本文主要是介绍搞了一个半小时,终于可以自由获取Excel版财务报表啦~,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近来看了一些讲财务报表分析的书,自己也想趁热打铁练习练习,毕竟光说不练假把式嘛。于是首要任务便是下载上市公司的财报数据,自己以前也下载过,估计不会有什么麻烦,没想到做起来却犯了难。
首先,财报下载主要有2个途径:
1、专业数据库下载。比如国泰安、Wind数据库、Choice数据库等。
优点:数据完整,准确度较高。
缺点:收费。
2、财经网站下载(可能需要爬虫)。比如新浪财经、东方财富网。(网易财经以前可以,现在已经停止相关服务)
优点:免费。
缺点:需要手动搜集整理数据,甚至需要用网络爬虫,对技术有一定要求。
可见,两种途径优劣互补。但作为动手能力强的白嫖党,肯定毫不犹豫地选择第2种啦。(好吧我承认还是因为穷……)
一、分析思路
打开新浪财经网页,随便输入一支股票(这里以汤臣倍健为例),然后进入它的财务报表页面,发现它已经详细展示了历年资产负债表、利润表和现金流量表数据,摆出了一副渴望被爬取的架势。
网址:汤臣倍健(300146)财务摘要_新浪财经_新浪网 (sina.com.cn)
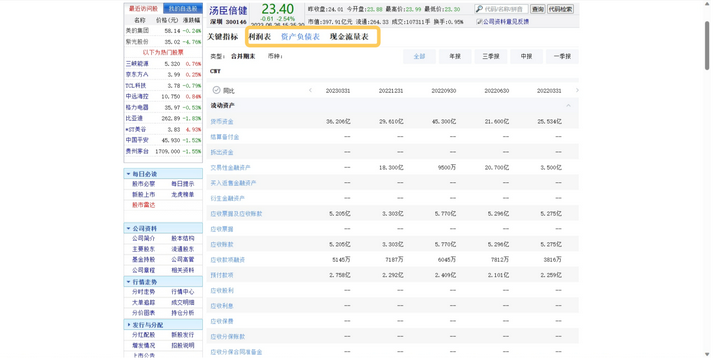
页面上,我们可以在不同报表间切换,也可以点击切换“年报”“中报”其他类型。切换后地址栏URL没有变化,显然是使用了动态网页技术,我们需要通过浏览器的“检查”→“网络”来捕获实际访问的地址。
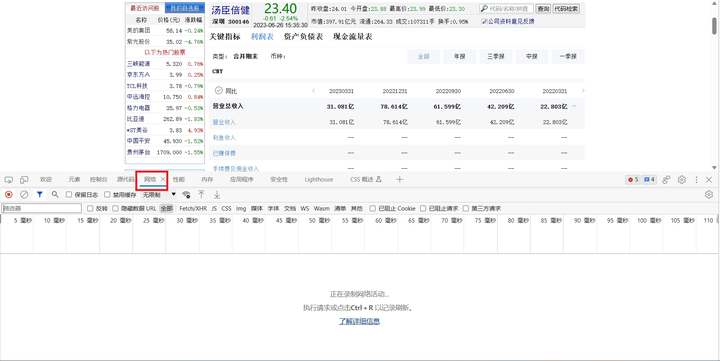
稍加尝试,我们便捕捉到了动态页面加载时实际访问的URL:
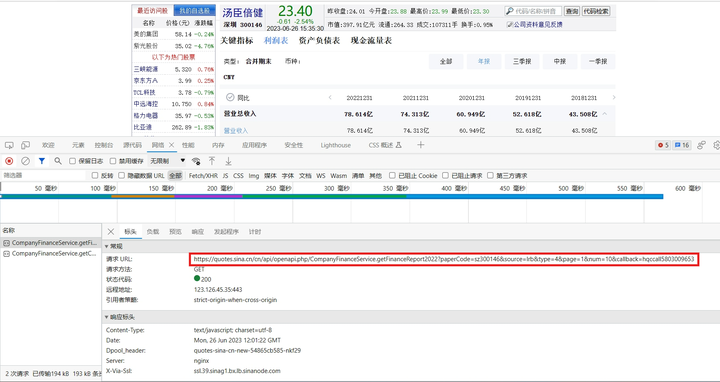
经过测试,我们发现网址中的callback参数可以去除,不影响返回的数据结果,于是我们得到了所真正需要的URL:
资产负债表:https://quotes.sina.cn/cn/api/openapi.php/CompanyFinanceService.getFinanceReport2022?paperCode=sz300146&source=fzb&type=4&page=1&num=10
利润表:https://quotes.sina.cn/cn/api/openapi.php/CompanyFinanceService.getFinanceReport2022?paperCode=sz300146&source=lrb&type=4&page=1&num=10
现金流量表:https://quotes.sina.cn/cn/api/openapi.php/CompanyFinanceService.getFinanceReport2022?paperCode=sz300146&source=llb&type=4&page=1&num=10
在浏览器中打开上面三个链接,发现返回的都是json数据:

我们要的年度财务报表数据就嵌套在json数据的一个又一个字典中,并且里面的汉字使用了Unicode编码,好在我们可以使用强大的Python和它的json库,能够轻松地把我们要的数据提取出来。
二、代码实现
分析完思路,明确了我们要访问的URL和要解析的数据,接下来就可以尝试着用Python代码实现啦,毕竟人生苦短,请用Python~~代码整体的结构就是:
1、访问URL获取数据
2、用json库解析数据
3、保存数据并输出为Excel文件
话不多说,为老铁们送上热乎的代码:
import requests
import time
import json
import pandas as pdstart_year = '2022'
market = 'sz' # sz代表深交所,sh代表上交所
