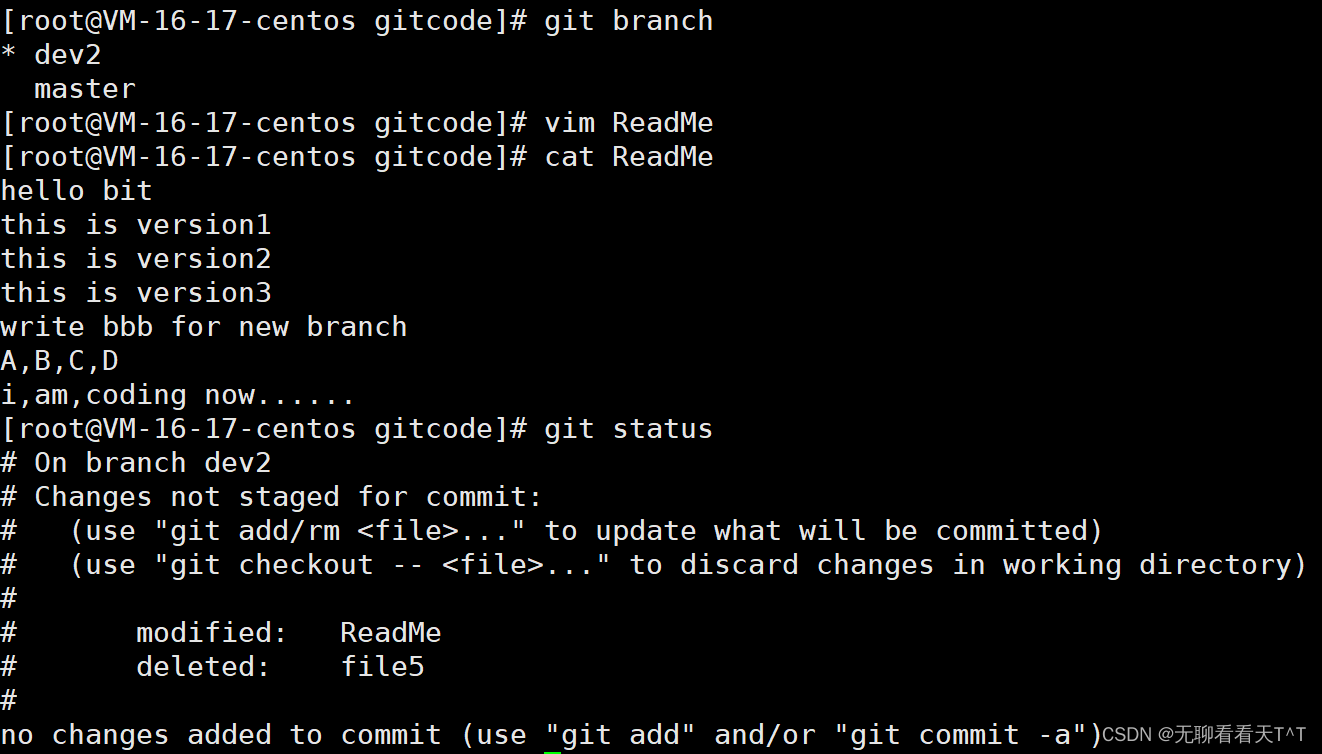
指令:git stash
功能:存储当前工作区信息,被存储的内容可以在将来某个时间恢复

此时再查看工作区,工作区就是干净的(除非有没有被Git管理的文件)因此可以放心的创建分支来修复bug
储藏dev2工作区后,由于我们要在master分支上修复bug,所以要切回master分支并创建临时分支来修复bug(ABCD后忘记写E):
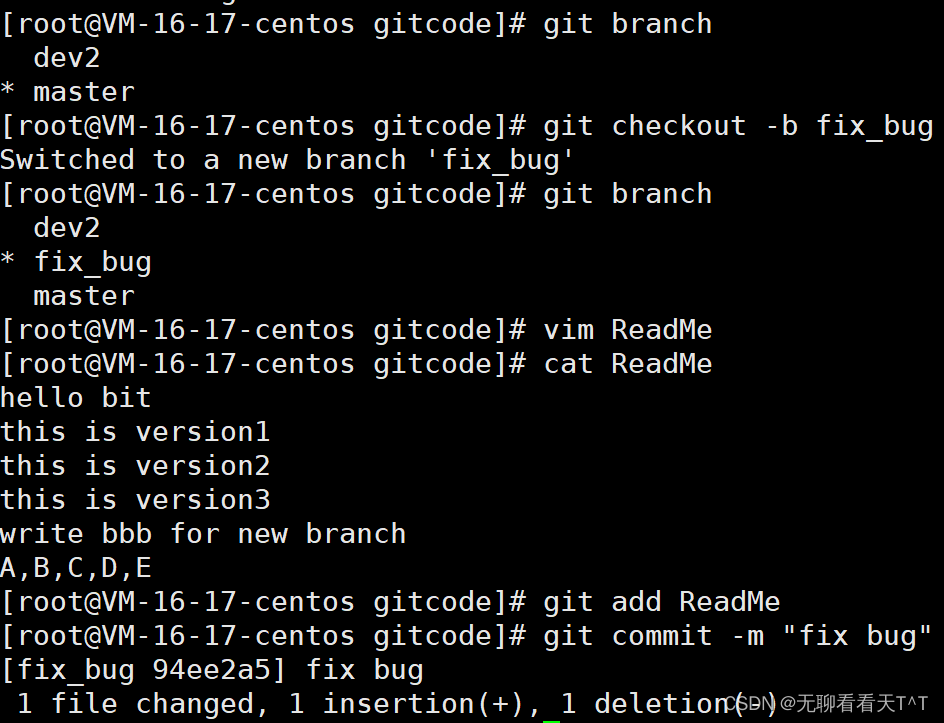
修复完后,切换到master分支,合并并删除fix_bug分支:

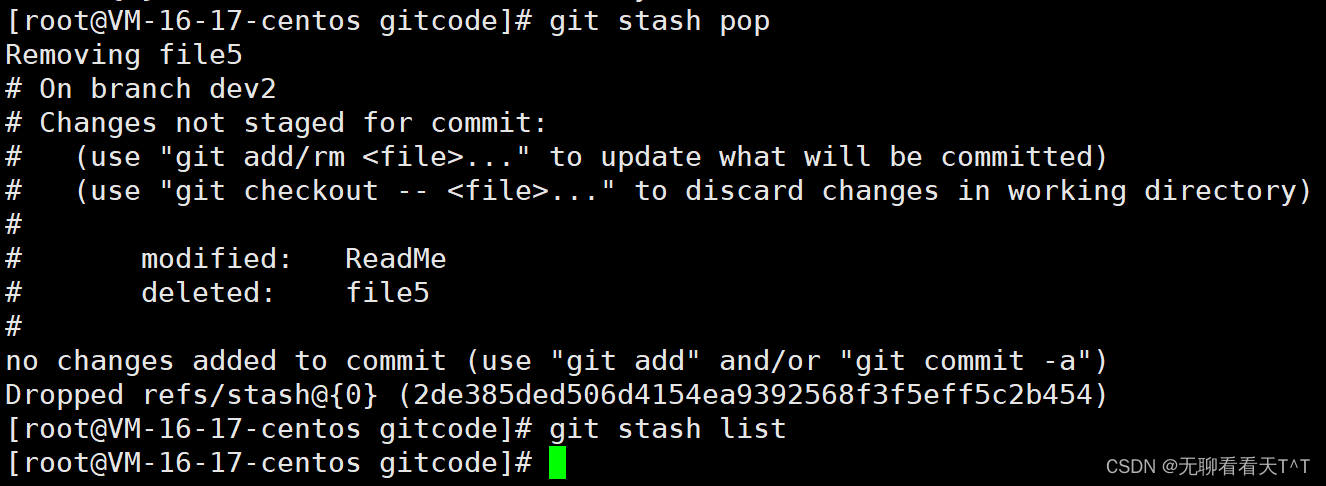
