本文主要是介绍bpf,ebpf,libbpf,libbpf_bootstarp概念介绍(如何安装libbpf_bootstarp库),以及四者关系,ebpf程序执行流程(代码分层,具体如何编译,后续操作,关系总结),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概念介绍
bpf
编辑
ebpf
eBPF 虚拟机
libbpf
libbpf-bootstrap
如何安装
源码目录
ebpf, libbpf 和libbpf-bootstrap之间的关系
ebfp程序数据流程
介绍
代码
用户层函数
编译
查看
生成内核层的.o文件
第一模块
第二模块
第三模块
第四模块
第五模块
生成辅助文件(.skel.h)
生成代码层的.o文件
第一模块
第二模块
第三模块
链接出可执行文件
后续+总结
本文参考哔哩哔哩up主"张口就问"发布的ebpf的学习视频,感谢大佬
概念介绍
bpf

ebpf
- 它提供了一个功能强大的虚拟机,在内核中执行用户定义的程序
- 通过 eBPF,用户可以编写并在内核中动态加载运行自定义的程序,而无需修改/重新编译内核源代码,从而实现了一种灵活而安全的内核扩展方式
eBPF 虚拟机
- 用户编写的 eBPF 程序以字节码的形式加载到内核中,并由 eBPF 虚拟机执行
- 通过特定的用户态工具或接口,将eBPF程序加载到内核中的特定区域,并在不再需要时将其从内核中移除
- 我理解的他们之间的关系也许是:
- 这样各是各的,互不影响


libbpf
对bpf syscall(系统调用) 做出了基础封装,提供了 open, load, attach, maps操作, CO-RE等功能





libbpf-bootstrap
基于 libbpf 开发出来的eBPF内核层代码,通过bpftool工具直接生成用户层代码操作接口,极大减少开发人员的工作量
如何安装
首先需要linux环境+11版本及以上的clang编译器
- 最好使用ubuntu环境,centos提供的软件包版本太低了
- ubuntu可以指定安装clang版本(注意更新一下软件包,但默认还是下载的clang10),但centos好像需要自己下载源码编译
然后根据libbpf-bootstrap 开发指南:概念与如何安装-CSDN博客进行环境搭建即可
源码目录

ebpf, libbpf 和libbpf-bootstrap之间的关系
类似于在c语言中的系统调用,c库,第三方库之间的关系
- ebpf 提供底层接口,让用户程序可以在内核中动态执行
- 而libbpf 是用户态的c库,它对ebpf程序的接口和函数进行了封装,减少了我们的使用成本
- libbpf-bootstrap 是一个辅助工具和示例代码集合,他是使用者自己开发的一种工具,帮助我们更好地使用libbpf
ebfp程序数据流程
介绍

代码
ebpf代码一般分为两个部分,用户层代码(.c)和内核层代码(.bpf.c)
- 内核层代码:跑在内核层,负责实现真正的eBPF功能(也就是核心功能代码)
- 用户层代码:跑在用户层,负责 open, load, attach eBPF内核层代码到内核,并负责用户层和内核层的数据交互
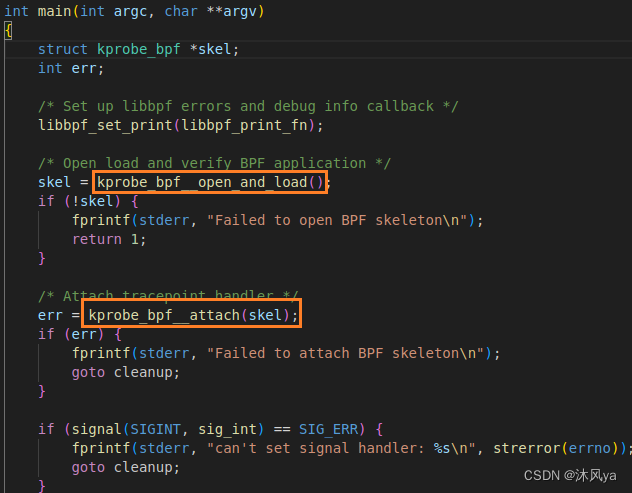
用户层函数
- 注意,在用户层写的代码中,我们使用的核心函数其实是经过了进一步封装的:
- 他们的函数名第一个都是程序名,这么自定义的行为说明底层绝对是调用了其他函数,但我们在使用时并不需要关心,因为肯定是库自发性的行为
- (当然啦,学习的时候还是要懂原理的,将在下面的编译里介绍)
编译
查看
我们可以通过现成的makefile来查看编译时的具体语句:
make kprobe V=1