code = '300146'
sheets = ['fzb','lrb','llb']
tp = '4' # 0:全部,1:一季报,2:半年报,3:三季报,4:年报
page = '1'
num = '10'hds = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134'
}for sheet in sheets:com_url = 'https://quotes.sina.cn/cn/api/openapi.php/CompanyFinanceService.getFinanceReport' + start_year + '?paperCode=' + market + code + '&source=' + sheet + '&type=' + tp + '&page=' + page + '&num=' + numr = requests.get(com_url, headers = hds)rtext = r.textjson_data = json.loads(rtext)projects = []; i = 0; result_dict = dict()for year in range(int(start_year), int(start_year) - int(num), -1):year_data = json_data['result']['data']['report_list'][str(year) + '1231']['data']i = i + 1; year_result = []if i == 1:for dct in year_data:projects.append(dct['item_title'])result_dict['报表项目'] = projectsfor dct in year_data:if str(dct['item_value']) == 'None':year_result.append(0)elif dct['item_value'] == '':year_result.append('')else:year_result.append(float(dct['item_value']))result_dict[str(year) + '年'] = year_resulttime.sleep(1)sheet_data = pd.DataFrame(data = result_dict)sheet_data.to_excel(code + ' ' + sheet + '.xlsx',index = False)print(code + ' ' + sheet + ' 数据已保存')上述代码要求安装了requests和pandas库,小伙伴们可以自己复制粘贴代码运行一下,有什么问题可以评论区留言。
运行完毕后,就会生成三个Excel文件,即我们心心念念的资产负债表、利润表、现金流量表。
三、结果展示
大家看看结果吧,是不是自己想要的那样呢。
资产负债表:
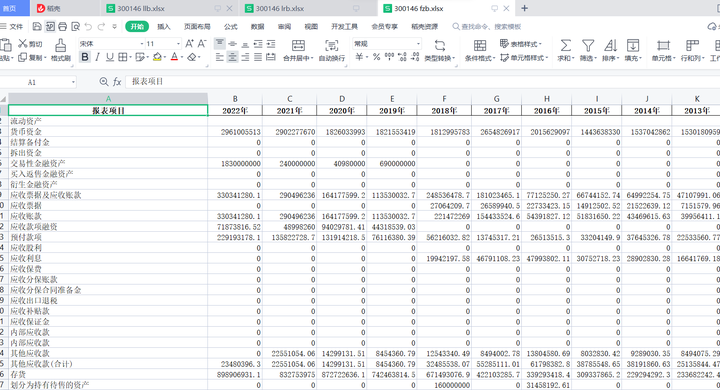
利润表:
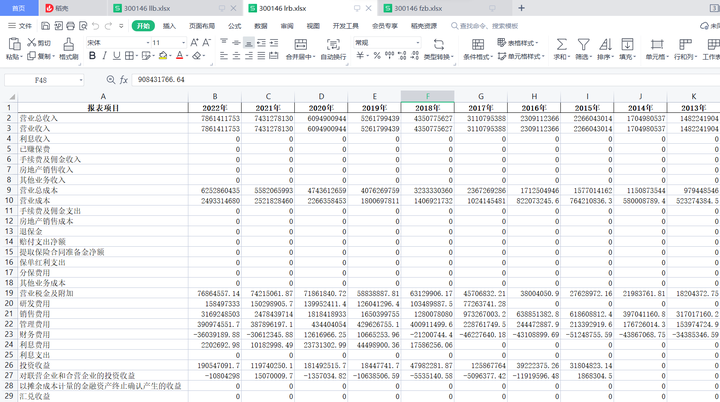
现金流量表:
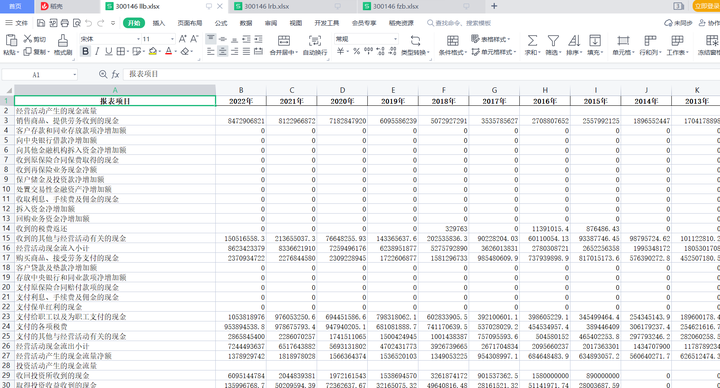
以上搞完大概花了一个半小时,虽然有点小累,但成就感满满。作为财务人士,以后可以自由下载想要的财报啦。
老铁们懂Python的,可以自己改改代码,批量爬取数据。当然控制好节奏哈,新浪的反爬虫还是挺猛的。
小伙伴们还有什么问题,欢迎评论区留言哦。
这篇关于搞了一个半小时,终于可以自由获取Excel版财务报表啦~的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