回到dev2分支继续开发,但此时工作区的内容为空,可以用git stash list查看它存在哪儿:
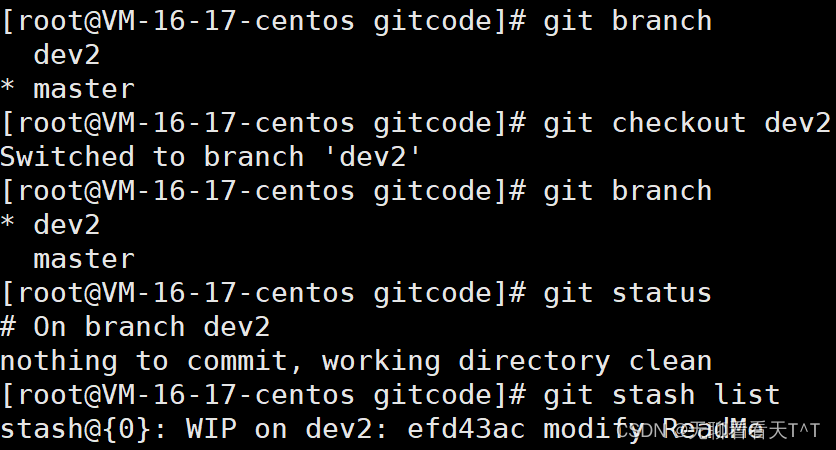
使用git stash pop指令将存储的工作区内容恢复,同时删除存储空间:
stash{0}就像一个队列,pop出队列
如果不想在恢复的同时删除临时存储空间,可以使用git stash apply指令,如果后来又想删除临时存储空间了可以使用git stash drop指令,可以多次stash,恢复的时候先用git stash list查看,然后恢复指定的stash,用命令git stash apply stash{?}指令