生成内核层的.o文件
我们先看生成了内核层的.o文件的编译语句:
clang -g -O2 -target bpf -D__TARGET_ARCH_x86 -I.output -I../../libbpf/include/uapi -I../../vmlinux/x86/ -I/libbpf-bootstrap/blazesym/capi/include -idirafter /usr/local/include -idirafter /usr/lib/llvm-11/lib/clang/11.0.0/include -idirafter /usr/include/x86_64-linux-gnu -idirafter /usr/include -c kprobe.bpf.c -o .output/kprobe.tmp.bpf.o/libbpf-bootstrap/examples/c/.output/bpftool/bootstrap/bpftool gen object .output/kprobe.bpf.o .output/kprobe.tmp.bpf.o我们把这里的编译语句分为五部分:
第一模块
基本信息+功能选项
第二模块
添加libbpf-bootstrap库中的文件到搜索路径中
第三模块
添加系统库文件到搜索路径中
- -I和-idirafter的区别:
第四模块
指定要生成的目标文件
第五模块
使用bptool工具生成两份bpf.o文件(编译成 eBPF 字节码,字节码用elf格式存储)
- 一份用于生成辅助文件,以及加载到内核中
- 一份备份文件
- (根据实际语句理解的,应该是这样)






生成辅助文件(.skel.h)
/libbpf-bootstrap/examples/c/.output/bpftool/bootstrap/bpftool gen skeleton .output/kprobe.bpf.o > .output/kprobe.skel.h
还记得前面说的,用户层使用的函数其实是再次经过封装的吗?
- 是由bpftool工具自动帮我们根据.bpf.o来生成.skel.h头文件的
- 根据实际要在内核中执行的功能,根据执行过程需要的函数,生成一份用户层和内核层的中间文件
- 它提供了用户层的接口,并且自动在里面封装出可以执行内核层代码的代码
- 官方一点就是它里面包含了.bpf.c 对应的elf文件数据,以及用户层需要的 open, load, attach 等接口
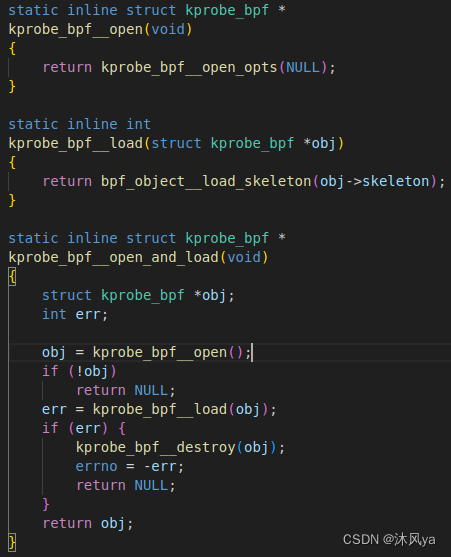
- 就像这样,他帮我们自动生成用户层接口,并在里面调用所需的libbpf中的函数,并进行一定处理:
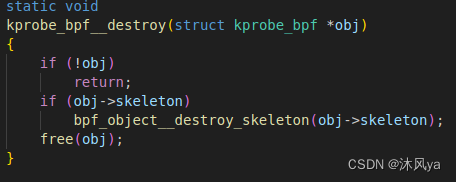
- 这个更是如此,甚至将两个函数合在一块,方便我们使用:
- 如果追根溯源的话,更能体现它会根据内核层代码,建立中间要使用的数据结构,生成中间代码,生成用户层接口:
- 让我们一起说,谢谢它!!!