恢复完代码后可以继续开发与提交,但是此时修复bug的内容并未在dev2上显示,此时的状态为
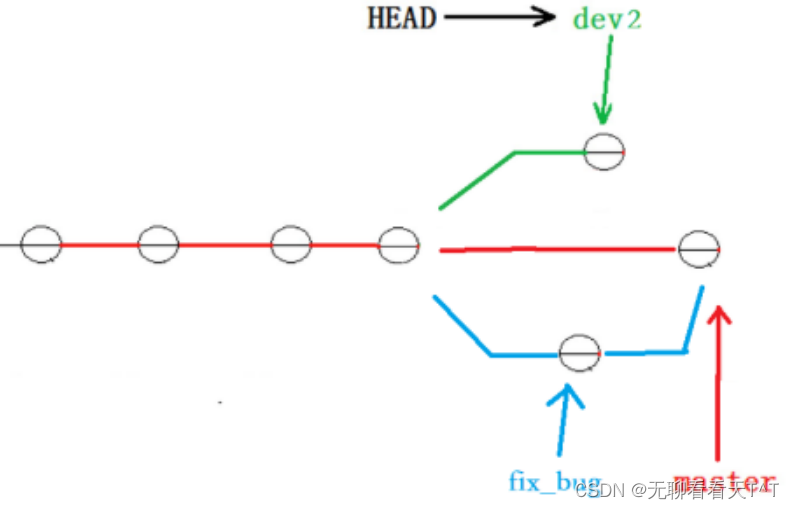
master分支目前最新的提交是要领先于创建dev2时基于的master分支的提交的,所以我们在dev2的中看不见修复bug的相关代码,我们的最终目的时要让master合并dev2分支,如果我们直接切换至master分支进行合并会有合并冲突问题,冲突代码需要手动在master上更改,但即使是这样我们也没办法保证一次性正确的解决完冲突问题,因为在实际开发代码中,代码冲突不是一两行那么简单,上百行代码在更改的过程中难免手误出错,导致错误的代码被合并到master上:

解决这一问题的一个好办法是:在自己的分支上合并下master,再让master区域合并dev2,这样做可以在本地分支解决冲突问题并进行测试,而不影响master:
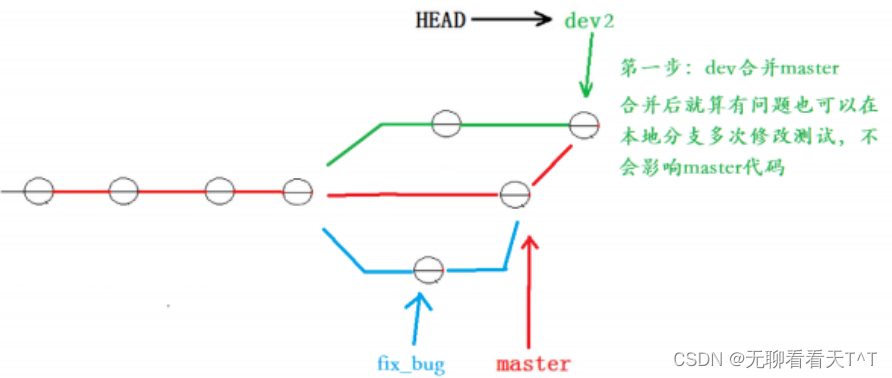
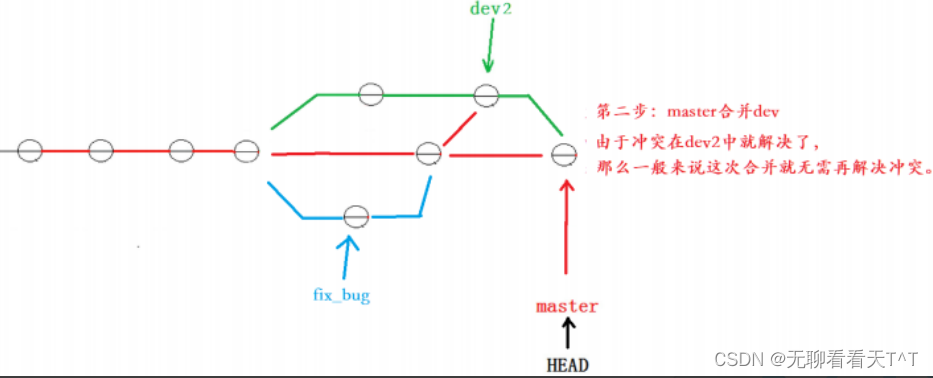
上述图中是禁用Fast forward模式后得到的,下面的实操没有禁用该模式
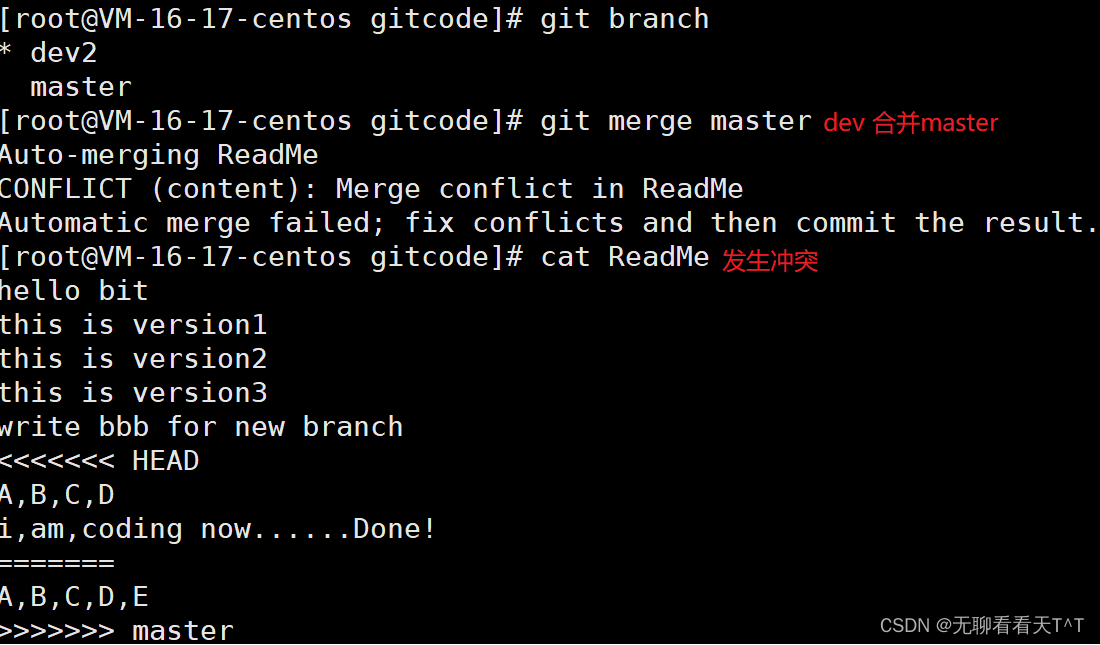

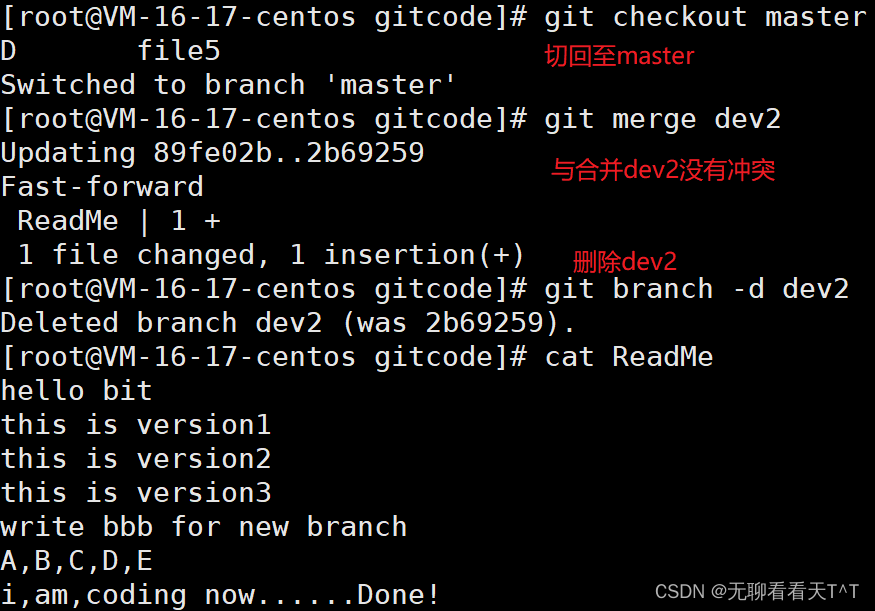
删除临时分支