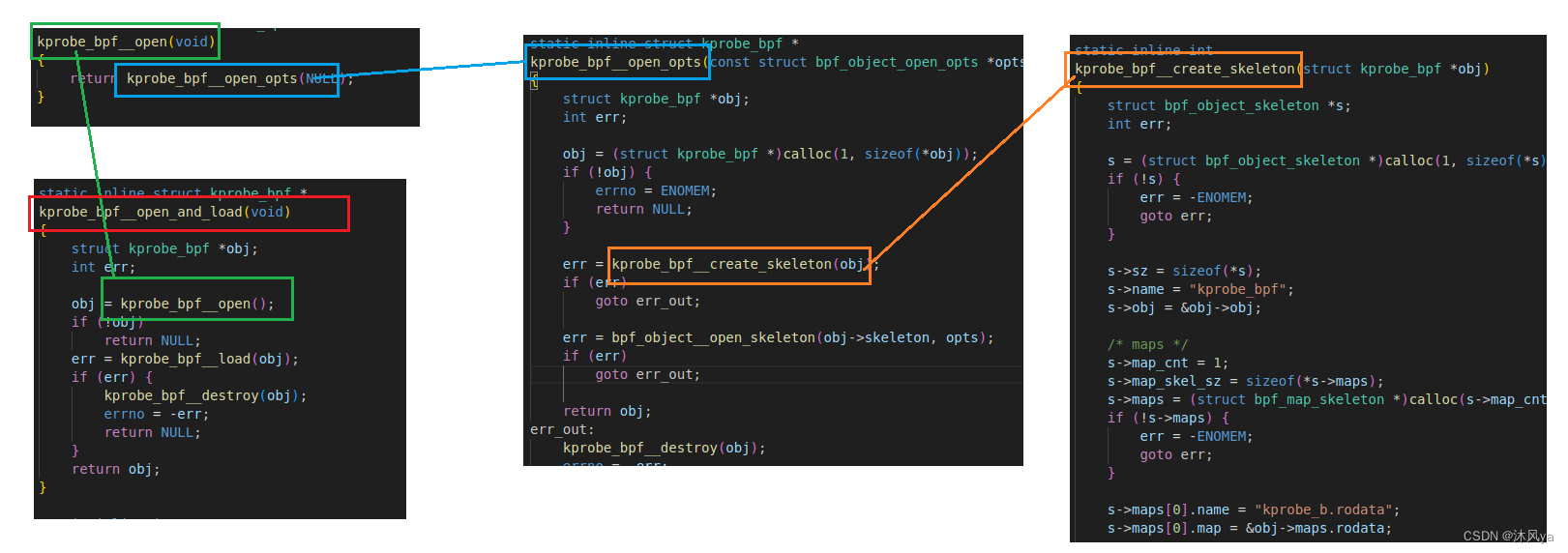
生成代码层的.o文件
cc -g -Wall -I.output -I../../libbpf/include/uapi -I../../vmlinux/x86/ -I/libbpf-bootstrap/blazesym/capi/include -c kprobe.c -o .output/kprobe.o和内核层的类似,我们可以把它分成三部分:
第一模块
普通选项
第二模块
添加搜索路径
- 添加.output是因为,有生成的.skel.h头文件在那个目录下
- 我们必须加上实际的库函数,才能编译成功
第三模块
指定目标文件名



链接出可执行文件
cc -g -Wall .output/kprobe.o /libbpf-bootstrap/examples/c/.output/libbpf.a -lelf -lz -o kprobe

后续+总结
可以看到,用户层代码.o文件+库文件最终链接出了可执行文件
那.bpf.o呢?
我是这么理解的 :
用户层代码用于管理ebpf程序的执行(启动啦,挂接啦,销毁啦等等)
而内核层代码只负责编写挂接后的操作(或者说核心操作),然后被加载到内核中,等待被触发:
- 可以看到,在libbpf库中,提供了一系列函数,用于将ebpf码传进系统调用函数中
- 也就说,.bpf.o并不在可执行文件里,而是被加载进了内核里,由可执行文件远程控制它的生命周期
- 然后就等待其被触发
并且经过一系列安全检查,保证这份程序被加载进内核前是安全的:
- 这个安全检查是利用了ebpf的特性编写的
- 在进入vts_write函数之前,先进行数组检查
- 如果越界,内核就可以在实际执行之前拒绝它


总之,它形成了一系列的关系:
内核层代码 -> ebpf码 -> 加载进内核中(用户空间程序调用系统调用,将ebpf码作为参数传入)
-> elf.h头文件 -> 提供用户层接口 -> 控制ebpf程序的执行流程
这篇关于bpf,ebpf,libbpf,libbpf_bootstarp概念介绍(如何安装libbpf_bootstarp库),以及四者关系,ebpf程序执行流程(代码分层,具体如何编译,后续操作,关系总结)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