问题:软件开发中,总有很多新的功能要不断的添加进来,添加一个新功能时,肯定不希望因为一些实验性质的代码把主分支搞乱了,所以,每添加一个新功能,最号新建一个feature分支,在该分支上开发完成后,合并并删除该分支,可是如果我们在某个feature分支上开发一半突然被叫停说要停止新功能开发,虽然白干但是这个feature分支还是要就地销毁,这时传统的git branch -d命令删除分支的办法是不行的,需要使用git branch -D命令:
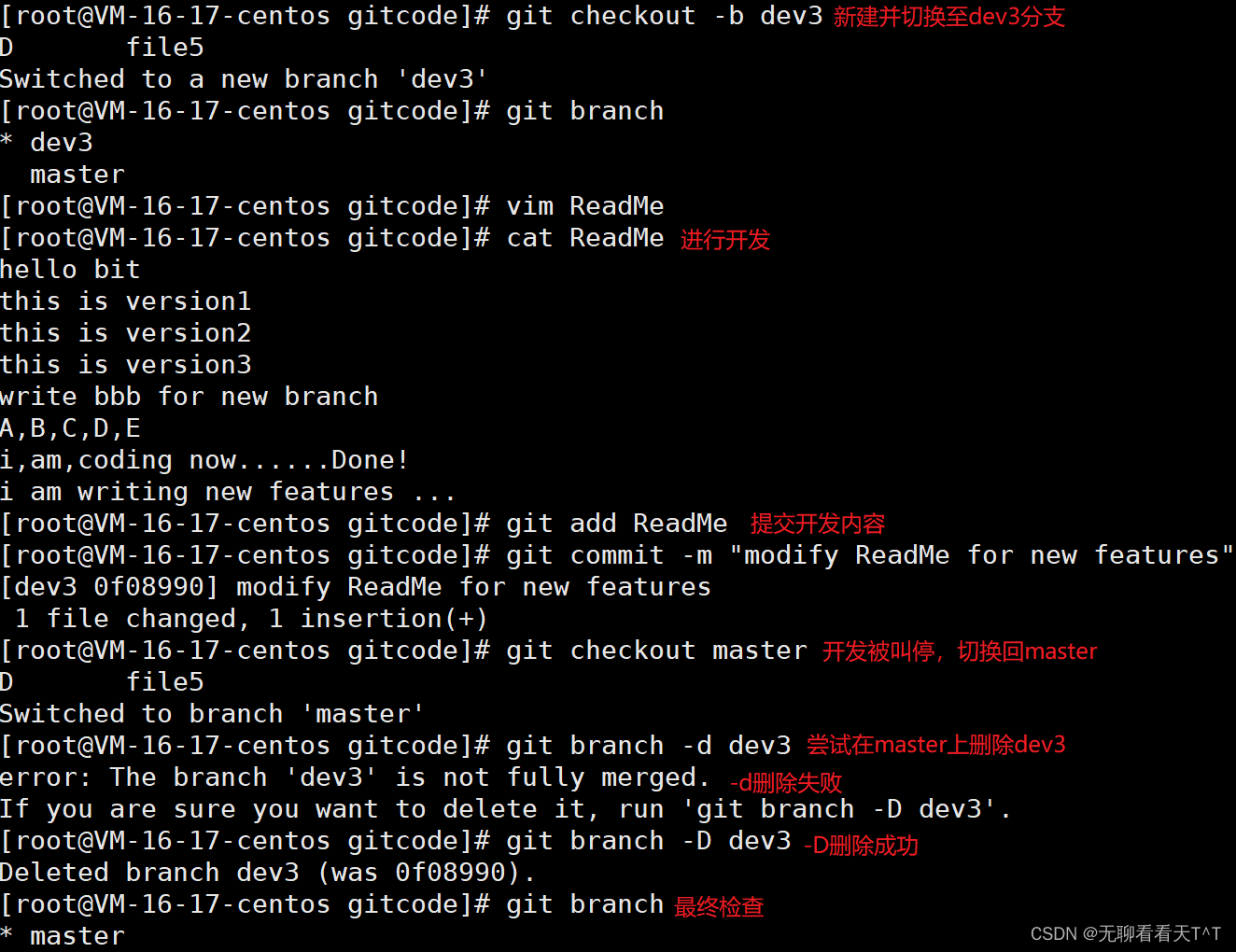
小结
分⽀在实际中有什么⽤呢?假设你准备开发⼀个新功能,但是需要两周才能完成,第⼀周你写了50% 的代码,如果⽴刻提交,由于代码还没写完,不完整的代码库会导致别⼈不能⼲活了。如果等代码全 部写完再⼀次提交,⼜存在丢失每天进度的巨⼤⻛险有了分⽀,就不⽤怕了。你创建了⼀个属于你⾃⼰的分⽀,别⼈看不到,还继续在原来的分上正常⼯作,⽽你在⾃⼰的分⽀上⼲活,想提交就提交,直到开发完毕后,再⼀次性合并到原来的分⽀上,这样,既安全,⼜不影响别⼈⼯作。 并且 Git ⽆论创建、切换和删除分⽀,Git在1秒钟之内就能完成!⽆论你的版本库是1个⽂件还是1万个⽂件
~over~
这篇关于GIt的原理和使用(三):分支的相关操作与分支管理策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



